Recently, within a month, we've been amazed by all these new AI models from three giants: OpenAI, Google, and Anthropic!
From Anthropic, we have Claude Opus 4.5 (with the highest SWE Benchmark 80.9%); from OpenAI, their flagship coding model GPT-5.2 (Codex) with SWE Benchmark 80%; and from Google, Gemini 3 Pro, which at launch was said to be SOTA in most benchmarks and boasts advanced agentic capabilities.
The catch here is that there are so many models available for coding or agentic coding that it's hard to decide which one to pick as your daily driver.
All of them claim at some point to be the "so-called" best for coding. But now the question arises: in actual agentic coding, which involves working on a production-ready project, how much better or worse is each of them in comparison?
TL;DR
If you want a quick take, here’s how the three models performed in these two tests:
Claude Opus 4.5: Safest overall pick from this run. It got closest in both tests and shipped working demos, even if there were rough edges (hardcoded values, weird similarity matching). Also, the most expensive.
Gemini 3 Pro: Best result on Test 1. The fallback and cache were actually working and fast. Test 2 was weird; it kept hitting a loop, which resulted in halting the request.

GPT-5.2 Codex: Turned out to be the least reliable for me in these two tasks. Too many API and version mismatches, and it never really landed a clean working implementation.
One thing I really hate about Opus in Claude Code is how much it does web searches. Across these two tests, it did like 30+ web searches, which ended up eating up a big part of the total time. Web search is great, but it gets super frustrating fast when you have to keep approving it and typing “Yes” over and over.
Has anybody else felt this with Claude Code, especially Opus 4.5?
⚠️ NOTE: Don’t treat these as a hard rule. This is just two real dev tasks in one repo, and it shows how each model did for me in that exact setup.
Test Workflow
For the test, we will be using the following CLI coding agents:
Claude Opus 4.5: Claude Code (Anthropic’s terminal-based agentic coding tool)
Gemini 3 Pro: Gemini CLI (an open source terminal agent that runs a React-style loop and can use local or remote MCP servers)
GPT-5.2 Codex: Codex CLI (OpenAI’s Codex agent in the terminal)
We will be checking the models on two different tasks:
Task 1: Production feature build inside a real app
We drop each model into the same working codebase and ask it to ship a production-ready feature, wire it into the existing flows, and add tests. The goal here is simple: can it navigate a repo, make safe changes across multiple files, and leave things in a shippable state?
We’re using a real production-style repo: a Next.js Kanban board with auth, localisation via Tolgee, and an AI task description generator powered by the Vercel AI SDK, plus a Docker setup to spin up the database locally. So you can assume this is a decently sized project with many features, sufficient for our test.
If you’re curious, you can check it out here: shricodev/kanban-ai-realtime-localization
Task 2: Build a tool-powered agent using the Composio Tool Router
💁 To build the agent, we will be using Composio’s Tool Router (Stable), which automatically discovers, authenticates, and executes the right tool for any task without you having to manage auth or hand wire each integration. This significantly helps reduce the MCP context load on the model.
We’re dogfooding it here because Tool Router has just moved from its experimental phase to a stable release, so this is the exact moment we want to stress-test it in the real world.
We’ll compare code quality, token usage, cost, and time to complete the build.
Coding Comparison
Test 1: Feature Build in a Production App
The task is simple: all the models start from the same base commit and then follow the same prompt to build what's asked.
I will evaluate the final result from the "best of 3" responses for each model, so we won't be evaluating based on an unlucky dice roll.
Here's the prompt used:
You are a coding agent working inside an existing repository.
Repo context
- Repo: shricodev/kanban-ai-realtime-localization
- Goal: Implement Test 1 (AI description fallback + caching) in a production-quality way.
- Constraints:
- Do not add new dependencies unless truly necessary.
- Keep changes minimal and consistent with repo style.
- Must integrate into the existing AI task description feature path.
- Add tests for any new pure logic.
Rules
- You may read and edit files and run terminal commands.
- After implementing, run: npm run lint and npm run build and fix failures until both pass.
- Output a final checklist with files changed, commands run, and how to verify manually.
Feature requirements (Test 1)
1) Add a deterministic local fallback for AI task description generation when OpenAI credentials are missing OR the external call fails.
