Anthropic dropped Opus 4.8 this week, just before they file for the IPO. Well, for whatever reason, we now have a new state-of-the-art model. And it’s hardly been a week, and the internet is split, if it is any better than its predecessor.
Some people say it is a big upgrade. Some say it is barely different. And some people on X and Reddit are saying it is the worst Opus release so far.

After Opus 4.7 nerf and GPT 5.5 release, I moved to Codex. I have been using it for almost everything from coding to marketing tasks. And I usually test these models for my own vibe and sanity check.
So I wanted to see it for myself. If it’s any good. Should I switch and renew Claude Max?
First, I ran a small set of harder Terminal-Bench 2.1 tasks against GPT-5.5 with high reasoning ( the current best in agentic terminal coding).
Then I tested both models in a more realistic workflow: building an agentic dashboard that parses the same Terminal-Bench results and Harbour benchmark runs and turns them into Slack, Notion, and Linear actions.
This is going to be an interesting one. So, let's start.
TL;DR
If you want the quick take, here’s what happened:
GPT-5.5 was better on the Terminal-Bench run. It was faster, cheaper, and finished most of the selected hard tasks without any problems.
Opus 4.8 still solved the task GPT-5.5 failed.
For the Composio agentic dashboard build, Opus 4.8 made a better frontend.
Opus cost me more than twice as much as GPT-5.5, even though GPT-5.5 has the more expensive output tokens. One task alone cost me over $28. Opus 4.8 is super token-heavy (a smart way to pump the revenue numbers, ngl).
GPT-5.5 was much faster on the build, but the output was worse. It got things partially working, but honestly, I did not have much hope there anyway.
So yeah, Opus 4.8 is not bad. I don’t agree with the trash takes.
And I’m not saying this just from this run. I’ve been using this model constantly for the last 2 to 3 days.
For anything other than Terminal-Bench 2.1, token efficiency, and speed, GPT-5.5 does not compare to Opus 4.8 at all.
💡 My take: Opus 4.8 is good, but it feels pretty close to Opus 4.7. Not a huge model jump. Try it on your exact workflow before judging it based on internet takes.
Intro to Claude Opus 4.8
Claude Opus 4.8 was released on May 28, 2026, as Anthropic's flagship model, and it's a bit different. It's not sold as a new model with bigger benchmarks.
Antropic itself is not trying to sell it as a massive generational jump in the model's performance. It's a tiny bit of an improvement over Opus 4.7, which is fair; even in the benchmark numbers, it's only slightly better.
There are also a bunch of new features added to this model, which you can find them all here.
But the interesting part is that the improvements are exactly in the areas where coding agents usually panic: tool use, self-correction, long-context handling, and honesty when something is wrong.
The biggest claim Anthropic is making with Opus 4.8 is not just that it writes better code. It is that it is much better at noticing when the code it wrote has a bug. It's said to be 4x less likely than Opus 4.7 to let buggy code pass.
If true, that's probably the biggest win.
But there are trolls going on everywhere on Twitter (X) saying how bad Opus 4.8 is compared to Opus 4.7 or any recently launched models.
Well, that's a story for the next day...
The real pain is when it confidently keeps building on top of a bad assumption, and wastes the next 30 minutes debugging something it created itself.
Specs-wise, there's not much of a big jump, as I said. It comes with a 1M token context window, 128K max output, multi-model and has the knowledge cutoff of January 2026.
Pricing is the same as Opus 4.7:
Input Cost: $5/M input tokens
Output Cost: $25/M output tokens
💁 There is also prompt caching with up to 90% savings, batch processing at 50% savings, and a cheaper Fast Mode that runs at roughly 2.5x output speed for $10 input / $50 output per million tokens.
So on paper, you're basically getting better performance for the same price over Opus 4.7.
Now, coming to benchmarks.
