MiniMax M3 and Kimi K2.7 occupy the same useful category: cheap open-weight models, meaning their weights are available outside a closed API.
Both claim strong multi-step tool use, where the model plans, calls tools, reads results, and keeps going, at a fraction of the highest-end closed-model pricing.
I want that category to work because coding agents get expensive fast once they start looping through terminals, logs, search, and tool calls.
I had one question: which one would I actually trust to drive an agent when the task stops being a neat prompt and turns into a messy repo or a chain of SaaS actions?
And honestly, you won’t get the answer from marketing pages. First, the pages show you benchmarks that nobody cares about, and even if they score 80%, it would be on easy examples they have already seen.
So, I took a different approach. I handpicked terminal bench questions that are provably hard even for SOTA models, along with a custom benchmark for real-world workflows. More on these later.
I tracked completion, cost, token use, and LLM as judge-verified results.
MiniMax M3 vs Kimi K2.7 at a glance
Dimension | MiniMax M3 | Kimi K2.7 |
|---|---|---|
Context window | 1,048,576 tokens (1M) | 262,144 tokens (262K) |
Input cost (per M tokens) | $0.30 | $0.68 |
Output cost (per M tokens) | $1.20 | $3.41 |
Terminal-Bench score (10 hard tasks) | 5/10 | 5/10 |
Terminal-Bench total cost | $2.80 | $5.85 |
Cost per solved task | $0.56 | $1.17 |
Composio tool-use avg (25 tasks, 0–1) | 0.75 | 0.78 |
Composio total cost | $0.81 | $2.02 |
Overall verdict | Costs less with lower tool use accuracy. | Better tool-use ability with a higher cost |
On 10 hard sandboxed Terminal-Bench coding tasks, scored pass/fail by automated tests, M3 solved 5/10, and Kimi K2.7 solved 5/10. Kimi spent about 2.4 times as much doing it.
They solved the same four coding tasks. The extra M3 solve was
path-tracing-reverse, a path-tracer reverse-engineering task, where M3 finished after 134 model-to-terminal round trips, and Kimi timed out even with the doubled time budget.On the 25-task Composio tool-use suite across Gmail, Slack, Drive, GitHub, Calendar, Reddit, Notion, and web search, scored from 0 to 1, M3 averaged 0.75, and Kimi averaged 0.72. The scores were close.
The cost gap widened on tool use: M3 cost $0.81 across the 25 Composio tasks, while Kimi cost $4.08, about 5x more.
In my runs, M3 had the clearer edge on hard terminal coding. Every day, SaaS tool orchestration was effective.
For my use, M3 comes out ahead in both sets, with different margins. It wins clearly on agentic terminal coding and costs about a third per solved task. Real tool use was close enough to be treated as a near tie.
Intro to MiniMax M3
MiniMax M3 is MiniMax’s open-weight model aimed pretty directly at coding-agent work. It pairs a 1,048,576-token context window with low pricing and native tool calling. Here, tool-calling refers to structured requests to run shell commands, inspect files, edit code, or call external services.
The main spec is the context window: 1,048,576 (1M) tokens. That gives an agent room to keep much more repo state, logs, and previous attempts in view before it has to start trimming context.
On price, M3 is cheap: $0.30 per million input tokens and $1.20 per million output tokens on OpenRouter. I watch the output side closely with coding agents, since patches, retries, tool calls, and long explanations can quietly run up the bill. M3 keeps that meter low.
Intro to Kimi K2.7
Kimi K2.7 is Moonshot AI’s open-weight model in this matchup. It has a 262,144-token context window and native tool-calling, and Moonshot positions it as a step up from K2.7. That made it worth testing for agent work. Tool-calling matters when the model has to request external actions, wait for results, and continue from there.
In normal terms, 262K is big, though it is smaller than MiniMax M3’s 1,048,576 tokens. I still take 262K seriously, since an agent can carry a lot of repo state, as well as logs and tool outputs. It just has less room to be sloppy about history than M3.
Price: $0.68 per million input tokens and $3.41 per million output tokens on OpenRouter. M3 is $0.30 in and $1.20 out, so K2.7 output is about 2.8x more expensive. In agent loops, output tokens pile up fast because the model keeps explaining each move, calling tools, reading results, and trying again.
How I tested this
I ran two head-to-head tests. In each one, I kept the harness fixed and changed only the model ID, minimax/minimax-m3 versus moonshotai/kimi-k2.7.
Agentic terminal coding: Terminal-Bench, run through
terminuson Daytona cloud Linux sandboxes via OpenRouter.Real tool use: a 25-task Composio suite, using Composio tool-router meta tools via OpenRouter.