2) Add a 10-minute in-memory cache keyed by (taskTitle + language) so repeated generations do not call the external model repeatedly.
3) Ensure the UI does not break when AI is unavailable. The user should still be able to create and save tasks.
4) Add unit tests for the fallback generator and cache behavior.This is a bit involving; the model needs to add a local fallback, use an in-memory cache, fix some UI issues and finally write unit tests for all that it implemented in the Next.js project.
Claude Opus 4.5
Claude went all in, starting with the fallback implementation, then writing tests and running the build until it fixed all the build and lint issues.
The entire run took about 9 minutes, which is fair given all the features we asked it to build, the tests we added, and the iterations required to fix it.
Here's the code it generated: Claude Opus 4.5 Code
It wrote two tests for both features as explicitly asked, which pass as well:
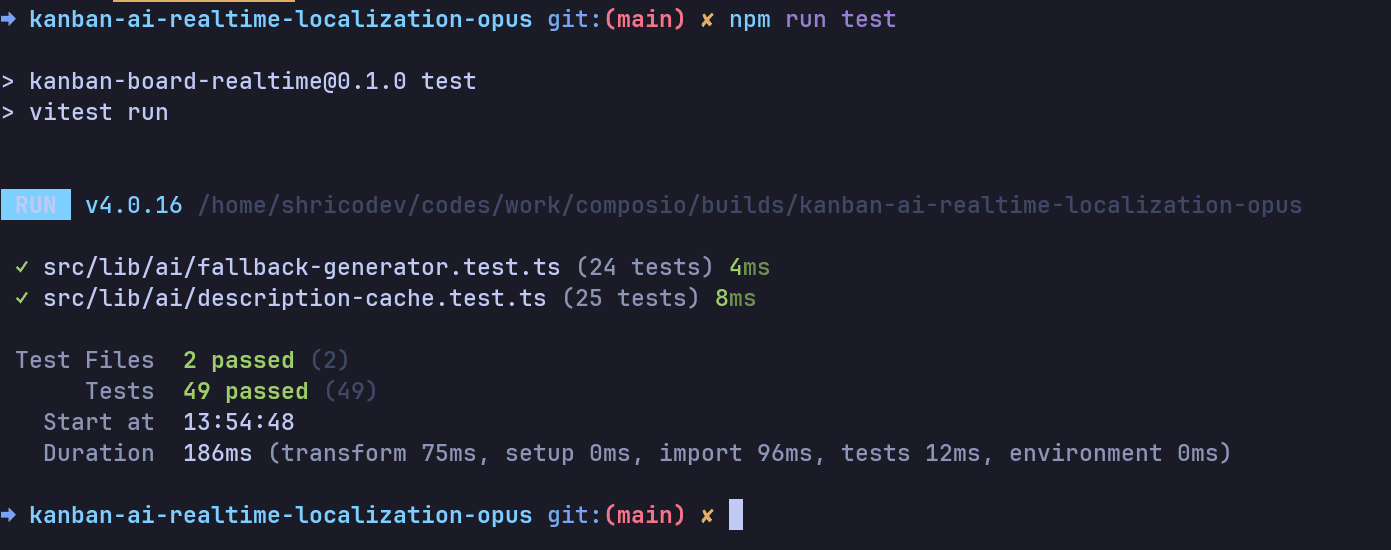
Now, the time is to test, and when I ran the test, part of what was asked is implemented. The UI does not break when AI is unavailable, but for the in-memory cache for the same task title, cache hits but does not get populated in the field:

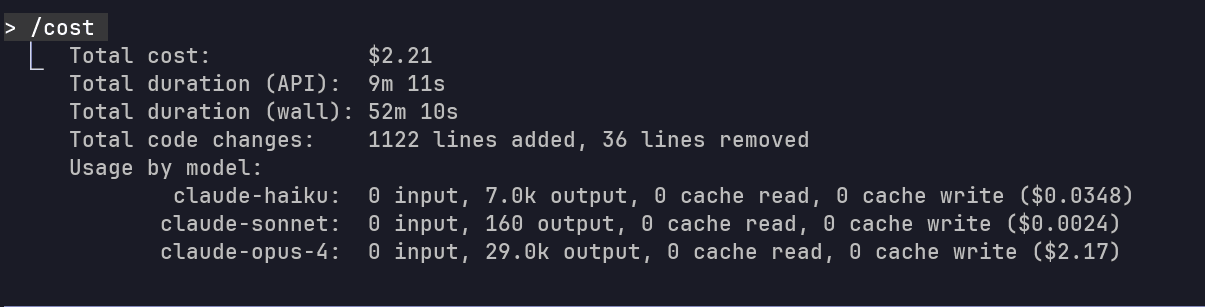
The overall result is partially correct, compiles, and runs successfully. And here's the overall token usage and cost from Claude CLI for your reference:
Cost: $2.21
Duration: 9min 11sec (API Time)
Code Changes: +1,122 lines, -36 lines
GPT-5.2 Codex
GPT-5.2 Codex took about 7min 34sec coding the implementation, and an additional 55sec for working with the implementation unit tests. It is shorter than the time it took Opus 4.5 to implement the feature entirely.
