I have been working on agents for a while now, and while it’s exciting, there are definitely parts that are tough to get right.
Over time, I have kept a mental list of the things that consistently slow me down. It’s no surprise that many new SDKs and frameworks have emerged to address these pain points.
In this post, I will share the most challenging issues I have encountered while building agents and how you can approach each of them.
TL;DR
Building AI agents sounds exciting, but the real work is in managing all the messy parts that break when things get real. This post covers the biggest pain points and how to deal with them:
Too much framework complexity: Many SDKs over-engineer simple tasks. Lighter options like Pydantic AI, SmolAgents, or Composio make things faster to build and easier to debug.
Lack of human oversight: Fully autonomous agents are risky. Add human-in-the-loop approval steps to keep control.
Poor transparency: Agents often act like black boxes. Use frameworks with logging, tracing, or graph-based flows (like LangGraph) to make reasoning visible.
Token waste and state loss: Agents burn through tokens and forget context fast. Compress conversations, cache results, and store state externally.
Coordination and memory issues: Multi-agent systems easily become chaos. Use protocols like A2A or ACP for coordination, and frameworks that support persistent memory.
Security, reliability, and triggers: Safely handle API keys, validate tool outputs, and use managed actions and trigger systems (Composio Triggers) for real-time awareness.
1. Overly Complex Frameworks
More seriously, I think the biggest challenge is using agent frameworks that try to do everything and end up feeling like overkill.
Those frameworks are powerful and can do amazing things, but in practice, you end up only using 10% and then you realize that it's too complex to do the simple, specific things you need it to do. It's like fighting the framework instead of building with it.
What actually helps:
Instead, I prefer a simple framework that I end up using 90% of and the rest of the work is simple enough to build on top.
A concrete example: in LangChain, defining a simple agent with a single tool can involve setting up chains, memory objects, executors, and callbacks. That’s a lot of stuff when all you really need is an LLM call plus one function.
Compare that to lightweight libraries out there like Pydantic AI or Hugging Face’s SmolAgents, where the same thing takes just a few lines of code.
from pydantic_ai import Agent, RunContext
roulette_agent = Agent(
'openai:gpt-4o',
deps_type=int,
output_type=bool,
system_prompt=(
'Use the `roulette_wheel` function to see if the '
'customer has won based on the number they provide.'
),
)
@roulette_agent.tool
async def roulette_wheel(ctx: RunContext[int], square: int) -> str:
"""check if the square is a winner"""
return 'winner' if square == ctx.deps else 'not a winner'
# run the agent
success_number = 18
result = roulette_agent.run_sync('Put my money on square eighteen', deps=success_number)
print(result.output) # TrueAnother example can be Composio, where you install composio, initialize a client and call tools on behalf of a user with almost no setup (no custom executors or callback chains needed).
If you send an email via Gmail, you might do:
from composio import Composio
from openai import OpenAI
openai = OpenAI()
composio = Composio(api_key="YOUR_COMPOSIO_API_KEY")
user_id = "user@example.com"
# authorize Gmail for this user (opens an OAuth URL)
connection_request = composio.toolkits.authorize(user_id=user_id, toolkit="gmail")
print(f"Visit URL to authorize: {connection_request.redirect_url}")
connection_request.wait_for_connection()
# fetch the Gmail tools and let the LLM call them
tools = composio.tools.get(user_id=user_id, toolkits=["GMAIL"])
completion = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Send an email to Alice"}],
tools=tools,
)
result = composio.provider.handle_tool_calls(user_id=user_id, response=completion)
print(result)You get structured output and easy reuse. If you do need more features later, you can layer on complexity only as needed.
2. No “human-in-the-loop”
One of the biggest risks with agents is giving them too much autonomy without oversight. Purely autonomous agents can behave unpredictably or make unsafe decisions (such as booking the wrong flights or sending sensitive emails on your behalf).
Without breakpoints or approval steps, you are basically handing over the keys and hoping the agent doesn’t crash the car.
I was experimenting with an MCP Agent for LinkedIn. It was fun to prototype, but I quickly realized there were no natural breakpoints. Giving the agent full control to post or send messages felt risky (one misfire and boom).
What actually helps:
The fix is to introduce human-in-the-loop (HITL) controls directly into your agents. Safe breakpoints where the agent pauses, shows you its plan or action and waits for approval before continuing.
