With the recent release of Grok 4, supposedly the most intelligent AI model, there's a significant question about how well this model performs in coding specifically and whether it surpasses the best model we have, the Claude 4 Opus and Gemini 2.5 Pro. I didn't include O3 as it's the weakest in coding. Check that out here: Opus 4 vs. Gemini 2.5 Pro vs OpenAI o3
In this post, we'll test which model excels in coding. We’ll test it first in a real-world scenario and then complete a quick animation test.
So, without any further ado, let's jump straight in!
TL;DR
If you've somewhere else to be, here's the summary
Surprisingly, Grok 4 didn’t feel much better than Claude Opus 4 for coding tasks.
It’s definitely better than Gemini 2.5 Pro, no question there.
At times, Claude 4 Opus actually outperformed Grok 4. Opus 4 is a more tasteful coder.
That said, Grok 4 isn’t bad at all; it’s an excellent model overall, just not the best for coding. On reasoning and planning tasks? Grok 4 might just be the best out there.
And if you’re considering pricing, Gemini remains the winner in terms of price-to-performance ratio when compared to Claude 4 Opus and Grok 4.
Grok 4 API pricing doubles after 128k input tokens, though it would still be cheaper than Opus.
Brief on Grok 4
Grok 4 is the recent reasoning model from xAI and the most intelligent AI model so far. Grok 4 not only competes with other AI models but also with humans, yes, you heard it right.
It was the first model to score over 15% on the ARC‑AGI benchmark.
It comes with a 256k token context window, which, when compared, is very low compared to the Gemini 2.5 Pro's 1M token context window. It's just a bit ahead of the Claude 4 lineup, which has about 200k tokens.
This model has the same pricing as Grok 3 but with a twist: it costs around $3 per million input tokens (doubles after 128k) and $15 per million output tokens (doubles after 128k).
Key benchmarking results of Grok 4
