There are only two kinds of modern developers: those who love the closed Claude Code and those who love the extremely customisable OpenCode.
Within a year of its launch, OpenCode has risen to be a developer-loved coding agent, in a true David vs Goliath fashion.
If you have ever met an OpenCode user, you’d know they swear by it, very passionate and hardcore users. And you won’t ever meet a casual OpenCode user. It’s tailor-made for people who want efficiency.
Claude Code, on the other hand, is the market leader. It’s the OG coding agent and at this point a household name.
But where do they actually differ from each other, and when do you want to use one over the other?
So, in this article, we'll compare Opencode (David) vs Claude Code (Goliath) and see which one truly wins its place as a coding agent in your work.
Quick disclosure on where I'm coming from: Claude Code is my daily driver at work, OpenCode is the tool I reach for in my personal use, and when I want to run a model that Anthropic doesn't ship, Kimi, an OpenAI model, or something local.
And I have spent more than 100 hours on both doing frontend designs and infrastructure.
TL;DR
Claude Code | OpenCode | Winner (for me) | |
|---|---|---|---|
Pricing | Flat subscription ($20–$200/mo) | Open models hit SOTA-level for far less | OpenCode (Claude Code for SOTA models) |
Models | Leads with SOTA (Opus 4.8, Fable) | 75+ providers, but chasing the frontier | Claude Code |
Architecture | Closed, welded to one model | Open, inspectable, you hold the keys | OpenCode |
Reliability | Changes under you, no pinning | Pin the combo, it won't move | OpenCode |
Extensibility | Most mature ecosystem + marketplace | Deeper hooks, SQLite-backed | Claude Code |
UX | Terminal + desktop + IDE (most surfaces) | Best TUI, but one surface | Claude Code |
Scorecard: 3–3. A real tie. You pick by temperament, not by tallying boxes.
As of June 2026. Model versions and limits move fast; treat specifics as a snapshot.
