When Replit's AI coding tool recently wiped a user's database in what the company called a "catastrophic failure," it confirmed every CISO's worst fear.
That kind of catastrophic failure, a 'known unknown', is a failure of Granular Control (Pillar 2) and rightly dominates security conversations. It's a terrifying and visible risk that CISOs are actively building guardrails to prevent.
But there is a second, more insidious risk, an 'unknown unknown', that is far more common. This risk isn't a permissions issue. It's a failure of Reliable Action (Pillar 3).
What is Reliable Action
Reliable Action means standard infrastructure reliability. We use this term to separate two distinct concerns: securing the agent's identity (Authentication) versus ensuring the agent completes its task successfully (Reliability).
This isn't some new security concept. It's applying proven engineering standards to make sure agents don't fail silently.
This isn't the agent that actually deletes your database. It's the agent that fails silently halfway through a critical financial workflow. Picture this: The Salesforce contact gets created, but the corresponding Stripe subscription fails. This kind of integration gap is a primary cause of AI agent failures in sales automation. No database is deleted, but you now have thousands of corrupt customer records.
This second scenario, death by a thousand silent failures, is the most common and costly failure mode for AI agents in production. In our guide to production-ready AI agents, we introduced the three pillars of a secure infrastructure: Secure Authentication, Granular Control (which prevents the Replit scenario), and Reliable Action.
Most security models focus heavily on the first two pillars. This article is a deep dive into the third pillar, Reliable Action, and explains why it's the most overlooked and costly security risk for any CISO.
While 'front door' security measures like Brokered Credentials and Policy-as-Code (which we cover as Pillar 2 in our production-ready AI agent guide) are essential for preventing credential leakage, they don't address action failures. A secure system has to be reliable. An unreliable action can lead to data integrity breaches, denial-of-service conditions, and an ever-expanding attack surface.
Key Takeaways
Reliability Is a Security Risk: The most common AI agent failures aren't just bugs; they are security incidents. Silent data corruption from a failed workflow is a data integrity breach, and naive retry logic can cause self-inflicted DoS attacks.
Secure "Intent" vs. Secure "Action": Standard security (auth, governance) secures an agent's intent to act—often expressed via a tool call. This is not enough. You must also ensure the action itself with a reliability layer to prevent data corruption and cascading failures.
The Saga Pattern Prevents Data Corruption: For multi-step workflows (e.g., create contact, then create folder), you must use the Saga Orchestration Pattern. This ensures that if one step fails, all previous steps are automatically rolled back, leaving the system in a consistent, uncorrupted state.
Resilience Patterns Prevent DoS: Agents must use exponential backoff, rate limit parsing, and circuit breakers. Without them, a single agent in a retry loop can hammer a downstream API, leading to your organization's IP address being blocked.
Why Authentication and Authorization Alone Are Not Enough for AI Agent Security
The standard approach of authentication, authorization, and observability gives you a necessary start, but it won't cut it for autonomous systems. It only secures the intent to act and records what happened. It does nothing to ensure the action actually succeeds or recovers gracefully when it fails.
Consider our opening scenario again. The agent had proper authentication (it could access both Salesforce and Stripe). It had adequate authorization (it was allowed to create records). The observability layer logged everything that happened. Yet the system still ended up in a corrupt state with thousands of broken customer records.
This gap creates significant liability for production systems interacting with critical business data. Observability fundamentally works as a post-mortem tool. It excels at telling you that your data has been corrupted or that a workflow failed. It doesn't prevent the failure or fix the damage.
For autonomous agents, reliability is a core security feature. Action integrity is security.
The Missing Pillar: Securing the Action Itself
This missing pillar gets ignored by most AI agent security models, yet it addresses the most common source of production failures. Let's examine the three critical risks that emerge when action reliability isn't treated as a first-class security concern.
