Gemini 3 Pro just dropped, and it is already getting a lot of attention for its reasoning and long context abilities.
But now, the natural question is, "How well does it code?"
And does it actually outperform GPT 5.1 Codex, which, in my tests, has been the best so far (better than Claude 4.5 Sonnet) on real tasks?
To find out, I put it side by side with GPT 5.1 and tested both models on two fundamental tasks: a UI build and a complete agent workflow.
We will go through the results in a moment, but first, let's have a quick TL;DR and a refresher on Gemini 3.
TL;DR
If you want a quick take, here is how both models performed in the test:
Gemini 3 Pro handled both the UI task and the agent build more cleanly, requiring very few follow-ups.
The most significant difference showed up in the agent test, where Gemini 3 Pro actually followed the documentation and built it well. At the same time, GPT-5.1 had a few issues with the agent implementation.
Even though in our test it's not very obvious, for everyday coding, Gemini 3 Pro feels like the safer bet.
Latency is higher than GPT-5.1 and can be frustrating for minor fixes.
If you are doing real coding or building agents, Gemini 3 Pro is the better choice right now.
⚠️ NOTE: The goal of this test is to show how much of a jump Gemini 3 Pro is compared to the best models we had before its release.
Brief on Gemini 3 Pro
Gemini 3 is Google's most intelligent model family to date, and is the state-of-the-art (SOTA) across a variety of benchmarks.
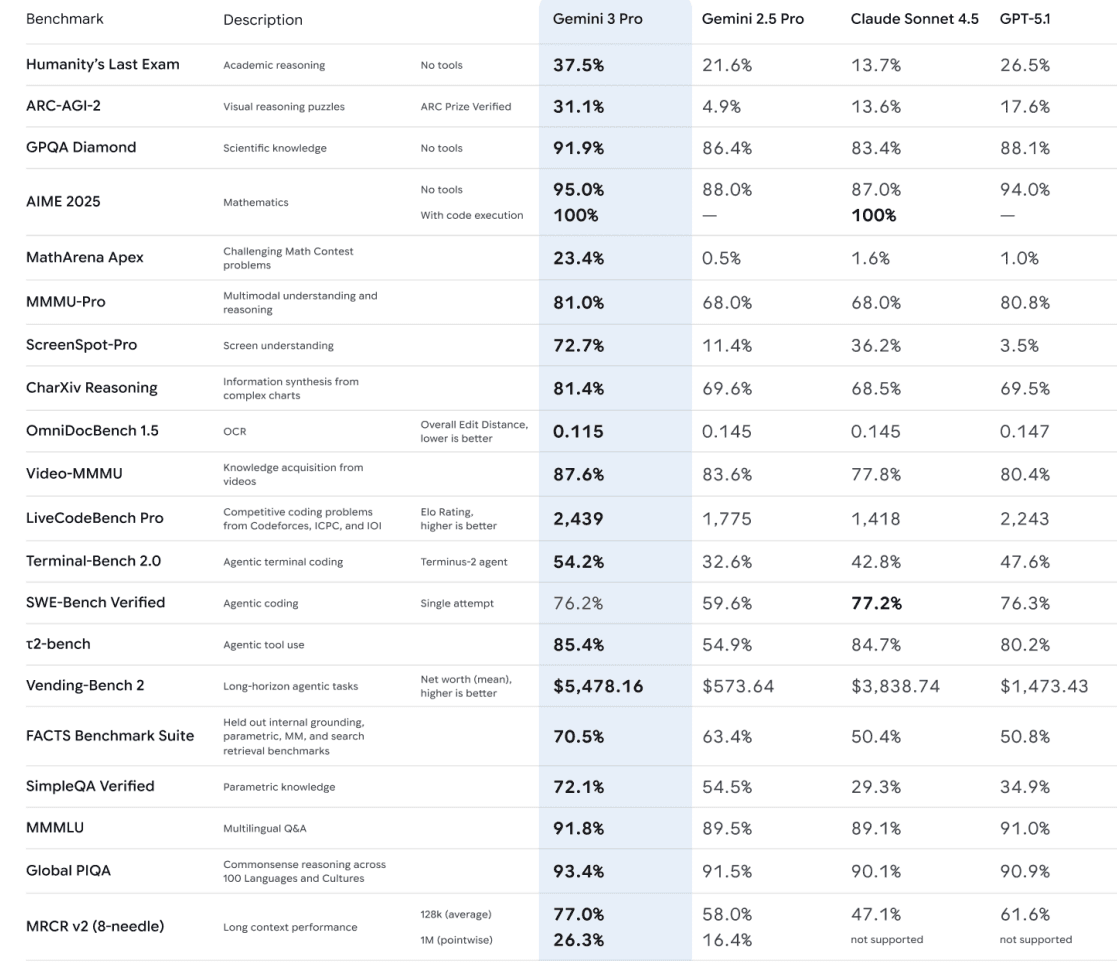
As you can see, this model makes almost all the models we had till now, including GPT-5.1, Claude 4.5 Sonnet, look outdated. The difference in their stats is just insane.
