Google just launched Gemini 2.5 Pro on March 26th, claiming to be the best in coding, reasoning and overall everything. But I mostly care about how the model compares against the best available coding model, Claude 3.7 Sonnet (thinking), released at the end of February, which I have been using, and it has been a great experience.
Let’s compare these two coding models and see if I need to change my favourite coding model or if Claude 3.7 still holds.
TL;DR
If you want to jump straight to the conclusion, I’d say go for Gemini 2.5 Pro, it's better at coding, has one million in context window as compared to Claude's 200k, and you can get it for free (a big plus). However, Claude's 3.7 Sonnet is not that far behind. Though at this point there's no point using it over Gemini 2.5 Pro.
Just an article ago, Claude 3.7 Sonnet was the default answer to every model comparison, and this remained the same for quite some time. But here you go, Gemini 2.5 Pro takes the lead.

Brief on Gemini 2.5 Pro
Gemini 2.5 Pro, an experimental thinking model, became the talk of the town within a week of its release. Everyone's talking about this model on Twitter (X) and YouTube. It's trending everywhere, like seriously. The first model from Google to receive such fanfare.
And it is #1 in the LMArena just like that. But what does this mean? It means that this model is killing all the other models in coding, math, Science, Image understanding, and other areas.

Gemini 2.5 pro comes with a 1 million token context window, with a 2 million context window coming soon. 🤯
You can check out other folks like Theo-t3 talking about this model to get a bit more insight into it:
It is the best coding model to date, with an accuracy of about 63.8% on the SWE bench. This is definitely higher than our previous top coding model, Claude 3.7 Sonnet, which had an accuracy of about 62.3%.

This is a quick demo Google shared on this model of building a dinosaur game.
Here's a quick benchmark of this model on Reasoning, Mathematics, and Science. This confirms that the model is not just suitable for coding but also for all your other needs. They claim it's an all-rounder. 🤷♂️
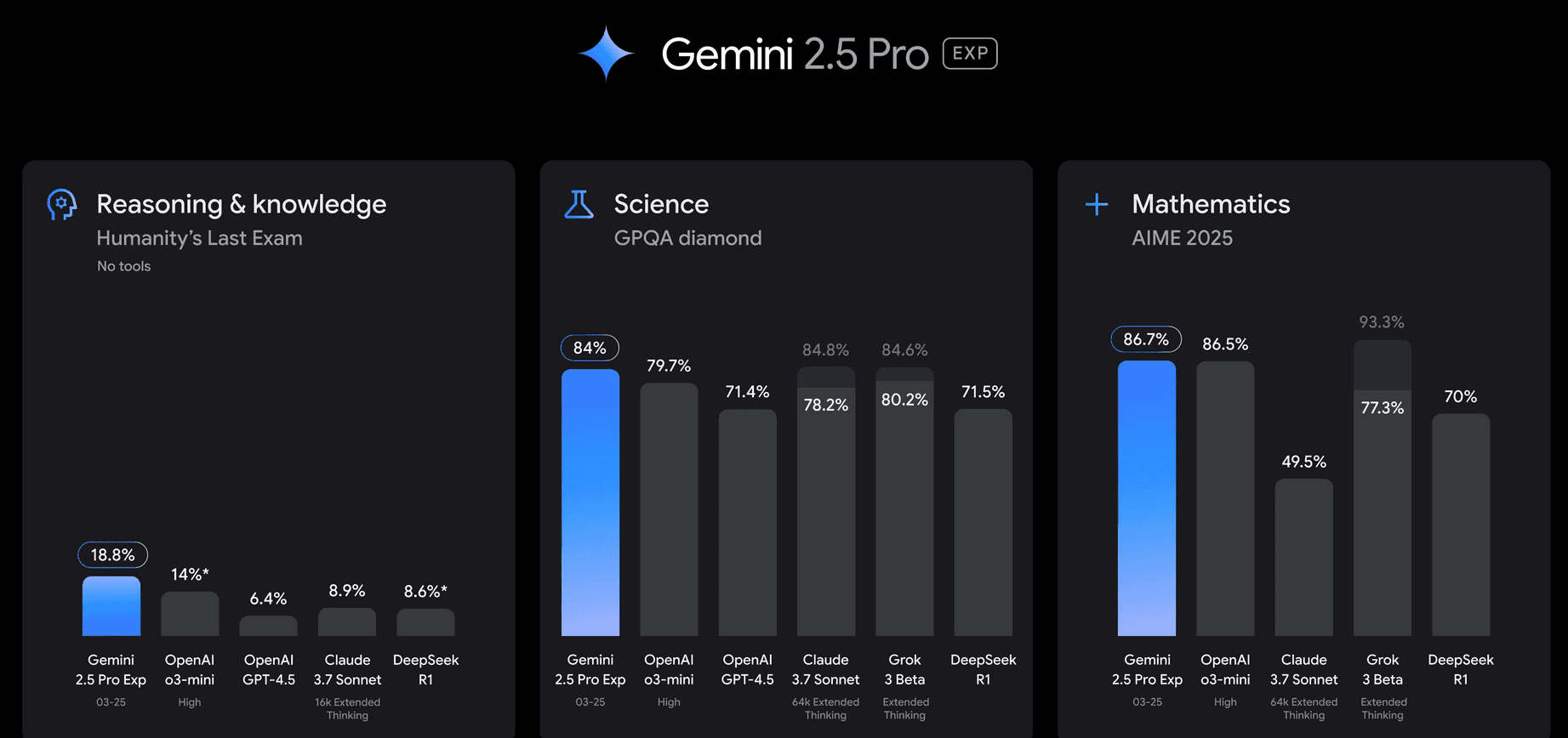
This is all cool, and I’ll confirm the claim, but in this article, I will mainly be comparing the model on coding, and let’s see how well it performs compared to Claude 3.7 Sonnet.
Coding Problems
Let’s compare these two models in coding. We’ll do a total of 4 tests, mainly on WebDev, animation and a tricky LeetCode question.
1. Flight Simulator