Risk 1: Data Integrity Failure (The Half-Done Workflow)
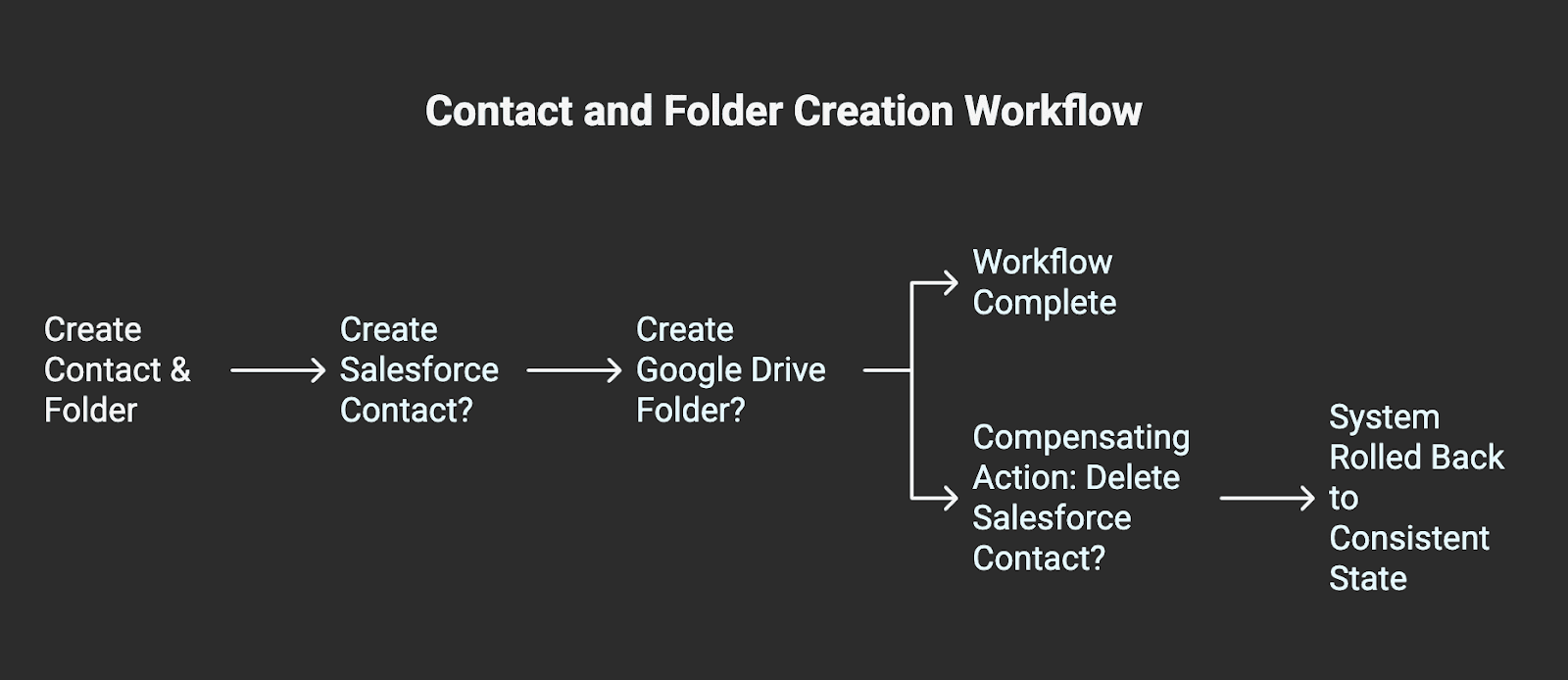
Scenario: An agent gets tasked with a two-step workflow. First, create a new contact in Salesforce. Second, create a dedicated Google Drive folder for that contact. The Salesforce API call succeeds, but the Google Drive API call fails due to a transient 503 Service Unavailable error.
The Security Impact: You now have an orphaned record in Salesforce with no corresponding folder. This is a data integrity breach. The system sits in a corrupt, inconsistent state. At scale, thousands of these small failures create a massive data cleanup problem and undermine business operations.
The Technical Solution: The Saga Orchestration Pattern manages distributed transactions in this way. A Saga consists of a sequence of local transactions. Each transaction has a corresponding "compensating action" that can undo it. In our scenario, if the Google Drive API call fails, the Saga orchestrator executes the compensating action for the first step, deleting the newly created Salesforce contact. This rolls the system back to a consistent state, ensuring data integrity stays intact.
Risk 2: Self-Inflicted Denial of Service (The "Noisy Neighbor" Agent)
Scenario: An agent attempts to create a ticket in Jira but receives an 429 Too Many Requests error. The agent's code, written without robust error handling, immediately retries the request in a tight loop.
The Security Impact: The agent hammers the Jira API, ignoring the Retry-After header. In response, Jira's security systems block your company's IP address or API key. The agent has just launched a self-inflicted Denial-of-Service (DoS) attack, bringing down a critical business tool used by every team in the organization.
The Technical Solution: A managed action layer must have built-in resilience patterns. This includes exponential backoff with jitter, which intelligently increases the delay between retries to give the downstream service time to recover. It must also parse rate-limit headers Retry-After to respect the API's policies. Finally, a circuit breaker can detect when a service consistently fails and temporarily stop sending requests, preventing cascading failures.
Risk 3: The "N+1" Attack Surface
Scenario: Your team needs to build agents that integrate with 50 different tools. This means your developers now manage 50 different authentication schemes, 50 different error code taxonomies, 50 different data schemas, and 50 different retry policies.
The Security Impact: Every new integration becomes a new, custom-coded security risk. The attack surface of your agentic system grows exponentially with each tool you add. The cognitive load on your developers to maintain this complexity leads to mistakes and vulnerabilities.