This model achieves a record high score in GPQA Diamond with 88%, surpassing Gemini 2.5 Pro's 84%.
It reaches a new high in the Humanity Last Exam with 24%, beating Gemini 2.5 Pro's previous score of 21%.
It has the joint highest score for MMLU-Pro and AIME 2024 at 87% and 94%, respectively.
Not only that, it outperforms all the models in coding benchmarks, ranking first in the LiveCodeBench with 79.4%, while the second-best score is 75.8%.
And, there are a few other benchmarks where it leads all the models as well.

Overall, currently, if you consider any benchmarks, Grok 4 is likely to lead them all. However, don't blindly believe the benchmarks; they're only half the truth. That's why we're here, and we'll compare these models to find out which one is the best.
Coding Comparison
I did two rounds of coding comparison.
Frontend implementation: Plug each model with Figma MCP and code the design end-to-end.
3JS animation: Animate a black hole in 3JS
1. Figma Design Clone with MCP
Before we begin, here's the Figma design that we'll ask all three of these models to replicate in our Next.js application:
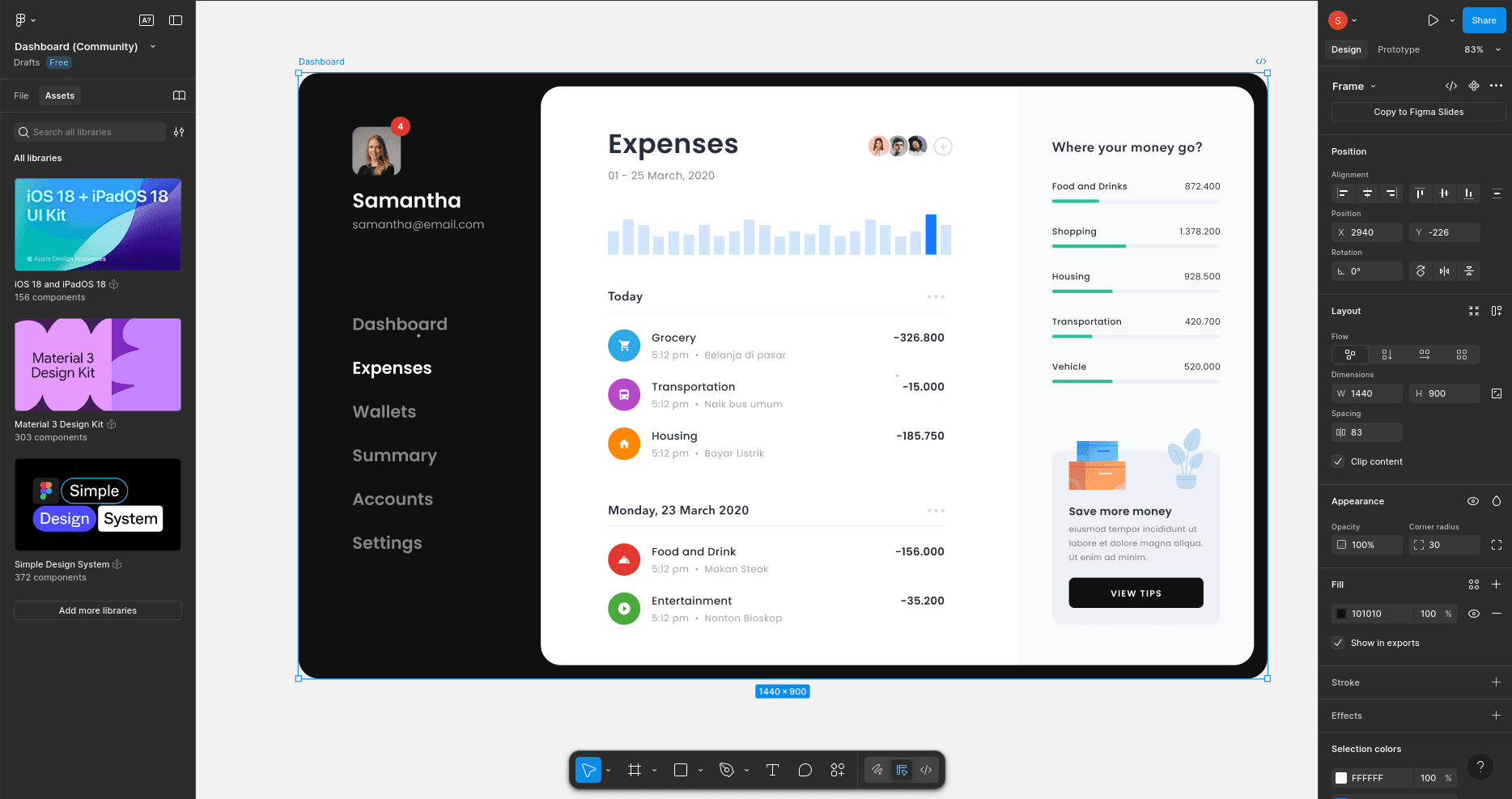
Prompt: Create a Figma design clone using the given Figma design as a reference: <URL>. Try to make it as close as possible.
Response from Grok 4
Here's the response it generated:
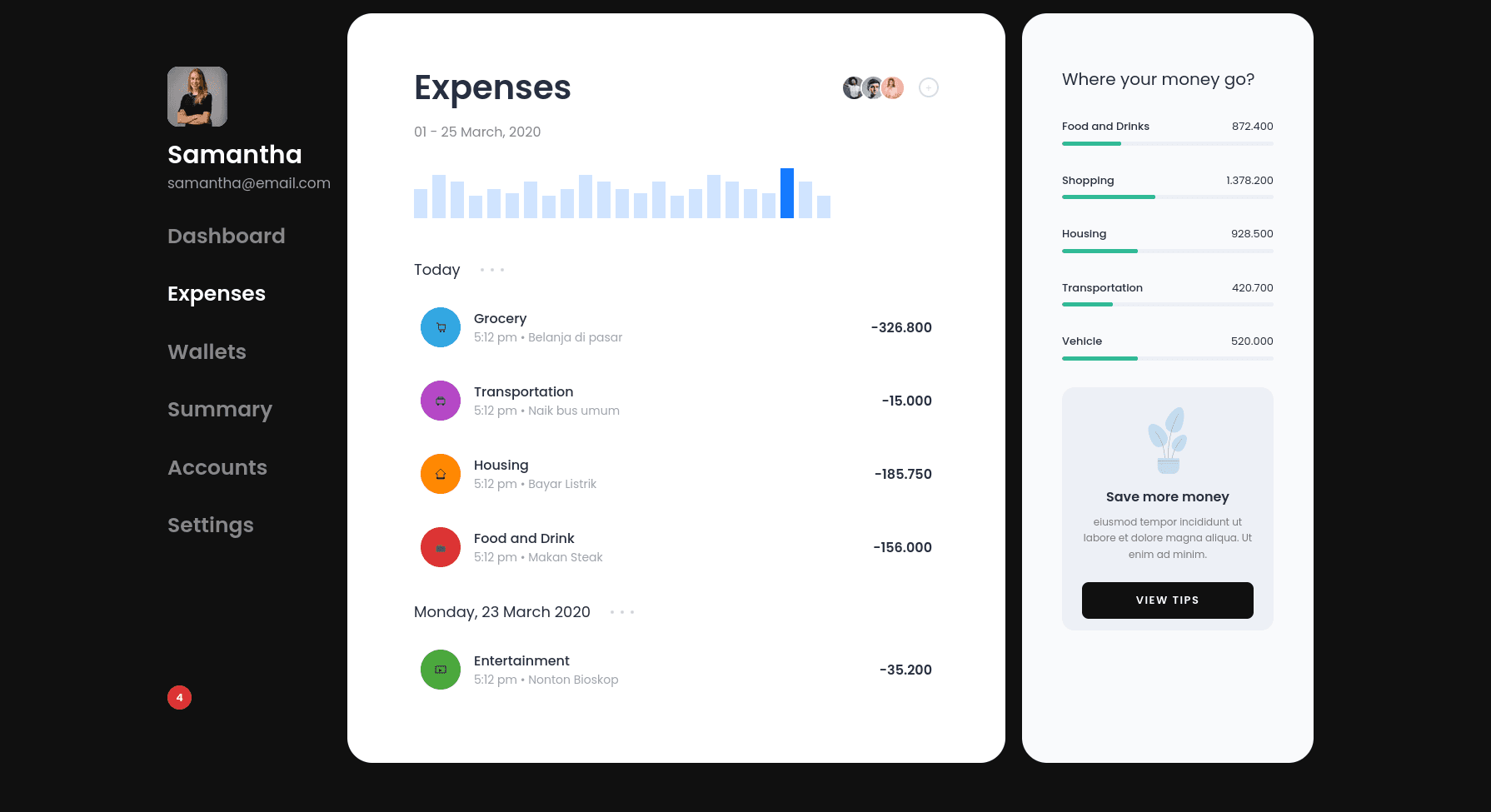
This looks awesome. I love the response; everything seems good, apart from some minor details, as you can see for yourself. Some icons are not really well-placed. The text and everything else is on point.
One small thing is that it took quite some time to implement this design, approximately 4 minutes. I wouldn't say it was many minutes, but comparatively, it took the longest to implement compared to the other two models.
Additionally, it was spot on in terms of tool calling. This model achieves 99% accuracy in selecting the correct tools and making tool calls with proper arguments almost every time, so there is no reason to doubt its effectiveness.