From these, here are the ones I find the most incredible:
LMArena Elo: 1501 (crossing GPT-5.1 and Claude Sonnet 4.5)
Humanity's Last Exam: 37.5% without tools (hardest AGI benchmark available)
GPQA Diamond: 91.9% (PhD-level science reasoning)
AIME 2025: 95% (high school mathematics)
MathArena Apex: 23.4% (new state-of-the-art)
"Gemini 1 introduced native multimodality and long context to help AI understand the world. Gemini 2 added thinking, reasoning and tool use to create a foundation for agents.
Now, Gemini 3 brings these capabilities together – so you can bring any idea to life."

So, it's built by putting together the good sides of the earlier Gemini models.
Talking about its specs, it comes with a huge 1M input token context window and an output token limit of 64K.
🤔 What's the difference from Gemini 2.5 Pro?
Specs are almost the same. Both 2.5 Pro and 3 Pro give you about a 1M input window, 64K output and full multimodal support. But Gemini 3 Pro is a clear upgrade in how it thinks with that context. It scores roughly 10 to 20 per cent higher on many reasoning benchmarks, takes a massive jump on complex tests like ARC-AGI-2 and SimpleQA, and performs better at long-context retrieval at the 1M scale.
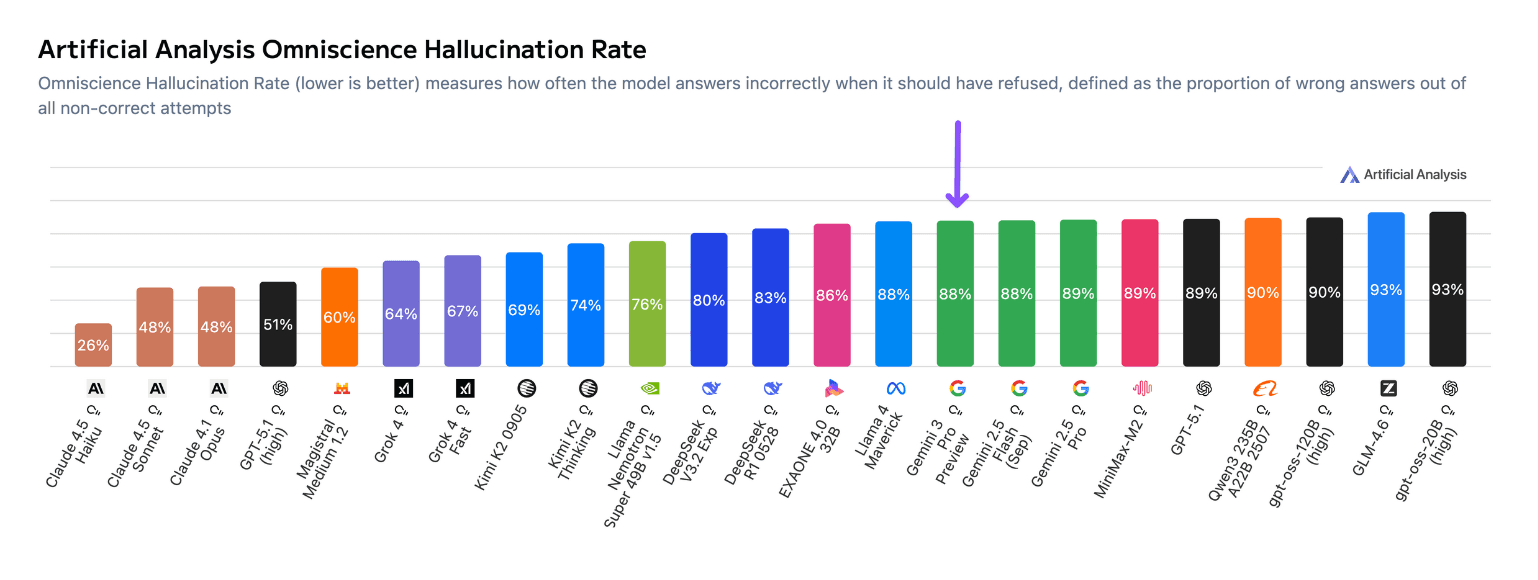
There's just a percentage improvement in hallucination rate compared to Gemini 2.5 Pro, and Claude leads by a significant margin on this metric, which should've been better. We will test it shortly.