Now is the time to test it. The result turned out even worse; it's using an older version of the API or some unexported code. Warnings everywhere!

and even some exceptions in places.

Here's the code it generated: GPT-5.2 Code
None of the requested features works. Some are not implemented, and some have very fragile implementations.
Seriously disappointed with the model's response :(
Cost: $0.9 (ballpark for API users)
ℹ️ It's included in the plan for subscription users.
Duration: 7min 34sec (+55 sec)
Code Changes: +203 lines, -32 lines
Token Usage: total=269,195 input=252,810 (+1,560,192 cached) output=16,385 (reasoning 8,704)
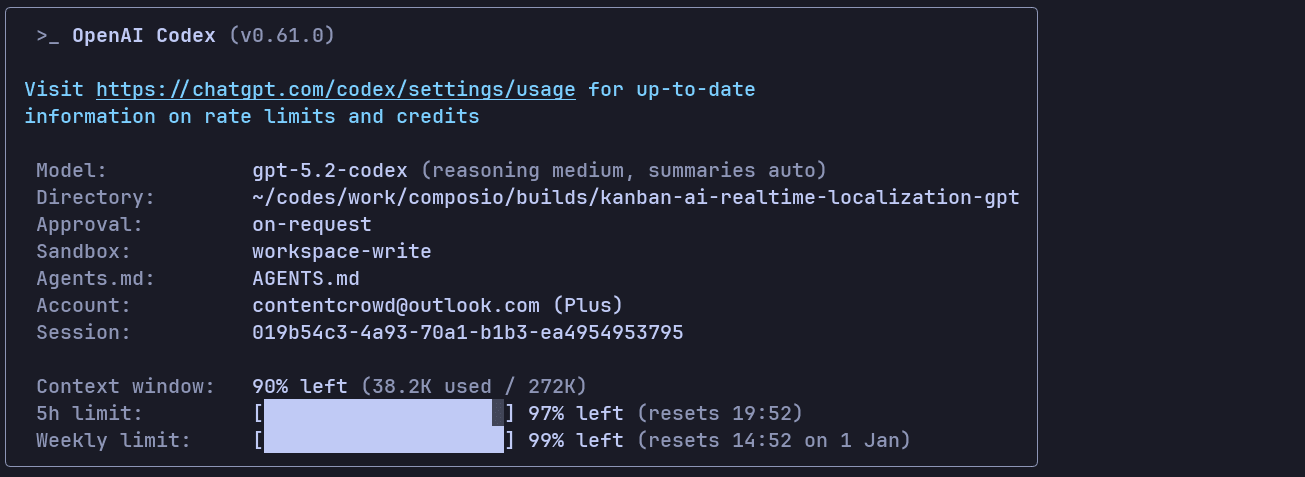
Here's the model /status of the run:
Gemini 3 Pro
This turns out to be the fastest of all, with a total time of 7min 14sec (5min 23sec API time and 1min 51sec Tool time).
The test runs successfully, and even the fallback error is handled properly.