Most modern frameworks like CrewAI, LangChain and CopilotKit support this approach.
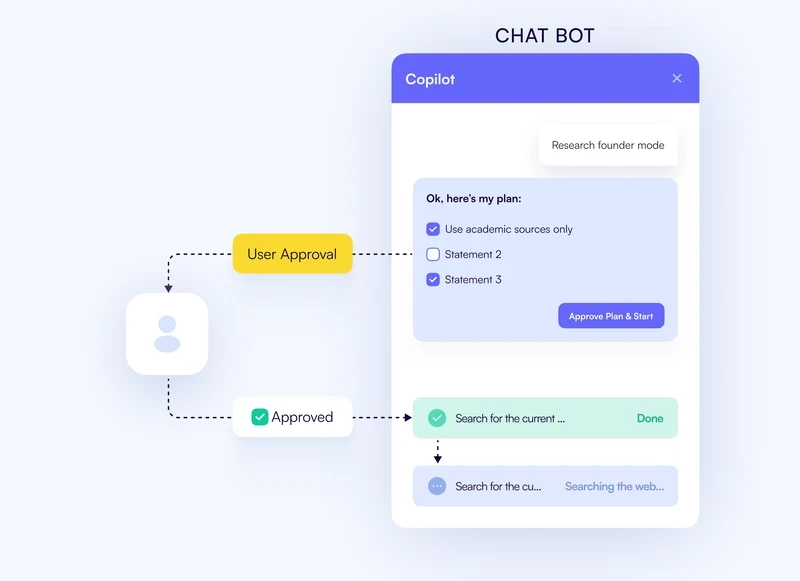
CopilotKit HITL design
Here's a simple example pattern:
# Pseudo-code for HITL approval
def approval_hook(action, context):
print(f"Agent wants to: {action}")
user_approval = input("Approve? (y/n): ")
return user_approval.lower().startswith('y')
# Use in agent workflow
if approval_hook("send_email", email_context):
agent.execute_action("send_email")
else:
agent.abort("User rejected action")The upshot is: you stay in control. The agent does the legwork but you approve every important step.
3. Black-Box Reasoning
Half the time, I can’t explain why my agent did what it did. It will take some weird action, skip an obvious step, or just make something up because it thought that’s what I wanted.
Missing inputs lead to made-up outputs and without a trace, you are left guessing whether it was the model, the data or your own logic at fault.
The whole thing feels like a black box where the plan is hidden inside the model’s head.
What actually helps:
A simple thing is to force the model to show its work. Instead of silently deciding, you can make it generate a structured plan that’s logged step-by-step. You can also use a tracing tool around the agent loop (such as Langfuse, OpenTelemetry) to record each decision step so you can replay a run later.
LangGraph uses a node-based graph where every decision is explicit and can be replayed or audited.
Here's a minimal example.
from langgraph.graph import StateGraph, END
from typing_extensions import TypedDict
class State(TypedDict):
x: int
y: int
def step1(state: State) -> dict:
print("Step 1")
return {"x": 1}
def step2(state: State) -> dict:
print(f"Step 2 (got x={state['x']})")
return {"y": state["x"] + 1}
graph = StateGraph(State)
graph.add_node("step1", step1)
graph.add_node("step2", step2)
graph.set_entry_point("step1")
graph.add_edge("step1", "step2")
graph.add_edge("step2", END)
app = graph.compile()
print("Final:", app.invoke({}))The output will look something like:
Step 1
Step 2 (got x=1)
Final: {'x': 1, 'y': 2}This explicit flow also makes debugging a little easier.
4. Token Consumption Explosion
One of the sneakier problems with agents is how fast they can consume tokens. The worst part? I couldn’t even see what was going on under the hood. I had no visibility into the exact prompts, token counts, cache hits and costs flowing through the LLM.
I have seen setups where a single run quietly racks up thousands of tokens, not because the model was doing anything amazing but because the framework was stuffing the entire execution history into the context window.
What actually helps:
The main reason is that most frameworks out there optimize for simplicity, not efficiency. There are a few ways to keep this under control:
✅ Instead of keeping every tool result in the conversation, move them into a shared graph state (LangGraph does this nicely). Pass them to LLM only when needed, not on every call.
✅ You can periodically compress older interactions into a rolling summary, while keeping only the necessary parts. That way, the agent retains context without having to carry the entire history.