You can find the code it generated here: Link
Upon examining the code, it's not perfect. It could be broken down into multiple small components, as I didn't restrict it to using a single file for all the code changes, which would have allowed for better organisation. Nevertheless, it's still on point.
Response from Claude Opus 4
Here's the response it generated:
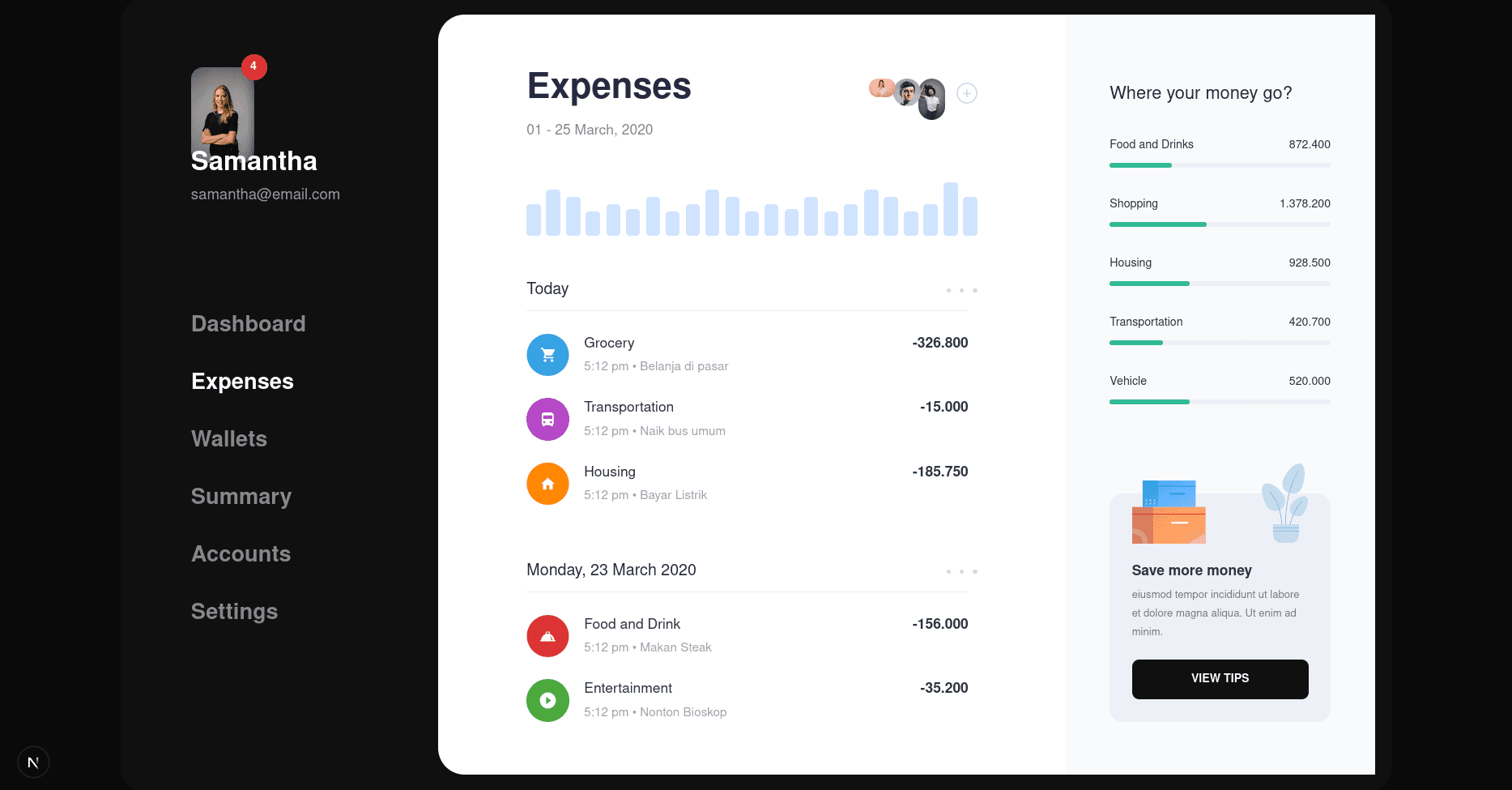
This one looks slightly better to me than the Grok 4 implementation. All the icons appear well-placed. If you look closely, there are definitely some inconsistencies, but overall, this is the closest to our Figma design.
You can find the code it generated here: Link
Opus 4 took approximately the same amount of time as Grok 4 and produced code that was very similar to Grok 4. It’s not really broken down into components, with everything packed into one file. Not that impressed with it, but at least it's the closest to the design.
Response from Gemini 2.5 Pro
This was the biggest surprise of all. This model, Gemini 2.5 Pro, couldn't figure out anything even after reviewing the design repeatedly.

As you can see, it couldn't implement anything other than some icons and text. All of this back and forth, but still, none of it works. The response was so poor that I thought there must be an error on my side. I tried it again and got a similar result. This is crazy. 🤦♂️
I have been using this model as my go-to for a long time, but for some reason, it seems not to be very effective with agentic workflows.
You can find the code it generated here: Link
However, upon examining the code, it is by far the best organised into small components, and the way the code is written is superior to Grok 4 or even Claude Opus 4. However, it's the final product that matters most, so I'm not really impressed with the response. 😔
Summary