GPT-5.5 High as the judge
OpenRouter was the routing and billing layer for both runs.
Terminal-Bench is a benchmark of hard command-line tasks. For example, tasks may require writing a compressor or reversing a path tracer. Each task runs inside its own isolated Linux sandbox, and the final answer is judged by an automated test for that task. In this section, “solved” means the task’s automated test passed.
The sample was the 10 hardest Terminal-Bench 2.0 tasks, so the score reflects that hard slice. It should not be read as a full-suite leaderboard score across every task.
Sandbox access goes through an agent called terminus. The model reads the terminal state, chooses the next command, sees the output, and then decides what to do next. I count each of those model-to-terminal round-trip as a step. So when a task takes 100+ steps, that means the model stayed coherent across a long chain of shell commands, edits, test runs, and fixes.
Each Terminal-Bench task has a built-in time limit. I doubled that limit for both models with agent-timeout-multiplier 2, because an initial run at the standard limit was cutting them off while they were still making progress. At the default limit, cutoffs often happened before the agent had finished exploring a plausible path, so I used the doubled limit for the head-to-head run.
The second test was a 25-task Composio suite against real connected accounts across Gmail, Google Calendar, GitHub, Slack, Google Drive, Reddit, Notion, and web search. Composio connects agents to authenticated app actions; the tool-router meta tools let the model find and run an app action when needed.
The Composio tasks were graded from 0 to 1. A score of 1 means the model actually did the job inside the connected account. A score of 0 means it failed the task. Partial scores mean it got some of the required work right but missed or mangled part of it, or failed to verify the result. An independent GPT-5.5 judge model graded the finished task and checked public claims against the live web.
Related: Opus 4.8 vs GPT 5.5
Test 1: Agentic terminal coding
The run used the 10-task hard slice from Terminal-Bench 2.0, through the same terminus agent on Daytona via OpenRouter. Each task is passed/failed by an automated test, and both models got a doubled time budget.
Task | M3 | M3 cost | Kimi K2.7 | Kimi cost |
|---|---|---|---|---|
feal-differential-cryptanalysis | ✅ | $0.09 | ✅ | $0.18 |
fix-code-vulnerability | ✅ | $0.04 | ❌ | $0.02 |
llm-inference-batching-scheduler | ✅ | $0.19 | ✅ | $0.35 |
make-mips-interpreter | ❌ | $0.83 | ❌ | $0.86 |
password-recovery | ✅ | $0.09 | ✅ | $0.14 |
path-tracing-reverse | ✅ | $1.17 | ❌ | $1.75 |
regex-chess | ❌ | $0.00 | ✅ | $2.32 |
torch-pipeline-parallelism | ❌ | $0.11 | ❌ | $0.06 |
torch-tensor-parallelism | ❌ | $0.07 | ✅ | $0.13 |
write-compressor | ❌ | $0.21 | ❌ | $0.04 |
Total | 5/10 | $2.80 | 5/10 | $5.86 |
M3 and Kimi tied this run 5/10 to 5/10. Their three shared solves were a FEAL cypher-attack task, an LLM inference-batching scheduler, and password recovery.
The split came from the edge cases. M3 solved the fix-code-vulnerability and path-tracing-reverse tasks. Both models had double the normal time budget. M3 kept the agent working for 134 steps, meaning 134 model-to-terminal round trips, and eventually landed the path-tracing solve. Kimi spent $1.75 on the same task and still timed out.
Kimi made up the gap by solving regex-chess and torch-tensor-parallelism, both of which M3 missed. That makes the pass count even, but the cost line still favours M3.
M3 finished the whole run at $2.80. Kimi spent $5.86 for the same number of solved tasks, about 2.1x the total spend.
The result stays narrow. The MIPS interpreter build (make-mips-interpreter), the PyTorch pipeline-parallelism task (torch-pipeline-parallelism), and write-compressor beat both models even with the doubled budget. My read is narrow: M3 was cheaper and stronger on the long path-tracing task, while Kimi recovered with wins on regex-chess and tensor parallelism.
Test 2: Real-world tool use
This run covered 25 real jobs against connected accounts:
summarising a month of emails by sender,
counting a week of Slack by channel,
organising 1,000 Drive files,
looking up a GitHub repo’s stats,
scraping startups and drafting outreach emails. Each task got a 0-to-1 score from an independent grader.