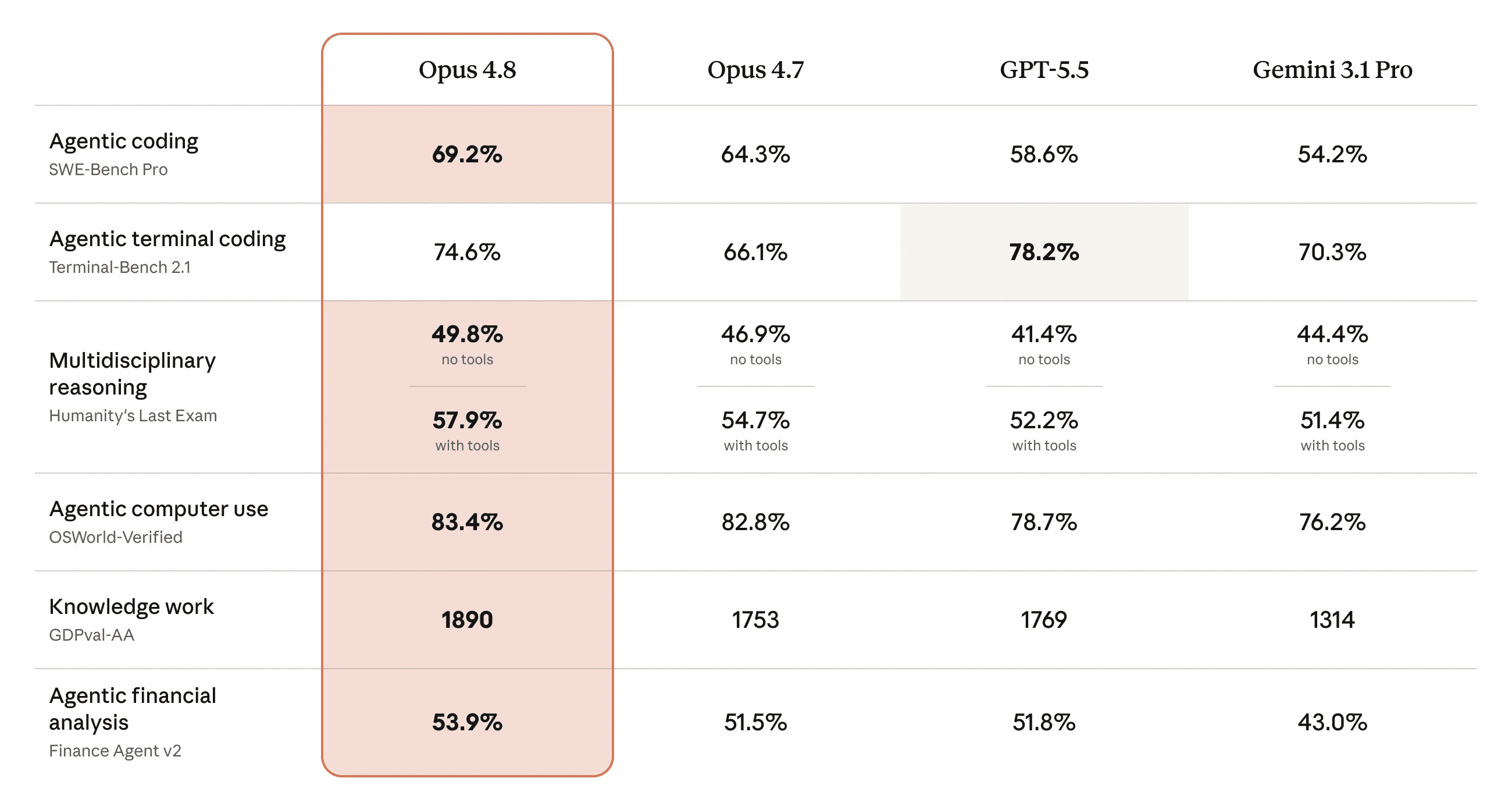
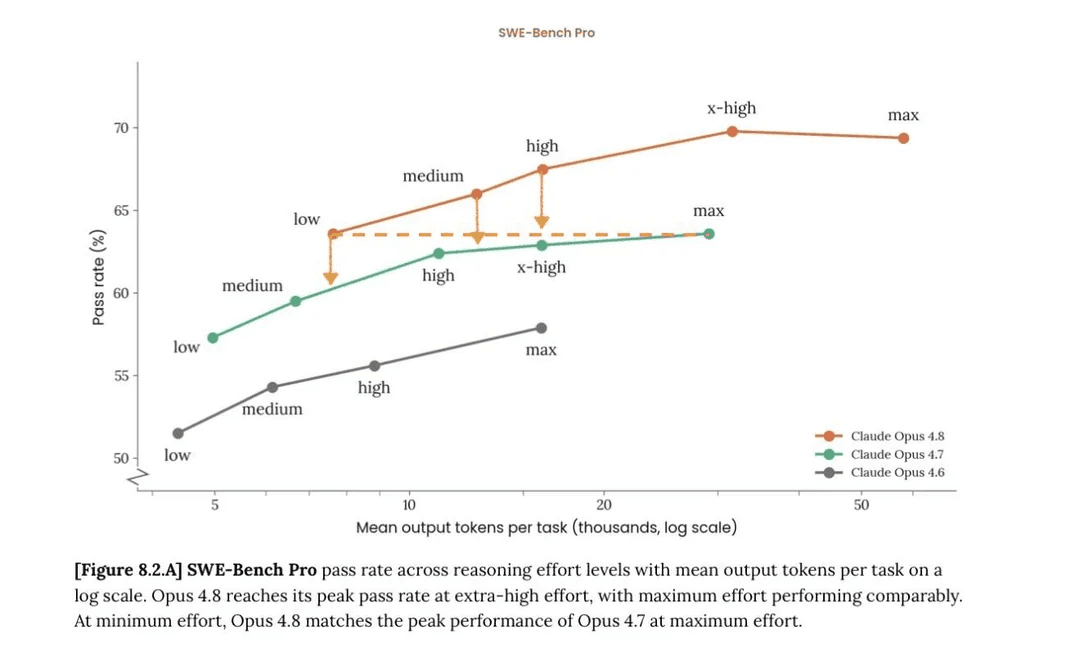
On SWE-bench Verified, it scores 88.6%, which is only slightly above Opus 4.7, but that benchmark is already getting saturated. The more interesting number is SWE-bench Pro, where Opus 4.8 scores 69.2%, compared to 64.3% for Opus 4.7 and 58.6% for GPT-5.5. That is a pretty big lead on a harder benchmark.
But it does not win everything. The model's biggest weak spot is terminal coding. On Terminal-Bench 2.1, Opus 4.8 scores 74.6%, which is a nice jump from Opus 4.7’s 66.1%, but GPT-5.5 still leads at 78.2% (not to forget this model is launched a month back) and reportedly does even better on its native Codex CLI harness.
💁 I will try to compare them on a few Terminal-Bench 2.1 tests.
There's a lot more you could compare, but I'll leave it up to you to research on your own.
Evaluating Opus 4.8 vs. GPT 5.5 High
For the test, I did two things: ran a small Terminal-Bench 2.1 set (hard problems), and then tried to build an agentic workflow based on the test results.
I mostly wanted to see how both models behave when the task gets a bit closer to actual work.
Setup
For the test, we will use the following CLI coding agents:
Claude Opus 4.8: Claude Code (Anthropic’s terminal-based agentic coding tool)
GPT 5.5: OpenAI Codex
What I measured
For this comparison, I looked at:
Task success: whether the model completed the task or failed.
Runtime: how long each task took.
Cost: how much the run costs, where pricing was available.
Token usage: uncached input, cached input, and output tokens.
Errors: where the model failed, got stuck, or had to be stopped.