Google is also clearly tuning this thing for real "agent"- style workflows, not just limited to chat. In practice, that means Gemini 3 Pro is built to run tools, browse, execute code, and integrate into your agentic workflows. As said, it's available everywhere; you can find it in all Google products.
Google has launched it everywhere, so you can already get the idea of how confident they are in this model.

Google has also launched Deep Think Mode alongside Gemini 3 Pro, which isn't public yet, but it uses extended reasoning chains to work through complex problems. It's like taking a moment to think before answering user questions. It offers improvement over the raw Gemini 3 Pro.
Humanity's Last Exam: 41.0% (vs. 37.5% with standard Gemini 3 Pro)
GPQA Diamond: 93.8% (vs. 91.9% with Gemini 3 Pro)

They are running safety checks before the public release to ensure it isn't misused.
To learn more about the model, see its model card here: Gemini 3 Pro Model Card.
Coding Comparison
Now, let's start with the coding test. We will be comparing Gemini 3 Pro with GPT-5.1 on two tasks.
UI Test: I've already seen dozens of videos and demos praising Gemini 3 for its frontend coding, so we will run one to see how well it handles a basic task.
Building an Agent: We will make an agent from scratch, as it's also a model known to be great at agentic workflows.
1. UI Test - Clone Windows 11
Prompt: You can find the prompt I've used here: Prompt - UI Test
Response from Gemini 3 Pro:
Code generated by Gemini 3.0 generated here: Source Code
Here's the output of the program:
This is by far the best response I've gotten from any AI model to this prompt to date. This is just too good. The overall feel does resemble Windows 11. The choice of icons could have been better, but the overall look and feel are really, really close.
On this question, I'm not looking at how the model implements logic, but rather its pure frontend skills, and this one has done it well. Also, the wallpaper-changing feature is cool and works.
It took about 10 minutes to implement it all. The total output token usage was around 30K, including the README, LICENSE, and a few other document files it generated on its own. So, be careful when using YOLO mode in Gemini CLI.
Response from GPT-5.1 codex:
You can find the code it generated here: Source Code
Here's the output of the program:
This is super close to Gemini's implementation, but there's a lot of stuff that feels missing and could be improved.
Even though the look and feel of the output from Gemini 3 Pro is much better, the code for this question by this model is better than that of Gemini 3 Pro. If you look into how it's structured, how types are declared, and all that, this is much better.