In summary:
Claude Code wins if you want state-of-the-art models (Opus) at a discounted price and ease of use. Pick OpenCode if you want a low-cost alternative that lets you use any and all models.
Related: Claude Code vs Codex
1. Pricing: Claude Code vs OpenCode
Claude Code | OpenCode | |
|---|---|---|
Model | Bundled in Claude subscription | Free MIT software, pay for models |
Entry | $20/mo Pro (Sonnet + Opus) | $0 (BYO key or local) |
Heavy tier | Max 20x at $200/mo | Go: ~$10/mo, open models, 6x usage |
Proprietary models | Included | Zen: pay-as-you-go gateway |
Limits | 5-hour budget + weekly cap (doubled May '26) | Dollar-denominated (Go) |
Gotcha | API key in the shell silently bills per token | Go roster is Chinese-lab open models only |
Claude Code: flat fee, predictable until the wall
Claude Code pricing is what makes it interesting. It’s good and bad at the same time.
Semi-analysis conducted an independent test in which they ran the Claude Code subscriptions tier across multiple tasks and benchmarked it against the API costs for the same tasks. And the outcome was interesting to say the least.
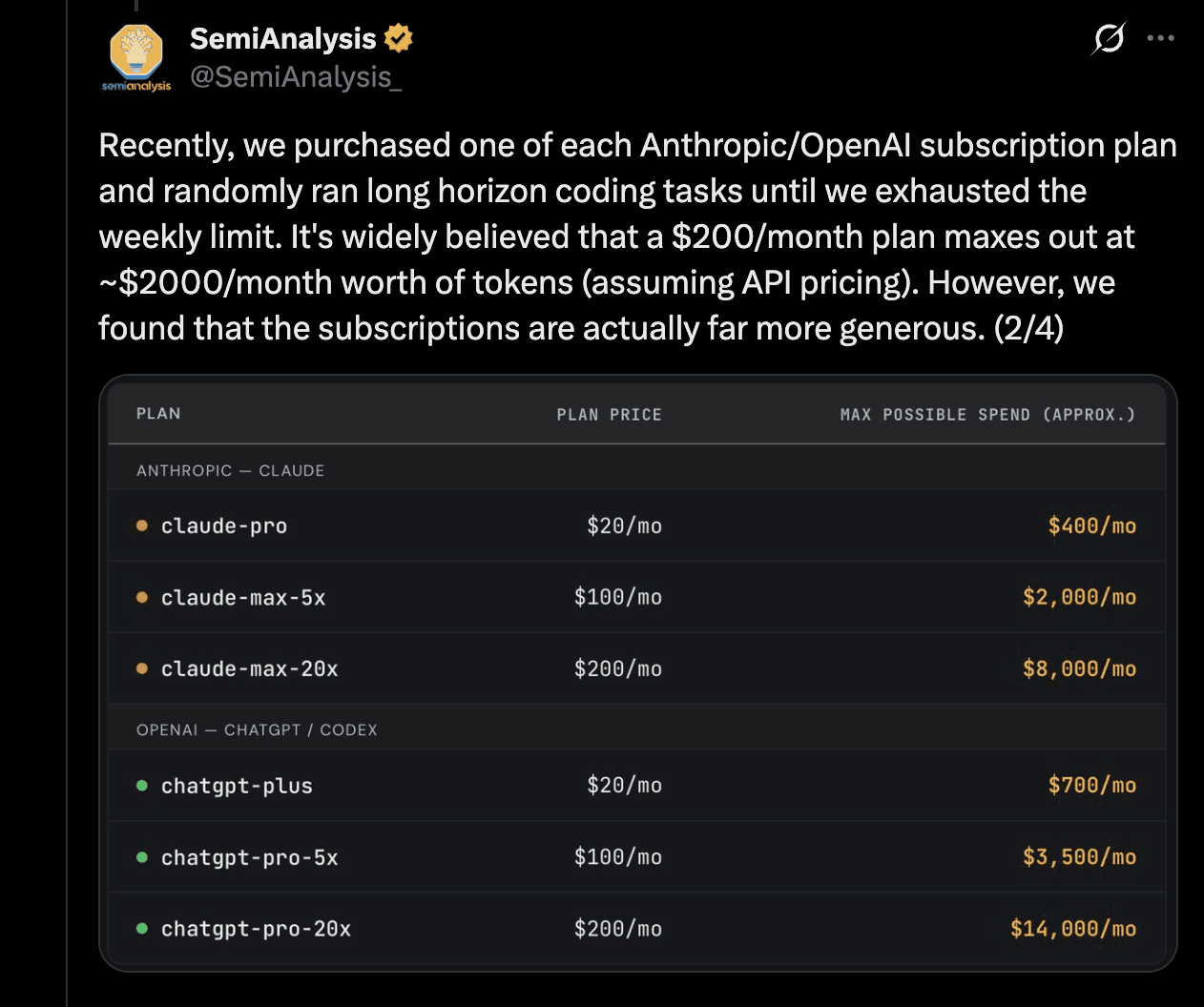
So, what you’re getting right now with Claude Code subscriptions is highly subsidised, and you’re at the mercy of Anthropic.
On the other hand, OpenCode provides much cheaper open-weight models, often at the same cost as the original vendor. It also supports BYOK, so you can use Openrouter, et al.
The pricing in OpenCode is extremely transparent, and they have no incentives to subsidise usage costs.
Winner: Depends
Claude Code if you need state-of-the-art performance, and OpenCode if you want freedom.
You’d have to shell out more with Claude Code, even if you reach the higher real usage limit. So, the base price of Claude Code is still higher.
OpenCode has a low base, is very cheap and affordable, and offers the freedom to switch models.