Agentic Terminal Coding (Terminal-Bench 2.1)
Okay, now that the setup is clear, let’s start.
Great, now that we know the model is not superior to GPT-5.5 in agentic terminal coding, how about we test it here first?
Many of us know what Terminal-Bench 2.1 tests are, but probably haven’t tried testing it ourselves. So, I wanted to run the same benchmark test again on these two models to compare their performance, runtime, cost, and whether GPT-5.5 is truly superior.
A top-tier test to compare the models in the actual coding workflow.
💁 NOTE: There are a total of 89 tests in the new Terminal-Bench 2.1, but we won’t bother testing all of them. Most of them are easy to medium difficulty. For this one, we’re doing it just to get an overview, so I’ll be testing them on my top 10 picks from the harder questions.
I’ll also upload the results so you can view and verify them yourselves.
How to view the Raw Runs
I’m also pushing the full runs for both models to GitHub so anyone can check the results directly.
You can view the entire run, including task logs, tool calls, token usage, duration, and cost for both runs.
💁 To view the runs properly with Harbor, install Harbor first. You can follow the installation guide here: Harbor Installation
After that, clone the repo:
git clone https://github.com/shricodev/harbor-runs-opus-4.8-gpt-5.5
cd harbor-runs-opus-4.8-gpt-5.5Then view the jobs with Harbor:
harbor view --jobs jobs/gpt-5.5
harbor view --jobs jobs/opus-4.8You can also inspect a specific job from there to go through the tool calls, logs, and task output.
GPT-5.5
The first thing I noticed was the speed, compared to Opus 4.8.