✅ Some frameworks provide built-in optimization like AutoGen, which provides caching of LLM API calls, which helps prevent repeated calls with the same inputs. It supports various cache backends including disk, Redis, Cosmos DB.
Here's a simple approach:
context.append(user_message)
if token_count(context) > MAX_TOKENS:
summary = llm("Summarize: " + " ".join(context))
context = [summary]Platforms like Composio can also help here, as their tools return structured JSON rather than raw text. Meaning you can persist the outputs outside the prompt and feed back only the minimal context later.
If you are interested in reading more, check out Agent Memory: How to Build Agents that Learn and Remember by Letta. They have shown that a simple strategy is to evict 70% of older messages when the context window fills.
5. State & Context Loss
One of the most frustrating things with agents is how quickly they forget what they were doing. You kick off a multi-step plan, everything looks good → then halfway through, it just drops a detail or loses track entirely.
This happens because context is usually just passed around inside prompts. Once you hit a token limit or the system crashes, that state is gone unless you have set up a way to save it.
What actually helps:
You can store your documents in a vector database (like Turbo puffer or Weaviate) and have a retrieval step fetch the most relevant facts before answering. Here are some frameworks and what they do:
✅ LangGraph → Includes graph-based flows where each node holds its state so partial progress can survive crashes.
✅ LlamaIndex → ChatMemoryBuffer + storage connectors for persisting conversation state.
✅ Mem0 → External memory store that agents can query for past steps/details.
Here's a simple code snippet that helps the agent pick up if the process crashes midway.
# resuming agent run after failure
state = load_state("run_state.json") or {"completed": []}
for step in plan.steps:
if step.name in state["completed"]:
continue
result = agent.execute(step)
state["completed"].append(step.name)
save_state("run_state.json", state)6. Multi-Agent Coordination Nightmares
Sometimes one agent isn’t enough. You split the work into roles: “planner” agent to outline steps, “researcher” agent to gather data and “writer” agent to draft the final output.
But orchestrating multiple agents introduces complexity: who decides which agent should run and when? how do they share memory without tripping over each other?
And if you scale to five or ten agents, the sync overhead can feel a lot worse (when you are coding the whole thing yourself).
What actually helps:
There are two protocols (recently introduced) to solve this issue:
✅ Agent2Agent (A2A) Protocol : protocol from Google that solves this using a JSON-RPC & SSE standard. Agents publish a JSON Agent Card (capabilities, endpoint, auth). Others fetch it to know "who to call and how".
✅ ACP (Agent Communication Protocol) : open protocol for communication between AI agents, applications and humans. It works over a standardized RESTful API and builds on many of A2A's ideas.
If A2A focuses on agent-to-agent collaboration, ACP extends that to include human and app interaction & uses REST, OpenAPI, multipart formats.
If you are new to these protocols and want to understand more, you can read this blog about all the agent protocols in-depth.
Here are some framework options designed for multiple agents.
✅ CrewAI : you can define a “crew” of role-based agents (Writer, Researcher, Editor) that share a conversation context. It handles routing so each agent contributes in turn.
✅ AutoGen : Frames the process as an asynchronous conversation among agents, which is good for long tasks with waiting.
✅ Strands Agents SDK : Useful when you are mixing providers (OpenAI, Anthropic, local models) and with strong observability.
In practice, I start with the simplest design: if I really need sub-agents, I might manually code an agent-to-agent handoff.
plan = planner_agent.run_sync("Outline the solution steps.")
for step in plan.steps:
if step.type == "research":
content = researcher_agent.run_sync(step.text)
elif step.type == "write":
content = writer_agent.run_sync(step.text)
memory.append(content)This explicit logic (instead of fully dynamic LLM decisions) keeps coordination clear.
7. Long-term memory problem
Then there’s the long-term memory problem. Maintaining context is core to agent performance, but deciding what to remember is tricky.
Too much memory and the context window overflows.
Too little and the agent forgets useful info.
This is the “memory bottleneck”, you have to decide “what to remember, what to forget and when” in a systematic way.
What actually helps:
Naive approaches don’t cut it. Dumping the full history into prompts blows past token limits. I have seen agents repeat outdated facts just because nothing told them, “hey, that no longer matters”.
Keep short-term memory (current conversation context) separate from long-term memory (persistent knowledge). Compress or drop stale context if possible. Store important facts in the long-term index.