…etc
Task | M3 | Kimi K2.7 | M3 cost | Kimi cost |
|---|---|---|---|---|
Summarize a month of inbox by sender | 0.95 | 0.90 | $0.011 | $0.066 |
List 10 recent Notion pages | 0.95 | 0.72 | $0.007 | $0.016 |
GitHub repo stats lookup | 0.95 | 1.00 | $0.004 | $0.008 |
Organize 1,000 Drive files by type and date | 0.95 | 0.96 | $0.046 | $0.052 |
Categorize 3 years of calendar events | 0.92 | 0.82 | $0.020 | $0.080 |
Count + summarize a week of Slack by channel | 0.92 | 0.95 | $0.019 | $0.055 |
Summarize last 10 unread emails by sender | 0.9 | 0.98 | $0.009 | $0.016 |
Organize 10 recent Drive files | 0.9 | 0.75 | $0.010 | $0.013 |
Top 10 Reddit posts on LLMs | 0.86 | 0.86 | $0.022 | $0.050 |
Summarize the last 20 Slack messages | 0.86 | 0.75 | $0.020 | $0.024 |
Scrape YC $20M+ startups, draft outreach emails | 0.78 | 0.62 | $0.151 | $0.519 |
Daily tech digest from email + web news | 0.78 | 0.86 | $0.034 | $0.058 |
AI lab intel report (OpenAI/DeepMind/Anthropic) | 0.78 | 0.82 | $0.089 | $0.136 |
Next 5 calendar events as a reminder | 0.78 | 0.86 | $0.013 | $0.038 |
Curated dev digest from web + Reddit | 0.76 | 0.78 | $0.043 | $0.189 |
Productivity report from Calendar + GitHub + Slack | 0.75 | 0.92 | $0.076 | $0.226 |
Trending GitHub repos in Rust/Go/Python | 0.74 | 0.65 | $0.016 | $0.020 |
List 3 months of commits on a repo | 0.72 | — | $0.085 | — |
Frontend trend report from Reddit + web | 0.72 | 0.68 | $0.047 | $0.106 |
Top 5 Reddit posts on Python dev | 0.68 | 0.62 | $0.039 | $0.018 |
San Francisco weather summary | 0.6 | 0.95 | $0.002 | $0.012 |
Latest commit on a GitHub repo | 0.45 | 0.45 | $0.008 | $0.018 |
Compare Rust/Go/Zig via GitHub trending | 0.42 | 0.62 | $0.018 | $0.159 |
Top 10 web results on Docker best practices | 0.35 | 0.45 | $0.010 | $0.006 |
Technical research doc on microservices | 0.25 | 0.82 | $0.008 | $0.138 |
Average / total | 0.75 | 0.783 | $0.81 | $2.02 |
Kimi won this tool-use run on quality, averaging 0.783 against M3’s 0.75.
Kimi’s biggest wins came on research-heavy and mixed-tool tasks, including microservices research, weather summary, productivity reporting, and Rust/Go/Zig comparison.
M3 still won several practical SaaS tasks, including inbox summaries, Notion page listing, Drive organisation, Slack summaries, YC outreach, and GitHub trend lookup.
The cost gap still favours M3. M3 spent $0.81, while Kimi spent $2.02, about 2.5x more.
My read: Kimi K2.7 is slightly better on quality, especially for research and synthesis, while M3 remains the better value pick.
Cost Analysis