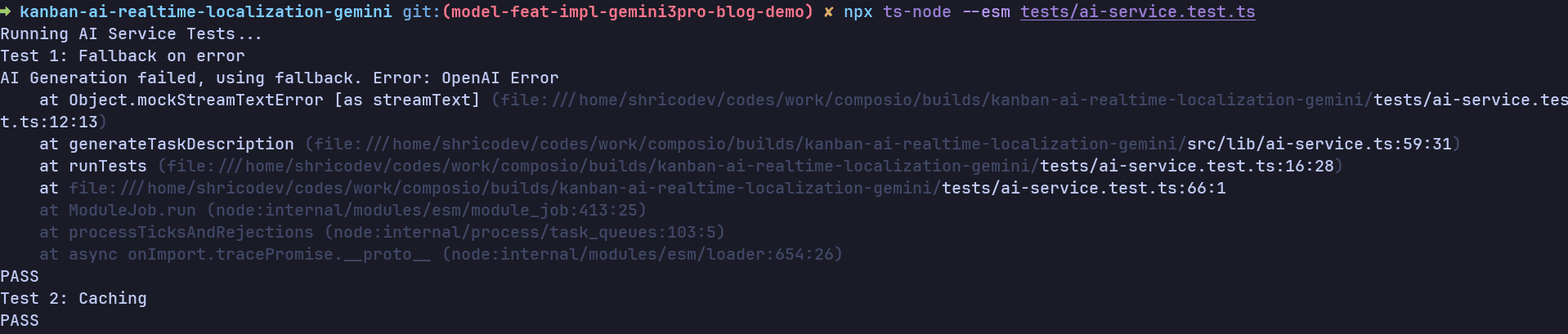
Now, it's time to test the actual implementation. Surprisingly, Gemini 3 Pro got this task done the best.

As you can see, the same request in the second or third run returns the response instantly in 6-7 milliseconds from the cache implementation.
The final implementation is fully working, compiles, and runs successfully.
Cost: $0.45 (approximate)
Duration: 7min 14sec (5min 23sec API time, 1min 51sec Tool time).
Code Changes:
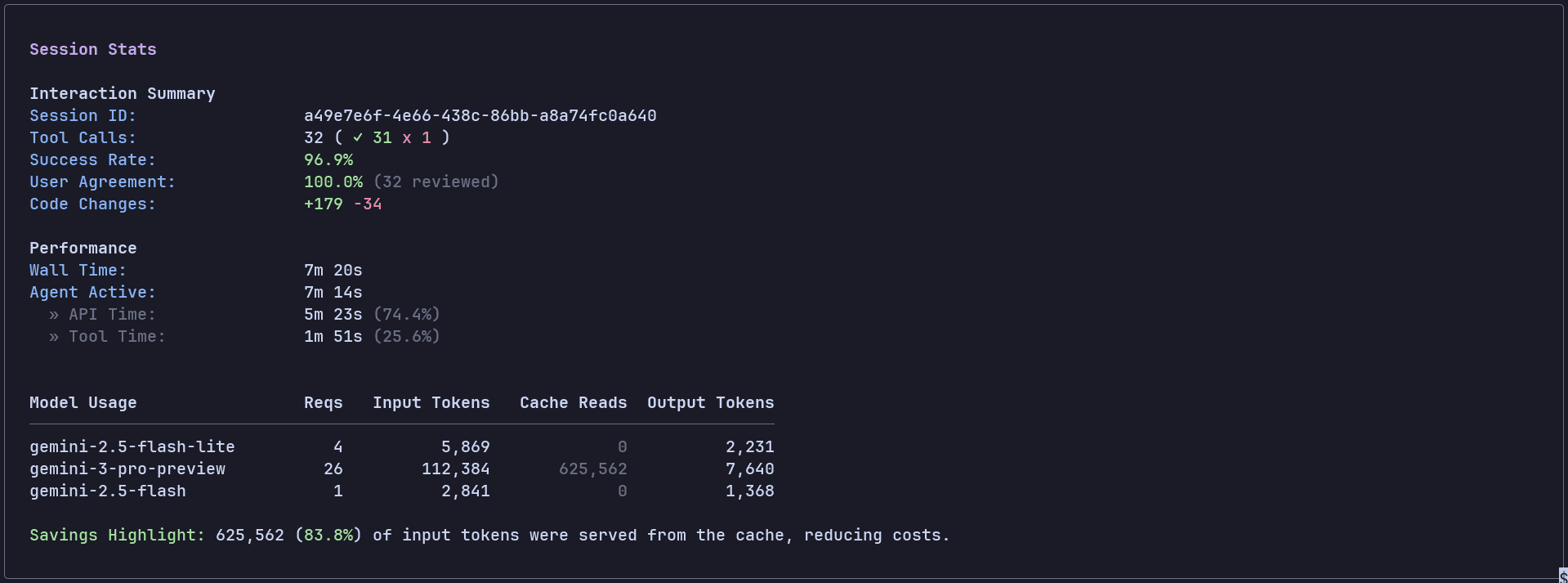
Token Usage: 746K (input + cache read), 11K output
Here's the model /usage of the run:
Test 2: Tool Router Agent Build (GitHub Triage)
For this, we will build everything on top of our Kanban repo, keeping the concerns separated.