This code snippet appends the latest user message to the conversation context and then uses functions token_count() and llm() to:
Check if the total token count exceeds
MAX_TOKENS.If so, generate a condensed summary of the whole context using the LLM (
llm("Summarize: " + ...)).Replace the full context with this summary, reducing tokens while preserving important info.
context.append(user_message)
if token_count(context) > MAX_TOKENS:
summary = llm("Summarize: " + " ".join(context))
context = [summary]Here are some frameworks you can try:
✅ Letta → Allows agents to self-improve over time through editing their own context (agentic context engineering).
✅ Mem0 → Purpose-built memory layer for agents with relevance scoring & long-term recall.
✅ LlamaIndex → Offers vector memory, retrieval & summarization for scalable memory.
✅ LangGraph → Supports persistent state and memory replay in graph workflows.
8. The "Almost Right" Code Problem
Even with a perfect framework, large language models can still surprise you. The biggest frustration developers (including me) face is dealing with AI-generated solutions that are "almost right, but not quite".
Debugging that “almost right” output often takes longer than just writing the function yourself.
What actually helps:
There’s not much we can do here (this is a model-level issue) but you can add guardrails and sanity checks. For example, always validate tool outputs or model answers:
→ If the agent is supposed to output a date or a number, check the format.
→ If the model loops or repeats, break the loop by imposing a max step count or forcing it to move on.
Some frameworks support chain-of-thought reflection or self-correction steps. No framework can magically make the code better but having validation steps makes the flow auditable before execution. Similarly, LangGraph workflows let you insert explicit approval steps.
In code, you might do something like:
def validate_output(output, expected_type):
if expected_type == "date":
try:
datetime.strptime(output, "%Y-%m-%d")
return True
except ValueError:
return False
# Add more validation logic
return True
result = agent.execute(task)
if not validate_output(result, "date"):
result = agent.retry_with_feedback("Please provide date in YYYY-MM-DD format")You might find this section slightly related to Human-in-the-Loop (since both are about trust and control) but here we are focusing on code quality and accuracy, whereas HITL is more about safety and oversight.
9. Authentication & Security Trust Issue
Most frameworks are designed to “just work” with APIs. Security is usually an afterthought in an agent's architecture.
So handling authentication is tricky with agents. On paper, it seems simple: give the agent an API key and let it call the service. But in practice, this is one of the fastest ways to create security holes (like MCP Agents).
Role-based access controls must propagate to all agents and any data touched by an LLM becomes "totally public with very little effort".
What actually helps:
Solving this requires more than just managed auth; it demands a comprehensive infrastructure that covers authentication, granular controls, and reliable tool execution. This is often the biggest challenge in production, and choosing among the best AI agent builders and integrations often comes down to how well they solve for this action layer.
Architectural patterns like the MCP Gateway provide this control plane by centralizing agent-to-tool communication. You can read more about this in our guide to secure AI agent infrastructure. To start, adopt a similar pattern every time to cover all the edge cases:
Grant minimal required permissions.
Let agents request access only when needed (use OAuth flows or Token Vault mechanisms).
Treat sensitive actions as reviewable (by including human-in-the-loop checks).
Store tokens safely, not in prompts or logs.
Track all API calls and enforce role-based access via an identity provider (Auth0, Okta).
Run tools in isolated environments when possible.
Sanitize user inputs before sending to LLMs (once PII gets into context, there’s no going back).
Let's take some frameworks and see how they handle security:
✅ AgentAuth (Composio) → Provides a unified platform for OAuth, API keys, JWT and more, covering hundreds of apps.
Here’s how a typical Composio OAuth flow looks (Python):
from composio import Composio
from openai import OpenAI
openai = OpenAI()
composio = Composio(api_key="YOUR_COMPOSIO_API_KEY")
user_id = "user@example.com"
# Step 1: Initiate OAuth authorization (e.g., Gmail)
conn_req = composio.toolkits.authorize(user_id=user_id, toolkit="gmail")
print(f"Visit this URL to authorize Gmail: {conn_req.redirect_url}")
# [User visits URL and grants access...]
# Step 2: Wait for the user to complete OAuth
conn_req.wait_for_connection()
# Now the user_id is linked to Gmail and we can fetch Gmail tools
tools = composio.tools.get(user_id=user_id, toolkits=["GMAIL"])After the user completes the OAuth flow, Composio automatically handles refreshing tokens and associating credentials with that user_id. From then on, any tool calls on behalf of that user use the stored tokens.