Prompt: Create a simple flight simulator using JavaScript. The simulator should feature a basic plane that can take off from a flat runway. The plane's movement should be controlled with simple keyboard inputs (e.g., arrow keys or WASD). Additionally, it generates a basic cityscape using blocky structures, similar to Minecraft.
Response from Gemini 2.5 Pro
You can find the code it generated here: Link
Here’s the output of the program:
I definitely got exactly what I asked for, with everything functioning, from plane movements to the basic Minecraft-styled block buildings. I can't really complain about anything here. 10/10 for this one.
Response from Claude 3.7 Sonnet
You can find the code it generated here: Link
Here’s the output of the program:
I can see some issues with this one. The plane clearly faces sideways, and I don't know why. Again, it was out of control once it took off and went clearly outside the city. Basically, I'd say we didn't really get a completely working flight simulator here.
Summary:
It's fair to say that Gemini 2.5 really got this correct in one shot. But the issues with the Claude 3.7 Sonnet code aren’t really that big to resolve. Yeah, we didn’t really get the output as expected, and it's definitely not close to what Gemini 2.5 Pro got us.
2. Rubik’s Cube Solver
This is one of the toughest questions for LLMs. I’ve tried it with many other LLMs, but none could correct it. Let’s see how these two models do this one.
Prompt: Build a simple 3D Rubik’s Cube visualizer and solver in JavaScript using Three.js. The cube should be a 3x3 Rubik’s Cube with standard colours. Have a scramble button that randomly scrambles the cube. Include a solve function that animates the solution step by step. Allow basic mouse controls to rotate the view.
Response from Gemini 2.5 Pro
You can find the code it generated here: Link
Here’s the output of the program:
It's impressive that it could do something this hard in one shot. With the 1 million token context window, I can truly see how powerful this model seems to be.
Response from Claude 3.7 Sonnet
You can find the code it generated here: Link
Here’s the output of the program:
Again, I was kind of disappointed that it had the same issue as some other LLMs: failing with the colours and completely failing to solve the cube. I did try to help it come up with the answer, but it didn’t really help.
Summary:
Here again, Gemini 2.5 Pro takes the lead. And the best part is that all of it was done in one shot. Claude 3.7 was really disappointing, as it could not get this one correct, despite being one of the finest coding models out there.
3. Ball Bouncing Inside a Spinning 4D Tesseract
Prompt: Create a simple JavaScript script that visualizes a ball bouncing inside a rotating 4D tesseract. When the ball collides with a side, highlight that side to indicate the impact.