2. Agent Architecture
Claude Code | OpenCode | |
|---|---|---|
System prompt | One, tuned to Claude + caching | Per model family |
Memory file |
|
|
Migration path | Doesn't read OpenCode's files | Falls back to reading |
History store | In-context, compacted | Raw history in SQLite |
Shell safety | Syntax-tree parse + safety model + OS sandbox | tree-sitter parse, no sandbox |
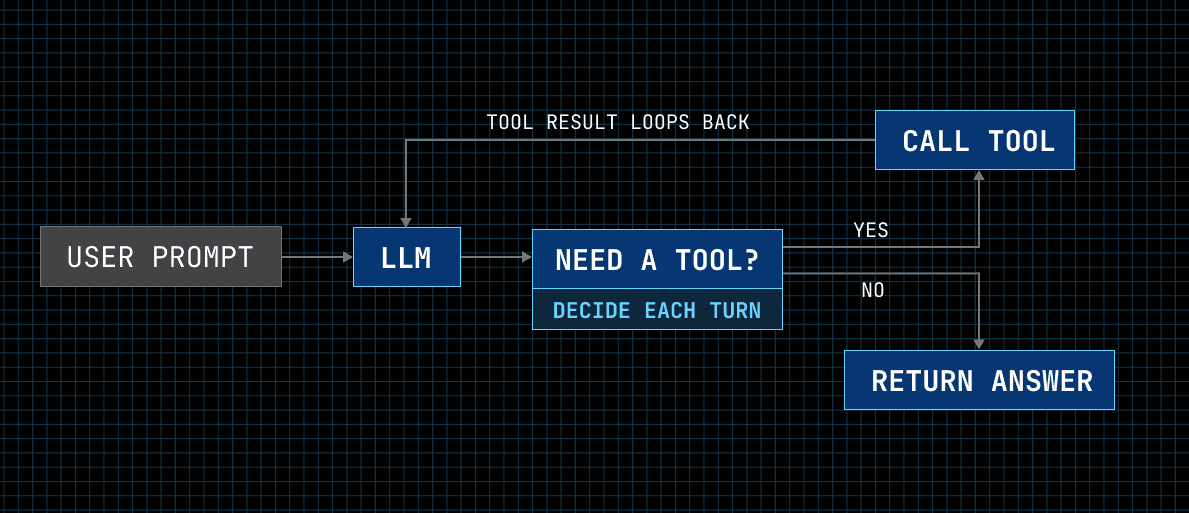
The core loop is the same for all coding agents: based on the user prompt, the LLM calls tools until it's satisfied, then returns the answer. The harness is where they split, and the few places they diverge map onto one root cause: Claude Code owns its model, OpenCode doesn't.
System prompt and caching
Claude Code gets one prompt tuned to how Claude behaves, structured around Anthropic's caching economics: static parts in one cached block and per-session parts in another. Because it's built around Anthropic models, it leans on Anthropic-specific machinery, prompt caching, native tool calls, Claude's own long-context behaviour, so tool definitions, the system prompt, and CLAUDE.md can be cached between turns, which makes long sessions cheaper and faster than re-reading everything each time.
OpenCode can't assume any of that. It reads the model's context limit from provider metadata and builds the session around it, then normalises the weird provider differences, tool-call IDs, cache support, model limits, and tool-calling formats. Claude Code optimises deeply for one model. OpenCode works with everyone and pays the integration tax.
2. Memory: CLAUDE.md vs AGENTS.md
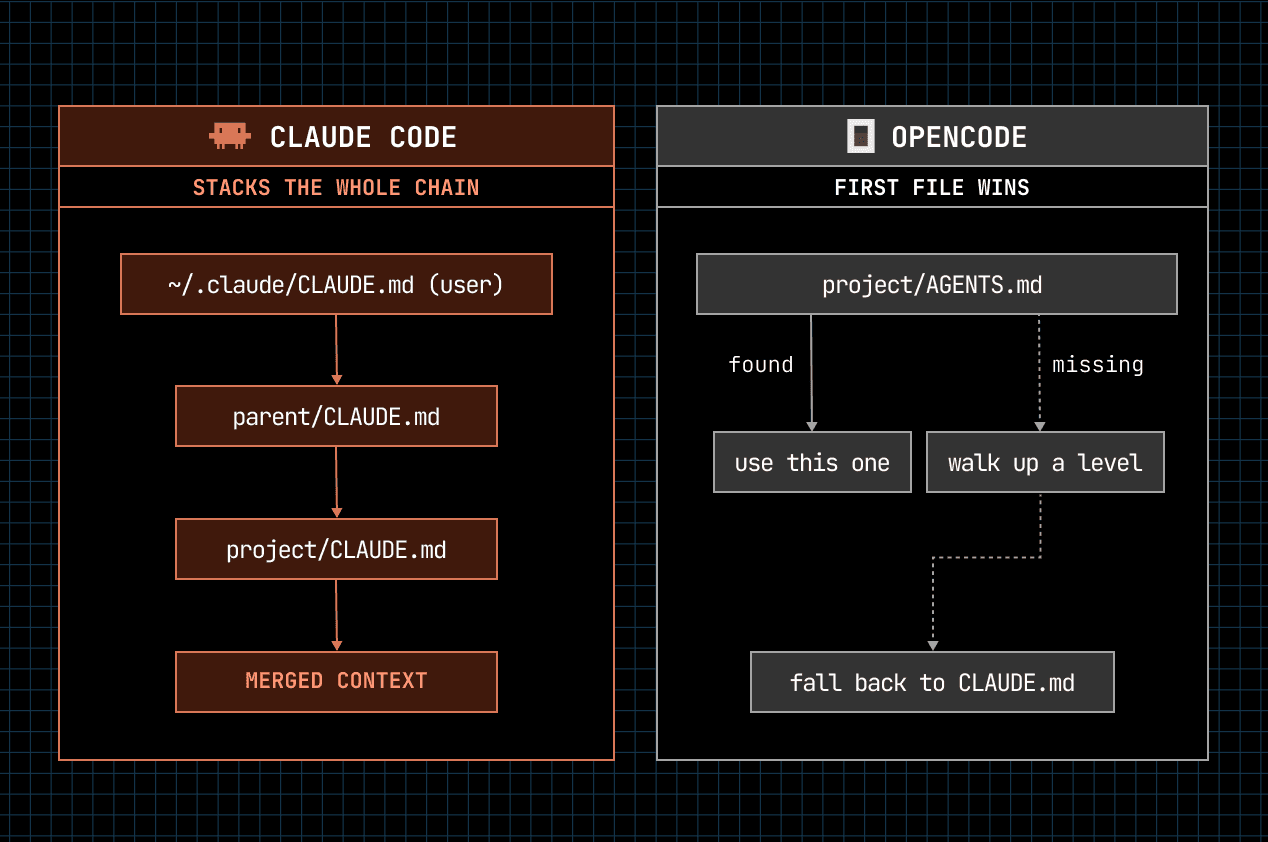
Claude Code uses CLAUDE.md and reads the whole chain, project file, parent folders, user-level, plus auto-memory, and stacks them so the agent feels like it has a built-in memory system.
OpenCode uses AGENTS.md, which is the more portable idea, commit it to the repo, share it with the team, treat it as a vendor-neutral instruction file rather than something tied to one tool. And OpenCode falls back to reading CLAUDE.md if it's there, which makes migrating off Claude Code painless. Claude Code doesn't return the favour.
Running out of context