ℹ️ As I said, this is a real test for these models, to see how well they can organize things, separate concerns, and manage the overall project build.
Since the prompt is a bit longer, I've linked it separately. You can find it here: Tool Router Agent Build Prompt.
Let's start off with Opus 4.5, the model with the highest SWE and many other benchmarks.
Claude Opus 4.5
Opus got the Tool Router triage demo working end-to-end inside the Kanban repo (kept under /labs as we requested). It spins up a Tool Router session with GitHub and returns a real issue URL, which is a solid outcome for dogfooding Tool Router now that it has moved out of beta into the stable release.
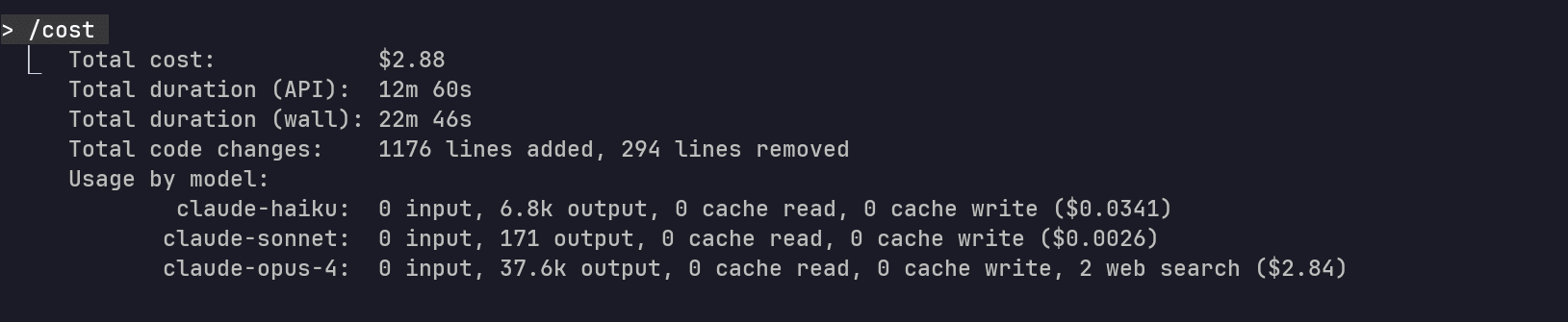
The run stats from Claude Code:
Cost: $2.88
Duration: 12min 60sec (API), 22min 46sec (wall)
Code Changes: +1,176 lines, -294 lines
Here's the code it generated: Opus 4.5 Agent Build Code
Here's a demo:
That said, it is not perfectly implemented:
Hardcoded tool names: It's hardcoding specific tool names explicitly. What if the tool names change in the future? The code breaks immediately, defeating the entire purpose of using a router.
Similarity matching is weird: Even with the exact same issue title, it fails to flag an issue as a duplicate.
and there could be many more...
Still, this is a great head start. The demo works, the UI is there, and it’s close enough that a couple of fixes could make it workable, and genuinely this is a great start.
GPT-5.2 Codex
In the first run, the model gave a decent response with a decent UI, but I noticed it uses the old version of the Composio API.