You use the same simple authorize call on any supported toolkit. After authorize, you can pass the returned tools list into an LLM chat completion. The agent then uses those tools as if they were built-in functions. Read more on the docs.
✅ Auth0 (Auth for GenAI) → Provides a Token Vault, async auth flows (CIBA/PAR) and fine-grained doc-level permissions.
✅ AgentAuth (Composio) → Unified SDK for handling OAuth across 250+ apps. works with OpenAI Agents SDK, LangChain, LlamaIndex, CrewAI.
✅ Progent (Academic) → proof-of-concept research for defining/enforcing privilege policies inside agents at runtime. It introduces an experimental framework, but you should definitely read this.
Pick frameworks that build auth in and design your own flows so every sensitive step is explicit, logged and reviewable. Otherwise, things can go so wrong.
10. Tool Calling Reliability Issues
Here’s the thing about agents: they are only as strong as the tools they connect to. And those tools? They change all the time.
I have run into this more than once. Everything is working smoothly until suddenly the workflow breaks. Not because my code changed but because the external API did.
Maybe Google Calendar quietly updated a field name.
Maybe Stripe added stricter rate limits.
Or maybe the API just went down for a few minutes.
The agent has no idea how to handle that so it just fails mid-task. To make things worse, LLMs aren’t always great at formatting requests.
What actually helps:
Enforce schemas so the agent can’t just “guess” arguments.
Make tools plug-and-play instead of hardcoding integrations.
Protocols like MCP (adopted by OpenAI) and A2A (adopted by LAION) reduce schema mismatches. To implement these protocols effectively, many developers use an MCP Gateway, which acts as a central control plane for managing agent-tool communication, security, and observability.
Don’t fail on the first error, retry or swap tools.
Choose options that give you visibility into API calls, token issues or bad arguments.
Who’s doing what today:
LangChain → Structured tool calling with Pydantic validation.
LlamaIndex → Built-in retry patterns and validator engines to help self-correct queries.
CrewAI → Error recovery/handling & structured retry flows.
Composio → 500+ integrations with prebuilt OAuth handling and impressive tool calling architecture.
Here’s an example of how you can make tool calls a little more reliable:
from composio_openai import ComposioToolSet, Action
# Get structured, validated tools
toolset = ComposioToolSet()
tools = toolset.get_tools(actions=[Action.GITHUB_STAR_A_REPOSITORY_FOR_THE_AUTHENTICATED_USER])
# Tools come with built-in validation and error handling
response = openai.chat.completions.create(
model="gpt-4",
tools=tools,
messages=[{"role": "user", "content": "Star the composio repository"}]
)
# Handle tool calls with automatic retry logic
result = toolset.handle_tool_calls(response)In Composio, every tool is fully described with a JSON schema for its inputs and outputs. Composio’s API returns an error code (Error 603: Invalid App Schema) if the JSON doesn’t match the expected schema.
You can catch this in code and handle it gracefully (for example, prompting the LLM to retry or falling back to a clarification step).
try:
result = composio.provider.handle_tool_calls(user_id=user_id, response=llm_response)
print("Tool executed:", result)
except Exception as e:
# Handle known schema mismatch error
if "Invalid App Schema" in str(e):
print("LLM sent bad schema, asking to retry or clarifying.")
else:
raiseComposio’s SDK also provides schema modifiers and processors (middleware) so you can customize how tools appear to your agent. For instance, you can mark certain fields as required, add examples, or rename fields to fit your use case.
This fine-tuning of the tool definitions further guides the LLM to use tools correctly.
By the way, you also get access to an extensive tool registry if you are using Composio. They maintain these integrations centrally, so when APIs change, the fixes are deployed automatically without you having to update your code.

11. No Real-Time Awareness (Event Triggers)
One thing I have learned: agents aren’t that useful if they just wait for you to ask them something.
The real magic happens when they can react automatically to things happening in the real world. Most of today’s agents are built on simple request-response loops. You send a query, they reply.
But once you try to set up a reliable event-driven system (say, notify teammates when an API starts returning 500s or post deployment status to Slack right after a build completes), you hit a wall.
You have to juggle webhooks, authentication, retries, filtering, scaling… and make sure nothing silently fails.
What actually helps:
The easiest thing is to use a managed trigger platform instead of rolling your own webhook system. You will get a consistent event interface, structured payloads, retries and built-in integrations for hundreds of apps.