Both compact when the window fills, but they do it differently. Claude Code clears older tool outputs first, then summarises the session if needed, which is what /context and /compact are for. OpenCode keeps an output buffer, prunes old tool outputs, produces a full summary, and stores the raw history in SQLite, so pruning doesn't lose data. You can get it back.
Safety
Claude Code does the heavy version, multiple layers, allows/asks/denies permission rules, hooks that intercept tool calls before and after they run, and an OS-level sandbox around Bash.
OpenCode parses shell commands with tree-sitter, the same engine NeoVim uses, so it catches risky commands like rm, mv, chmod, or paths outside the project, more carefully than plain string matching. But there's no native sandbox, and it's more permissive by default; you're expected to write the rules yourself in one permission object. The trade is plugins that intercept tool execution directly.
Winner: OpenCode. It's about who holds the keys, and OpenCode hands them to you. AGENTS.md is the more portable memory model, commit it, share it across a team, and it falls back to reading CLAUDE.md So migration is painless. The raw history lives in SQLite, where you can get it back after compaction, the shell parsing is real tree-sitter analysis, and the whole harness is open enough to inspect and reshape. Claude Code's architecture is well-built, the OS sandbox and Anthropic-specific caching are real advantages, and for shipping safely without configuring anything, it's the most convenient box. But convenience is Anthropic's box, on Anthropic's terms. On architecture as architecture, the open, inspectable, you-own-it design is the stronger one.
3. Models: Claude Code vs OpenCode
Claude Code | OpenCode | |
|---|---|---|
Selection | Claude only | Any model, plus a slot for local |
Top model | Opus 4.8 | Whatever you point it at |
Open models | None | GLM 5.1, Kimi K2.6, MiniMax M3, DeepSeek V4, Qwen |
Two-tier? | Yes (hidden Haiku for chores) | Yes (configurable both halves) |
Main risk | No choice | Harness might misread your model |
This is the biggest differentiator here. The two tools are least alike here because one of them is a model company and the other isn't.
OpenCode works with 75 LLM providers. GPTs, Kimi, Deepseek, Minimax, and more. Anthropic has a strict policy against using its models in third-party harnesses such as OpenCode.
In Claude Code, you can only use Claude models, Haiku, Sonnet, Opus, etc.