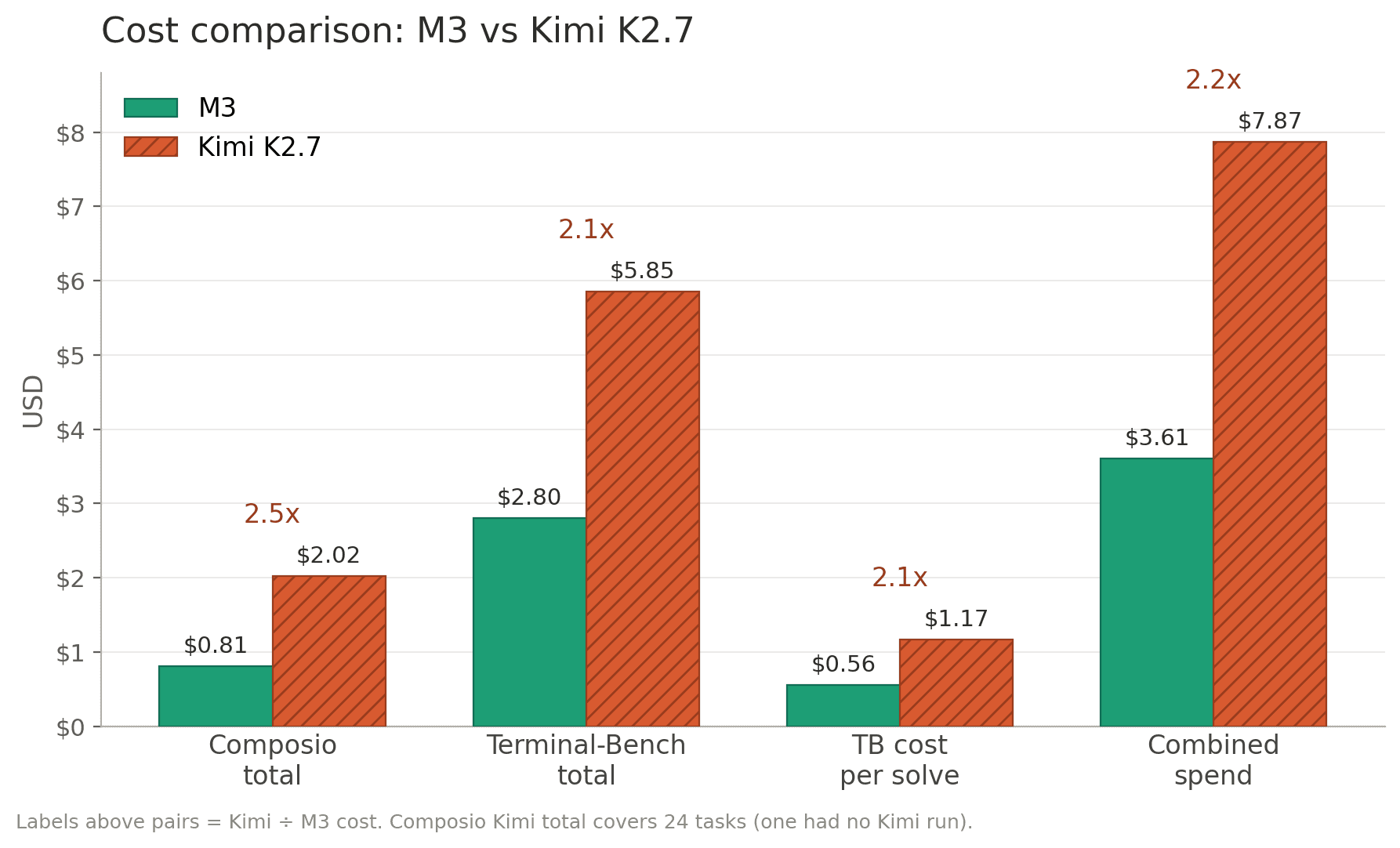
I used the actual per-run price billed through OpenRouter and summed it per task.
Terminal-Bench costs $2.80 for M3 and $6.61 for Kimi, about 2.4x more. M3 also solved one more task. The per-solved-task math is worse for Kimi: $0.56 per solve for M3 against $1.65 for Kimi.
The tool run had a bigger spread. Across the 25 Composio tasks, M3 spent $0.81, and Kimi spent $4.08, roughly 5x. The quality scores were close, 0.75 for M3 vs 0.72 for Kimi, while Kimi cost about five times as much to get there.
OpenRouter rates explain part of that. M3 was listed at $0.30 per million input tokens and $1.20 per million output tokens. Kimi was $0.68 input and $3.41 output, so input was a little over 2x, and output was about 2.8x. Kimi also tends to emit more tokens per task, so the gap compounds inside agent loops.
Caveat: these were small task counts, and OpenRouter’s billed prices can differ slightly from a vendor’s own API. The direction remained consistent for this workload: M3 was significantly cheaper.
Final Verdict
My pick is M3 for both workloads, but the margins are different. The terminal-coding run is a clearer win, and M3 costs about a third per solve. The real tool-use run is a near tie.
Terminal-Bench was the cleaner M3 win: 5/10 for M3 vs 4/10 for Kimi. M3 costs $2.80 total and $0.56 per solve, while Kimi costs $6.61 total and $1.65 per solve. The task I kept coming back to was path-tracing-reverse: M3 solved it in 134 agent steps, meaning model-to-terminal round trips, while Kimi timed out even with the doubled budget.
Composio was much closer. M3 averaged 0.75 across 25 real tool tasks; Kimi averaged 0.72. Both handled the same kind of Gmail, Calendar, GitHub, Slack, Drive, Reddit, Notion, and web search orchestration well enough that I would treat them as close on that workload. M3 did it for $0.81 instead of $4.08.
When you’ll notice the difference
Hard, long-horizon terminal work is where M3’s lead and cost edge matter. For SaaS orchestration, the models are close enough that M3’s lower bill is the practical separator.
Caveats: this was only 10 Terminal-Bench tasks plus 25 Composio tasks. The Terminal-Bench run used a doubled time budget, so treat it separately from standard leaderboard comparisons. Both models are still far below the best closed models on the hardest coding tasks, so I’d try them on your own workflow before swapping anything in.
If you want to build agents like this against real apps, Composio connects them to 1,000+ apps with auth handled.