The Technical Solution: A unified API for AI agents abstracts away this complexity. Instead of learning 50 different ways to create a task, the agent interacts with a single, consistent interface, like tasks.create. The underlying platform handles translation to each tool's specific API. This shrinks the attack surface from 50+ to 1. It provides a single, secure, and reliable policy for all actions, making the system easier to govern and scale.
Integrating Reliable Action with Your Agent Stack
Developers aren't building agents from scratch. They're using powerful AI agent builders and integration frameworks like LangChain, CrewAI, and LlamaIndex. The reliable action approach integrates directly into this ecosystem at the tool definition layer.
The key architectural shift ensures your agent's tools don't make direct network calls (via requests.post, for instance). Instead, they make calls to a secure broker that implements these reliability patterns. This simple change delegates all the complexity of retry logic, rate limiting, and transaction management to a managed platform.
Here's a practical, production-ready example of how to build a LangChain agent with built-in action reliability:
# 1. Installation
# Make sure to install the necessary packages for this example.
# !pip install composio-langchain langchain-openai python-dotenv
# 2. Setup
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.agents import create_agent
from composio import Composio
from composio_langchain import LangchainProvider
# Load environment variables from a .env file in the same directory
load_dotenv()
# Ensure API keys are set in your environment for security
# Do not hardcode secrets in your application
assert os.getenv("OPENAI_API_KEY"), "OPENAI_API_KEY is not set in environment variables"
assert os.getenv("COMPOSIO_API_KEY"), "COMPOSIO_API_KEY is not set. Get one from https://app.composio.dev"
# In a real application, this would be the unique ID of your authenticated user.
# It tells Composio which user's connections to use.
USER_ID = "<USER_ID>" # Replace with a dynamic user ID
# 3. Initialize LLM and Tools
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# Composio provides a toolset for hundreds of apps.
# Here, we'll get the tools for Jira.
# The toolset handles all the complexity of auth, retries, and error handling.
composio_client = Composio(provider=LangchainProvider())
try:
tools = composio_client.tools.get(user_id=USER_ID, toolkits=["jira"])
except Exception as e:
print(f"Error fetching tools: {e}")
tools = []
# 4. Create the Agent
# Using the new LangChain 1.0 pattern with create_agent
if tools:
agent = create_agent(
model=llm,
tools=tools,
system_prompt="You are a helpful assistant that can create Jira tickets."
)
else:
print("No tools were fetched. Agent cannot be created.")
agent = None
# 5. Run the Agent
# The agent will use the Composio-managed Jira tool.
# The call is brokered through Composio, so the LLM never sees any credentials.
# Composio's managed action layer handles rate limits, retries, and provides structured logs.
if agent:
try:
result = agent.invoke({
"messages": [{"role": "user", "content": "Create a ticket in the 'PROJ' project to fix the login bug. The description should be 'Users are reporting 500 errors on the login page after the last deployment.'"}]
})
print("\nAgent Response:")
print(result["messages"][-1]["content"])
except Exception as e:
# Although Composio tools have built-in retries, a final failure
# might still occur (e.g., invalid project key, permissions issue).
# The error message from the tool will be specific and informative.
print(f"An error occurred: {e}")
else:
print("Agent was not created. Cannot execute task.")By defining tools this way, the agent's logic stays focused on planning and reasoning, while the broker provides a reliable foundation for every action it takes, including automatic retries, rate limit handling, and transaction rollback on failure.
How a Developer Can Debug Failed Actions
When an agent's action fails through a reliability-focused broker, developers need a clear path to diagnose the problem. Without it, the broker feels like a black box, hindering development and eroding trust. A core feature of any production-ready action layer is providing rich, correlated observability.
When a tool call fails, the developer's workflow should check the structured logs from the broker, not guess what happened. A high-quality error log must contain:
trace_id: A unique identifier to correlate this specific action with the entire agent workflow, from prompt to final responseTimestamp: When the error occurred
Agent/Principal Identity: Which agent or user initiated the action
Original Agent Request: The exact tool name and parameters the agent sent to the broker
Retry Attempts: How many times the action was retried and with what backoff
Circuit Breaker Status: Whether the circuit breaker was triggered
Upstream API Response: The complete HTTP status code, headers, and response body from the external API
With this level of detail, a developer can immediately distinguish between a transient network issue (that was automatically retried), a rate limit violation (that respected the Retry-After header), or a genuine bug in the agent's logic.