Now, this is going to be a test where the model is tested explicitly without much human help. I thought to give this an update on how to use the new API, but it still resulted in an error:

Even more weird is that, even though the request failed, the API returns 200 OK, which is insane. From this point onward, I stopped, as this does not seem to be fixing anytime soon.
Here's the code it generated: GPT-5.2 Agent Build Code
Here are the run stats from GPT-5.2-Codex:
Duration: 5 min 15 sec (+20 sec attempted fix)
Code Changes: +1,682, -86
Token Usage: total=201,382 input=186,265 (+432,640 cached) output=15,117 (reasoning 6,912)
Gemini 3 Pro
Now, this turned out even weirder. Almost every other time, it kept hitting a "potential loop" after about 13-14 minutes of runtime with incomplete code.
The run usually resulted in the following loop, which eventually halted the request
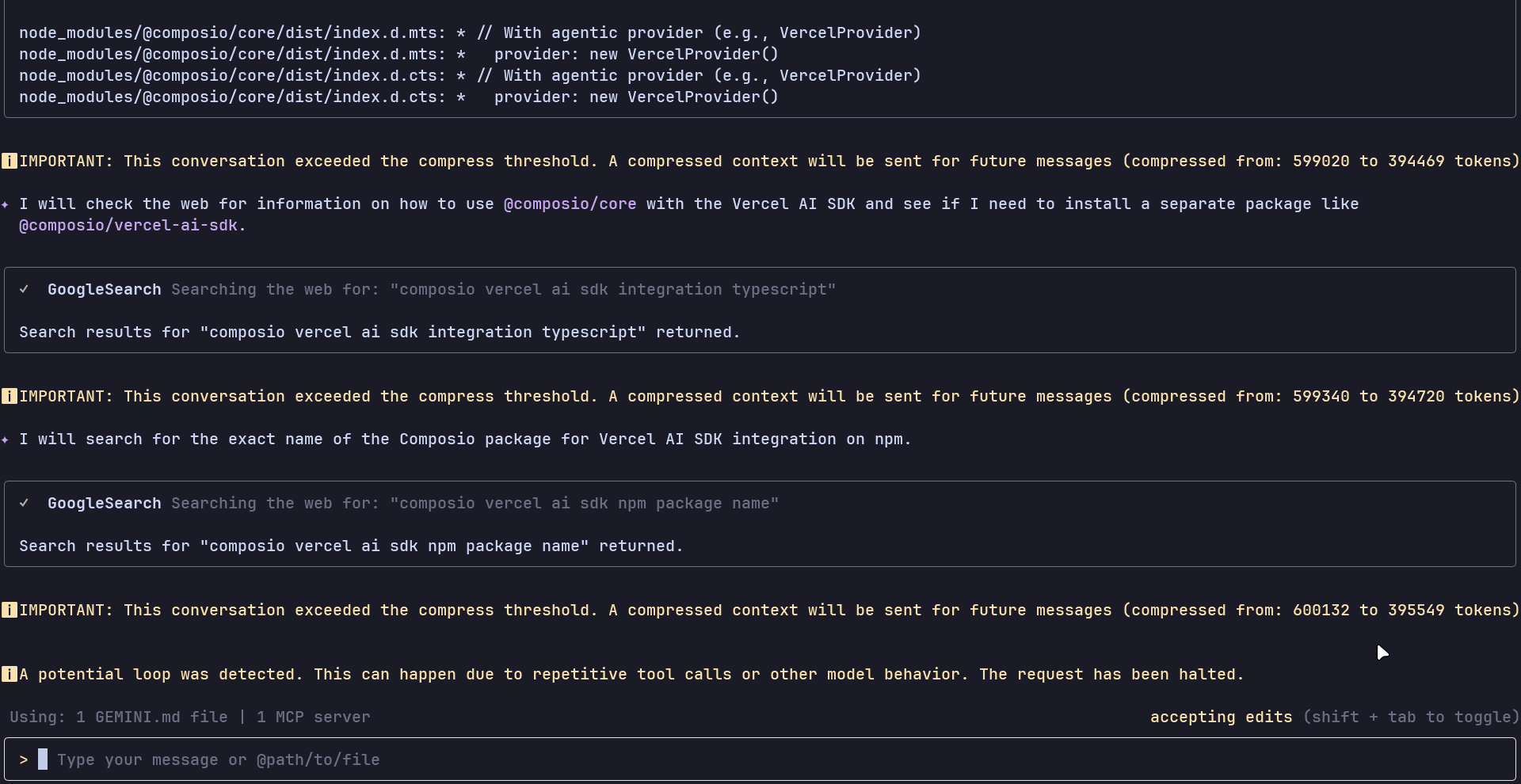
Cost: $6.3 (approximate)
Duration: 14min 7sec (API), 30min 7sec (wall)
Token Usage: 12,622,153 (input + cache read), 24K output
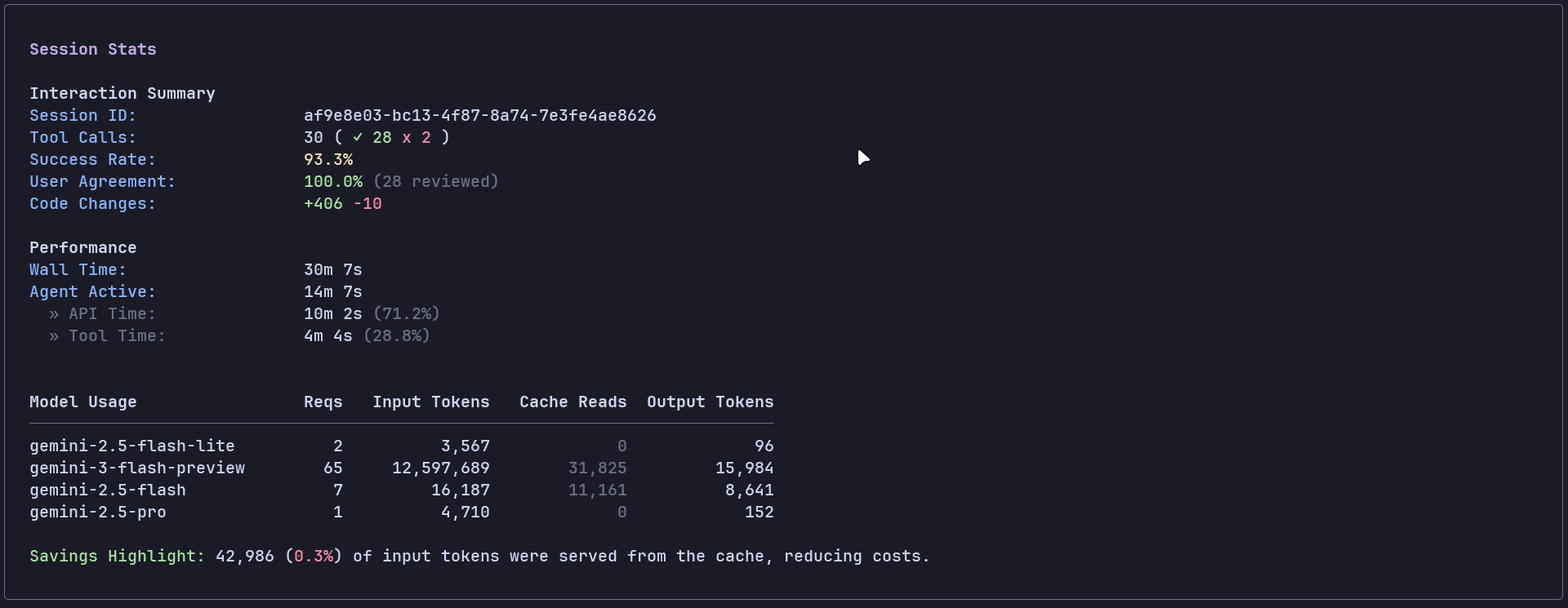
I couldn't even get the final build of the project, and it just cost me money with no usable output. Disappointing!
Final Thoughts
From this test, Opus 4.5 definitely takes the crown. But I still don’t think we’re anywhere close to relying on it for real, big production projects. The recent improvements are honestly insane, and they are only going to improve. Also, for Opus, cost will always be a concern; if they find a way to get performance while reducing cost, it will actually be over for other models.