Response from Gemini 2.5 Pro
You can find the code it generated here: Link
Here’s the output of the program:
I cannot notice a single issue in the output. The ball and the collision physics all work perfectly, even the part where I asked it to highlight the collision side works. This free model seems to be insane for coding. 🔥
Response from Claude 3.7 Sonnet
You can find the code it generated here: Link
Here’s the output of the program:
Wow, finally, Claude 3.7 Sonnet got an answer correct. It also added colors to each side, but who asked for it? 🤷♂️ Nevertheless, I can’t really complain much here, as the main functionality seems to work just fine.
Summary:
The answer is evident this time. Both models got the answer correct, implementing everything I asked for. I won’t really say that I like the output of Claude 3.7 Sonnet more, but it definitely put in quite some work compared to Gemini 2.5 Pro.
4. LeetCode Problem
For this one, let’s do a quick LeetCode check with to see how these models handle solving a tricky LeetCode question with an acceptance rate of just 14.9%: Maximum Value Sum by Placing 3 Rooks.
Claude 3.7 Sonnet is known to be super good at solving LC questions. If you want to see how Claude 3.7 compares to some top models like Grok 3 and o3-mini-high, check out this blog post:
Claude 3.7 Sonnet vs. Grok 3 vs. o3-mini-high: Coding comparison
Prompt:
You are given a m x n 2D array board representing a chessboard, where board[i][j] represents the value of the cell (i, j).
Rooks in the same row or column attack each other. You need to place three rooks on the chessboard such that the rooks do not attack each other.
Return the maximum sum of the cell values on which the rooks are placed.
Example 1:
Input: board = [[-3,1,1,1],[-3,1,-3,1],[-3,2,1,1]]
Output: 4
Explanation:
We can place the rooks in the cells (0, 2), (1, 3), and (2, 1) for a sum of 1 + 1 + 2 = 4.
Example 2:
Input: board = [[1,2,3],[4,5,6],[7,8,9]]
Output: 15
Explanation:
We can place the rooks in the cells (0, 0), (1, 1), and (2, 2) for a sum of 1 + 5 + 9 = 15.
Example 3:
Input: board = [[1,1,1],[1,1,1],[1,1,1]]
Output: 3
Explanation:
We can place the rooks in the cells (0, 2), (1, 1), and (2, 0) for a sum of 1 + 1 + 1 = 3.
Constraints:
3 <= m == board.length <= 100
3 <= n == board[i].length <= 100
-109 <= board[i][j] <= 109
Response from Gemini 2.5 Pro
Given how easily it answered all three of the coding questions we tested, I have quite high hopes for this model.
You can find the code it generated here: Link
It did take quite some time to answer this one, though, and the code it wrote is kind of super complex to make sense of. I think it answered it more complicated than required. But still, the main thing we’re looking for is to see if it can answer it correctly.
As expected, it also answered this tough LeetCode question in one shot. This is one of the questions I got stuck on when learning DSA. I’m not sure if I’m happy it did.
Response from Claude 3.7 Sonnet
I hope this model will crush this one, as in all the other coding tests I’ve done, Claude 3.7 Sonnet has answered all of the LeetCode questions correctly.
You can find the code it generated here: Link
It did write correct code but got TLE, but if I have to compare the code's simplicity, I’d say this model made the code simpler and easier to understand.

Summary:
Gemini 2.5 got the answer correct and also wrote the code in the expected time complexity, but Claude 3.7 Sonnet fell into TLE. If I have to compare the code simplicity, Claude 3.7’s generated code seems to be better.
Conclusion
For me, Gemini 2.5 Pro is the winner. We’ve compared two models that are said to be the best at coding. The big difference I see in the model stats is just that Gemini 2.5 Pro has a slightly higher context window, but let's not forget that this is an experimental model, and improvements are still on the way.
Imagine this model's performance after a 2M token context window.
Google's been killing it recently with such solid models, previously with the Gemma 3 27B model, a super lightweight model with unbelievable results, and now with this beast of a model, Gemini 2.5 Pro.
By the way, if you are here, Composio is building the skill repository for agents. You can connect LLMs to any application from Gmail to Asana and get things done quickly. You can use MCP servers or directly add the tools to LLMs.