Comparing Best Approaches for AI Agent Action Reliability and Security
You can implement action reliability in several ways, each with significant trade-offs. The three most common approaches differ dramatically in their handling of the critical reliability features:
Capability | DIY (In-House) | Auth-to-Action (Composio) | |
Saga Pattern/Transaction Rollback | Manual Build | ❌ (Not addressed) | ✅ (Built-in) |
Managed Retries & Rate Limiting | Manual Build | ❌ (Requires custom layer) | ✅ (Automatic) |
Circuit Breaker Implementation | Manual Build | ❌ (Not addressed) | ✅ (Per-service breakers) |
Unified API for 50+ Tools | N/A | ❌ (Per-API integration) | ✅ (500+ tools) |
Correlated Audit Logs for Actions | Manual Build | Partial (Auth events only) | ✅ (Full action lifecycle) |
Compensating Actions for Failed Workflows | Manual Build | ❌ (Not addressed) | ✅ (Configurable) |
Automatic Backoff with Jitter | Manual Build | ❌ (Not addressed) | ✅ (RFC-compliant) |
Per-Tool Error Normalization | Manual Build | ❌ (Raw errors exposed) | ✅ (Standardized errors) |
Time to Implement Action Reliability | 4-6 months | 2-3 months (custom build) | Immediate |
Ongoing Maintenance Burden | Very High | High | Minimal |
Analysis
DIY (Do-It-Yourself): Building reliable action execution from scratch requires implementing distributed transaction patterns, retry logic with exponential backoff, circuit breakers, and error normalization for dozens of APIs. This represents months of specialized engineering work that most teams underestimate.
Auth-Only Components: Tools like Nango and Arcade excel at solving authentication challenges but don't address action reliability at all. You still need to build the entire reliability layer yourself, including retry logic, transaction management, and circuit breakers for each integration.
Auth-to-Action Platforms: Composio and similar platforms treat action reliability as a first-class concern. They provide built-in Saga orchestration, intelligent retry mechanisms, circuit breakers, and unified error handling across hundreds of tools. This dramatically reduces both implementation time and ongoing maintenance burden.
Conclusion
As AI agents move from prototypes to production, treating action reliability as separate from security is a critical mistake. Data integrity breaches from half-completed workflows aren't operational issues. They're security incidents. Self-inflicted DoS attacks from poorly implemented retry logic aren't bugs. They're vulnerabilities.
The most secure authentication and authorization in the world won't prevent an agent from corrupting your data through unreliable actions. While the industry focuses on securing the "front door" with better authentication and governance (covered in our comprehensive security guide), the back door of action failure remains wide open.
For production AI agents, reliable action is the missing security pillar. Don't just secure the agent. Secure the action.
To learn more about building production-ready AI agents with all three security pillars, explore the Composio documentation or get started for free.
Frequently Asked Questions
Why is action reliability a security concern rather than just an operational one?
Unreliable actions directly lead to security incidents. A failed multi-step workflow can corrupt data integrity. A poorly implemented retry mechanism can trigger a self-inflicted DoS attack. An expanding set of custom integrations exponentially increases your attack surface. These aren't bugs; they're vulnerabilities that compromise system security.
What is the best way to manage complex, multi-step workflows for AI agents?
The Saga Orchestration Pattern is the best way to build complex, multi-step workflows for AI agents. It manages distributed transactions across multiple services. Each step in a workflow has a corresponding "compensating action" that can undo it. If step 3 of a 5-step workflow fails, the Saga orchestrator automatically executes compensating actions for steps 2 and 1, rolling the system back to a consistent state. Without this, agents leave behind orphaned records and corrupted data.
How do circuit breakers prevent AI agents from causing DoS attacks?
Circuit breakers monitor the failure rate of external service calls. When failures exceed a threshold, the circuit "opens," halting request transmission for a cooling-off period. This prevents an agent from hammering a struggling service with retries, which could lead to IP bans or API key revocation. Without circuit breakers, a single agent can take down critical business tools for your entire organization.
Can't I add retry logic to my existing agents?
Simple retry logic without exponential backoff, jitter, and rate limit awareness often makes problems worse. Immediate retries can overwhelm struggling services. Fixed delays don't account for variable recovery times. Ignoring Retry-After headers violates the API terms of service. Production-grade retry logic requires sophisticated implementation that most teams underestimate.
How can you safely build agents on APIs that weren't designed for autonomous use?
You can't do it safely without an abstraction layer. Brittle APIs lack the required resilience for autonomous use. You must wrap them in a managed action layer that provides its own resilience. This layer adds automatic retries with exponential backoff, intelligent rate limit handling, and circuit breakers. This proxy protects the brittle API from the agent and prevents self-inflicted DoS attacks.
How do you reduce API errors and ensure transactional integrity for AI agents?
These are two separate but critical challenges. You reduce API errors with resilience patterns. This means automatic retries with exponential backoff and circuit breakers to handle transient failures. You ensure transactional integrity with a distributed transaction model. The Saga Orchestration Pattern is the standard. It uses compensating actions to roll back multi-step workflows that fail automatically. This prevents data corruption.