However, you cannot use Claude subscriptions within OpenCode. Anthropic has strictly prohibited any third-party providers from using Claude Pro and Max subscriptions. Though you can use their API, which will cost you way more.
So, if you love Opus, just use Claude Code and if you want to save money, use the best open-weight model with OpenCode.
Winner: Claude Code with Opus
Claude simply has the best models for coding tasks. Given that you have to use the Claude API with OpenCode to access those, it can be insanely expensive.
But you get a vast number of open-weight models to compensate for that.
4. User experience and surface area
Claude Code | OpenCode | |
|---|---|---|
Surfaces | Terminal + desktop app + VS Code/JetBrains | Terminal-first (+ desktop, IDE ext) |
TUI engine | TypeScript single process | OpenTUI (Zig core + Bun) |
Render quality | Solid, functional | Best-in-class, 60fps+ streaming |
Theming | Limited | JSON themes, live |
Selection |
|
|
Claude Code: meets you everywhere
Claude Code's advantage is breadth. It runs in the terminal, the desktop app, and as VS Code and JetBrains extensions, so it meets you wherever you already work. Selection is by alias (opus/sonnet/haiku/best) or full model name, there's a hybrid opusplan alias that plans with Opus and executes with Sonnet, and a 1M-token context option on Opus 4.6+ and Sonnet 4.6. It's not the prettiest terminal in the category, but it's the one you can use without leaving your editor.
OpenCode: the best terminal UI going, and they built the engine to prove it
The team hit a wall with Ink, the standard React-for-terminals library, which caps at 30fps and eats 50MB+ for even basic apps, fine for a static dashboard, crippling for a streaming agent where the interaction feels laggy.
So instead of living with it, they built and open-sourced OpenTUI, a rendering core written in Zig with a Bun runtime, offloading rendering to native code to escape the FPS cap and the memory bloat.
On top of that sits a real layout engine (Flexbox via Yoga, so the interface reflows to terminal width, sidebar on wide terminals) and a first-class theme system, JSON themes switchable live with/theme, including a system theme that adapts to your terminal's own colours.
Plus, polish you don't expect in a terminal, mouse support, smooth scroll acceleration, and sound notifications. It pushed the TUI ceiling for everyone, since the rest of the ecosystem now uses the engine it spun out.
Winner: Claude Code, on surface area.
OpenCode wins the TUI outright; it's the best-looking, best-engineered terminal in the category, and it built the rendering engine to get there, no contest on craft. But UX isn't only the terminal. Claude Code runs in the terminal, the desktop app, and as VS Code and JetBrains extensions, so it meets you wherever you already work, and that reach matters more to my actual day than render quality does.
OpenCode does ship a Tauri desktop app, too, so it's closing the surface gap, but Claude Code is still the more versatile where-you-can-use-it tool. If you live entirely in the terminal and care how it feels, OpenCode is the nicer place to spend your day. If you bounce between terminal and IDE, Claude Code's breadth wins, and that's most people, including me.
5. Reliability
Claude Code | OpenCode | |
|---|---|---|
Failure mode | Changes under you on release | Silent break at model/harness seam |
When it fails | Across versions, no warning | Mid-run, until you notice |
Can you fix it? | No lever, no pin, no rollback | Pin a tested combo, harness is open |
Documented case | Spring 2026 regression (AMD GitHub issue) | DeepSeek V4 Pro protocol mismatch |
Claude Code was recently caught in a fire for deliberately nerfing the Opus in Claude Code.
In April 2026, Stella Laurenzo, a senior director in AMD's AI group, filed a public GitHub issue arguing that Claude Code had badly regressed. She backed it with an analysis of roughly 6,852 session files and 234,760 tool calls. One figure stood out: before the regression, Claude read about 6.6 files per edit; afterwards, just 2.0.

The issue was so widespread that multiple users expressed strong dissatisfaction with Claude’s degraded performance.
This Reddit mega thread has summed up all the performance bugs.
Anthropic's postmortem, published later that month, conceded the problem was partly baked into the product layer itself—a 3% drop in coding quality across Opus 4.6 and 4.7 traced in part to a single system-prompt instruction telling the model to keep text between tool calls under 25 words. A harness change quietly degrades the model, with no way for users to see it or switch it off.
You will not encounter anything like this in OpenCode, since all the models are open-weight and can be swapped with models from other providers.