Grok 4 and Claude Opus 4 both did a great job on this question in terms of replicating the design, but they struggled with the code.
2. Black Hole Animation
Prompt: Build a 3D Black Hole visualization with Three.js and shaders in a single HTML file. Try to make it as pretty and accurate as possible.
Response from Grok 4
You can find the code it generated here: Link
Here’s the output of the program:
This is gorgeous. The animation is smooth, and the feel is very accurate. The code is well-organised and easy to understand. It's a great result, and I'm impressed.
Initially, I encountered some CORS issues with Three.js, and I followed up with a prompt.
But as soon as I fixed it, the result was a gorgeous-looking black hole animation.
Response from Claude Opus 4
You can find the code it generated here: Link
Here’s the output of the program:
It's quite surprising, but I received a similar response with this model too. The only difference I noticed is that it added a few options to modify the animation.
Although it wasn't asked, it's nice that these controls were added. But just based on these added controls, I don't think we can compare them here. Both Grok 4 and this model did a great job with the implementation.
Response from Gemini 2.5 Pro
You can find the code it generated here: Link
Here’s the output of the program:
Now, I'm quite biased about the animation. Compared to the last two, this one doesn't feel as good.
However, it's not bad either. Everything works well, including the orbital controls, but the animation is just not as sharp and doesn't quite match the other two.
Conclusion
In this test, I couldn't find much difference in the response between Grok 4 and Claude Opus 4, but at times, it felt like Claude Opus outperformed the other two very slightly. But Grok 4 is cheaper, so there you have your answer.
You can't be wrong going with Grok 4 for coding, but you can use it as a project manager rather than a coder for maximum token efficiency.