For instance: Composio Triggers can send payloads to your AI agents or systems based on events in apps. You can create triggers using either the Composio dashboard or programmatically via the SDK.
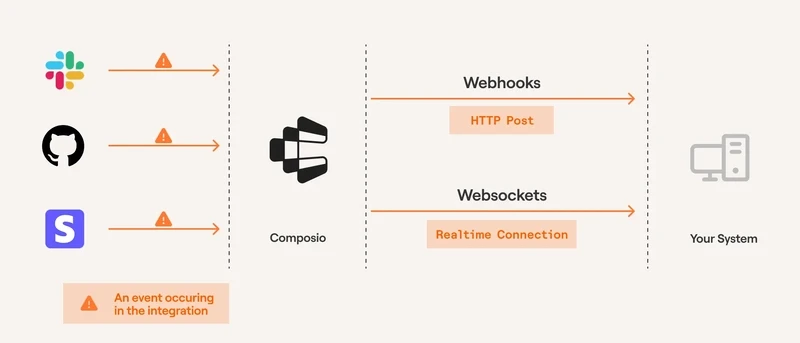
You can find the complete walkthrough on the docs for creating it via the dashboard.
Let’s take a simple example where your agent reacts to a new Slack message and responds automatically.
from composio import Composio
from composio.client.collections import TriggerEventData, ComposioToolSet
composio = Composio(api_key="your-api-key")
user_id = "user-123"
# Slack trigger for new messages
trigger = composio.triggers.create(
slug="SLACK_NEW_MESSAGE",
user_id=user_id
)
# Create a listener for trigger events
toolset = ComposioToolSet()
listener = toolset.create_trigger_listener()
@listener.callback(filters={"trigger_name": "SLACK_NEW_MESSAGE"})
def handle_new_message(event: TriggerEventData) -> None:
message = event.payload["text"]
sender = event.payload["user"]
channel = event.payload["channel"]
# Let your agent decide how to respond
reply = your_agent.generate_reply(message, sender)
# Send reply back to Slack
composio.tools.execute(
action="SLACK_SEND_MESSAGE",
params={
"channel": channel,
"text": reply
},
user_id=user_id
)
# Start listening for new messages
listener.listen()The full event lifecycle includes:
Managed OAuth with automatic token refresh
Only get the events you care about
Consistent structure across all apps
Built-in retry logic and error handling
Cloud-managed infra
And if you prefer a webhook approach (recommended for production use) instead of the SDK listener, that’s easy too:
from fastapi import FastAPI, Request
from composio_openai import ComposioToolSet, Action
from openai import OpenAI
app = FastAPI()
client = OpenAI()
toolset = ComposioToolSet()
@app.post("/webhook")
async def webhook_handler(request: Request):
payload = await request.json()
# Handle Slack message events
if payload.get("type") == "slack_receive_message":
text = payload["data"].get("text", "")
# Pass the event to your LLM agent
tools = toolset.get_tools([Action.SLACK_SENDS_A_MESSAGE_TO_A_SLACK_CHANNEL])
resp = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "You are a witty Slack bot."},
{"role": "user", "content": f"User says: {text}"},
],
tools=tools
)
# Execute the tool call (sends a reply to Slack)
toolset.handle_tool_calls(resp, entity_id="default")
return {"status": "ok"}Composio takes care of verifying the trigger event and formatting the tool call. You just write your normal agent logic.
The trigger payload includes context (message text, user, channel, etc.), so your agent can use that as part of its reasoning or pass it directly to a tool.
This pattern works for any app integration: Slack messages, calendar events, CRM updates, GitHub commits and hundreds of other triggers.
I have read a lot these past days, so here are some free blogs that really dig in (and make you think twice about frameworks):
Leave Agentic AI Frameworks And Build Agents From Scratch - Vishal Rajput (medium)
When (Not) to Use Agentic AI - Paul Simmering (personal blog)
The Hidden Cost of Agentic AI: Why Most Projects Fail Before Reaching Production - Several Authors (Galileo team)
We don't need more frameworks. We need agentic infrastructure - a separation of concerns - Reddit (r/AI_Agents)
At the end of the day, agents break for the same old reasons. Most of the possible fixes are the boring stuff nobody wants to do.
Frameworks are getting better, but most agents are still just a fragile demo. Do the basics right and it might start acting like a system you can trust.