The pinning problem, and a bit of recent relief
After Opus 4.7 shipped, CLAUDE.md files tuned for 4.6 suddenly produced hedged or argumentative output. The most requested feature among developers who have lived through both regressions is model version pinning, and Anthropic still hasn't shipped it.
The recommended workaround is almost funny: keep your own eval suite, run it after every release, have a rollback plan, exactly the discipline you'd apply to a flaky open model, except you don't get to choose when the thing changes.
There's been some relief on the adjacent pain: the usage wall. On May 6, Anthropic announced a compute partnership with SpaceX, doubled Claude Code's 5-hour limits for Pro, Max, Team, and seat-based Enterprise, and removed peak-time limits for Pro and Max.
That makes day-to-day flow-breaking less frequent, but it doesn't address the core complaint; you still can't freeze the model you tuned.
Winner: OpenCode.
OpenCode will be more reliable just because you can use models of your own choice. You can test the model on your eval and run it as long as you want. The model won’t regress.
Claude Code, with its history of frequent unannounced changes, can be really annoying to deal with.
6. Extensibility: Plugin, Skills, Sub-agents
Claude Code | OpenCode | |
|---|---|---|
MCP | Yes (shared, portable) | Yes (shared, portable) |
Skills | Markdown, on-demand | Markdown, on-demand |
Packaging | Plugins + official marketplace | npm/local modules, community dir |
Subagents | Built-in (Explore/Plan/general) + custom | Real SQLite child sessions, inspectable |
Depth of hooks | Bolt tools on | Rewrite compaction, intercept everything |
Both tools converge here more strongly than anywhere else: same primitives, MCP, skills, hooks, custom tools, subagents. They support the same things, so the difference is in what each built on top.
The shared layer (MCP + skills)
Both support MCP, both take local and remote servers, and both register the server's tools into the toolbelt. Long-term, that's the part that pays off, because your integrations don't live in the agent; they live in the MCP servers you plug in, and those are portable; a GitHub, Linear, or Sentry connector moves with you.
Which is roughly where Composio sits, an agent-agnostic connector layer you set up once and call from whatever terminal agent you're in; MCP means it doesn't care which one you opened today. Your leverage sits in what you've made callable, not in the agent you happened to pick. Skills are the same on both; markdown files are loaded on demand when a task matches.
Subagents: clean vs inspectable

Both delegate in the same way; the parent calls a Task/task tool, a child agent spins up with its own context, prompt, tools, and permissions, does the work in isolation, and returns one final message. Claude Code has the more polished version, built in Explore, Plan, and general-purpose agents plus custom ones in .claude/agents/ with YAML front matter (you can point repo search at a fast Haiku-style agent and code review at a stronger model).
OpenCode's version is more transparent: it stores subagents as real child sessions in SQLite, with their own messages, permissions, and snapshots that you can inspect after the fact, rather than hiding the delegation within a prompt.
Skills are the same. These are just markdown files for repeated workflows. You can drop Claude Code Skills in OpenCode, and it will work.
Related: Best OpenCode Skills
Plugins: Claude Code vs OpenCode
It built a distribution layer. Claude plugins are a real package with a manifest bundling skills, agents, hooks, MCP servers, LSP servers, and monitors into one installable thing, with an official marketplace in the tool, browse with a slash command, and install with one line.
The polished, productized version. Anthropic's docs warn that plugins are highly trusted components that run code with your privileges, the supply-chain tradeoff of any real marketplace.
The OpenCode plugins ecosystem is not as mature as Claude’s, but there are some really good OpenCode community plugins coming up
Plugins are just JavaScript/TypeScript modules you drop in a folder or pull from npm, no manifest, community directory rather than a store.
But they reach further, hooking lifecycle events before and after every tool call, chat parameters, shell environment, file edits, permissions, and the compaction step.
Winner: Claude Code.
Claude Code has the most mature ecosystem of the bunch: a marketplace, skills, and a hook system deep enough that people describe building on it as programming the agent rather than configuring it. If you want to install extensibility, a front door and a thousand things to grab, that's Claude Code, at the cost of it being Anthropic's front door.
Which one to pick?
Pick Claude Code if:
You want the agent to just work without needing to tune a setup.
You're already paying for Claude Pro, Max, or access to the Anthropic API.
You want the highest raw quality on hard reasoning, and you trust Anthropic's models.
You bounce between the terminal and the IDE and want it everywhere.
You'd rather install a plugin than write one.