2. Building a Calendar Agent
To build the agent, let's use something different. This time, we will be using Composio's Tool Router (Beta), which automatically discovers, authenticates, and executes the right tool for any task without you having to manage authentication and wire everything per integration. 🔥
💁 Prompt: You can find the prompt I've used here: Prompt - Agent Coding
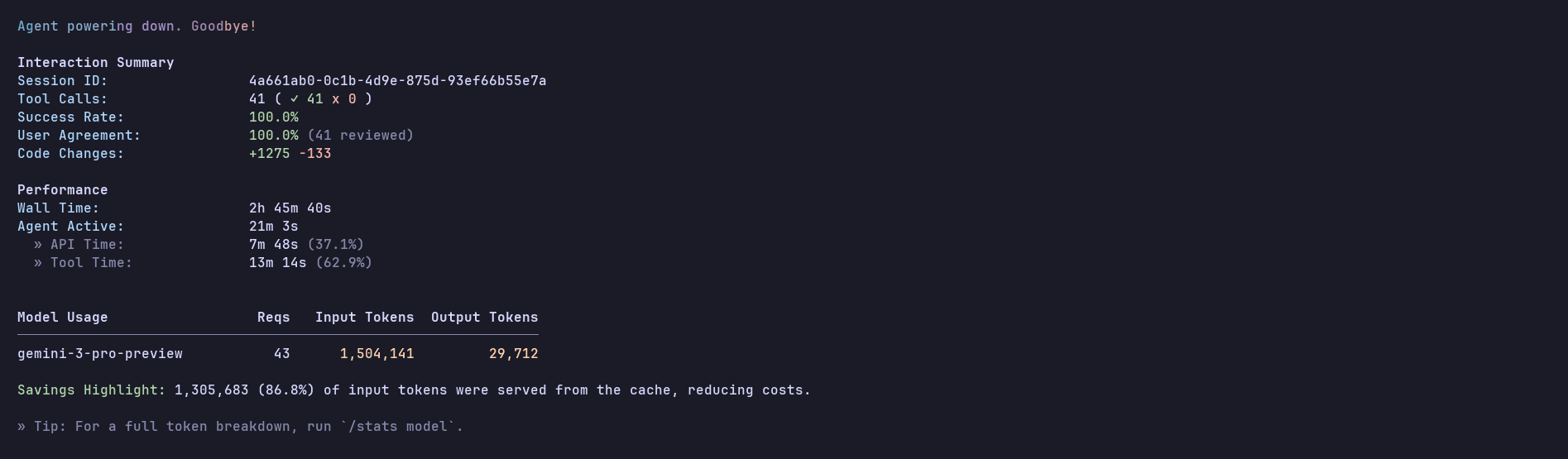
Response from Gemini 3 Pro:
You can find the code it generated here: Source Code
Here's the output of the program:
This works. It's not the best implementation with the best-written code style, but it simply works. Minimal yet functional. It's fascinating how well this model understands the context from the provided link and finds all the pieces it needs to put together.
There are still many type issues and a few code implementation issues, but all in all, it's hanging by a small thread, yet surprisingly, it just works.
In terms of time, it took about 5 minutes to build this entire agent. And, just to be clear, it's not a one-shot; I had to help it with a little bit of setup.
The entire test took around 14K output tokens, and since the prompt I gave is very verbose, the input token count is significantly higher.

Response from GPT-5.1:
Here's the output of the program it got me first:
For real, it just mocked the entire agent route. There's no composio tool router used. This is so depressing. All it did was create the UI and mock the whole agent implementation. 😑 BOMBOCLAT!
You can find the agent route code that was generated here: Link
Now, I had to copy and paste some parts of the tool router documentation manually, and with a lot of hand-holding this time and showing the Gemini 3 code as a reference, I got it somewhat working. But still, the UI is messed up, and the cards don't show.
Here's the final output of the program:
You can find the code it generated here: Source Code
Conclusion
Gemini 3 Pro kinda lived up to the hype in these tests. As for the code quality, both completed the test in one go, and the code is modular and follows best practices. However, sometimes GPT-5.1 provided much better code than Gemini 3 Pro. 🤷♂️
This model Gemini 3 is a lot better in agent-styled workflows, and even the UI, and it shows. Really looking to see how the Deep Think mode improves things once it rolls out.
If you're still curious to learn more, there's one blog that I recommend that you go through, "Three Years from GPT-3 to Gemini 3" by Ethan Mollick, that walks you through the whole AI arc in these years and gives you some intuition on what's changed, beyond just the benchmark numbers.
It's still early, and results may vary with different prompts, but for practical coding tasks, Gemini 3 Pro is a top model.