Pick OpenCode if:
You need model freedom, GPT, Gemini, Kimi, local, one config change away.
You need a fully local execution for privacy or compliance.
You want to pin the exact model-and-provider combo and never have it move under you.
You want to read, fork, or rewrite the harness, including how it compacts.
You live in the terminal and care how it looks and feels.
Conclusion
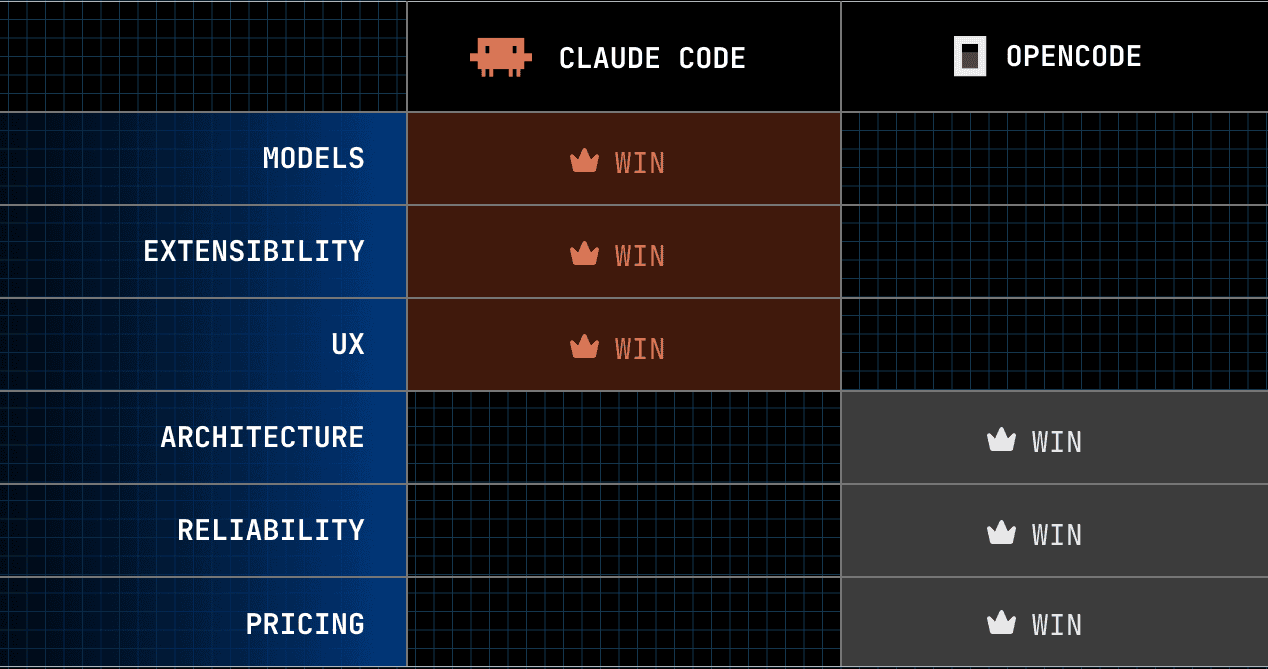
David doesn't actually beat Goliath here, and the scorecard says so plainly; it's 3–3. Every section came down to the same one decision: do you want to own the machine, or do you want it to just work? The whole comparison is that question asked six different ways.
So why is Claude Code still my daily driver when the boxes split evenly? The three it wins, Models, Extensibility, and the surface reach in UX, are the ones I touch every hour: the frontier model on day one, the mature plugin ecosystem, and the fact that it lives in my editor and not just the terminal.
OpenCode wins Architecture, Reliability, and Pricing, and those are real; I just feel them less in a normal day's work than I feel having Opus 4.8 the morning it ships. A 3–3 tie comes down to which three matter to you.
For me, it's Claude Code's three. The price is being a passenger, the 4.7 regression made that real, and there's still no pin to stop it from happening again.
But, I guess,
“Mama, I am in love with a criminal
And this type of love is not rational, it’s material” — Britney Spears
So pick by temperament, not by the tally. If your instinct reading this was "I just want to write code on the best model and get on with it," Claude Code. If it was "wait, can I override that, pin that, run that one for a tenth of the cost," OpenCode. And whichever you open today, keep your real leverage in the MCP layer they both share, because the agent underneath is swappable, and the connectors you build are what move with you.