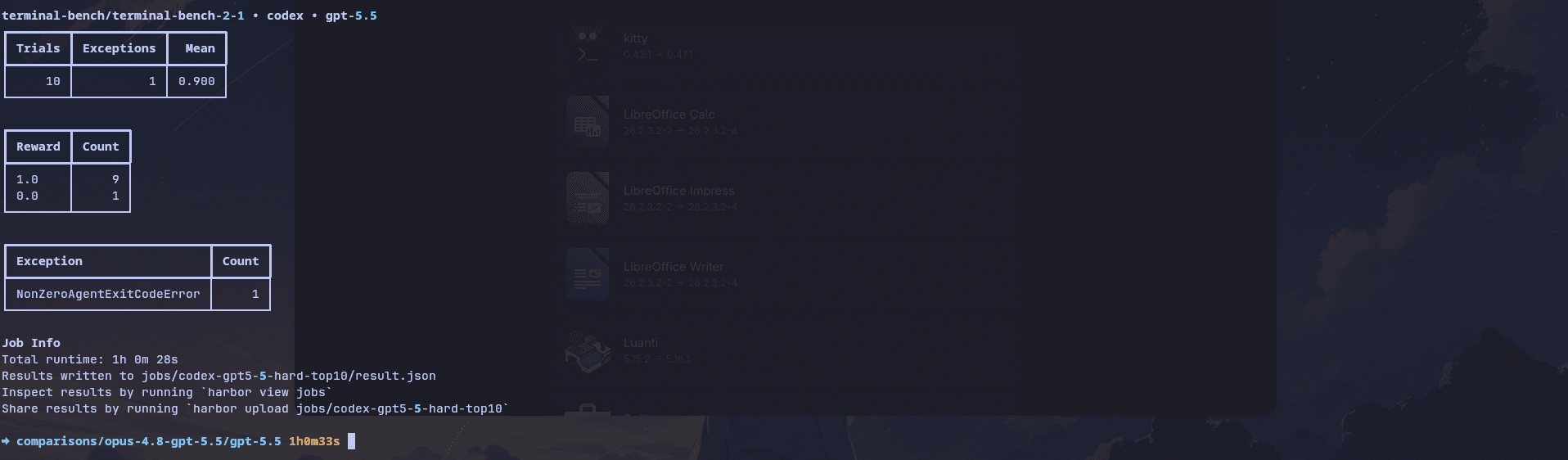
The entire run took around 1 hour 28 sec, which is half the total time by Opus 4.8.
It passed 9 out of 10 tasks and failed on password recovery with a NonZeroAgentExitCodeError.
The interesting thing is that Opus did pass the same task. So, this is not a clean win either way.
GPT 5.5 kinda looked great compared to Opus in speed and cost. It's surprising, GPT 5.5 did better in cost as well, comparing its around $5/M token expense to Opus 4.8.
The longest GPT-5.5 task was:
torch-pipeline-parallelism: 12m 29s
The most expensive GPT-5.5 task was:
path-tracing-reverse: $3.34
The total cost of the run is again a fraction of what Opus 4.8 cost me:
GPT-5.5: ~$11.34 ($5/M input, $30/M output)
Claude Opus 4.8: $13.42 (+~$10) ($5/M input, $25/M output)
💁 The cost of Opus again is not completely accurate. The cancelled
regex-chessrun did not give us the final cost, after running for approx 1 hour before I stopped it.
Token usage was also kinda interesting:
Uncached input: 1,114,940
Output: 126,107
Cached input: 3,930,112
So GPT-5.5 used a lot of uncached input, but the output token usage stayed much lower compared to Opus 4.8.
Even with that higher output price, GPT-5.5 still ended up cheaper in this run because it generated far fewer output tokens and used much less cached input.
Here’s the entire GPT-5.5 test run summary with cost, input, and output token usage:
Task | Trials | Avg Duration | Errors | Uncached Input | Output | Cached Input | Cost |
|---|---|---|---|---|---|---|---|
terminal-bench/feal-differential-cryptanalysis | 1 | 3m 8s | 0 | 24,993 | 5,569 | 87,168 | $0.34 |
terminal-bench/fix-code-vulnerability | 1 | 1m 31s | 0 | 57,842 | 2,045 | 189,184 | $0.45 |
terminal-bench/llm-inference-batching-scheduler | 1 | 3m 34s | 0 | 114,440 | 11,530 | 222,080 | $1.03 |
terminal-bench/make-mips-interpreter | 1 | 7m 15s | 0 | 325,492 | 23,072 | 1,185,408 | $2.91 |
terminal-bench/password-recovery | 1 | 1m 8s | 1 | 9,788 | 1,127 | 28,288 | $0.10 |
terminal-bench/path-tracing-reverse | 1 | 5m 18s | 0 | 480,135 | 14,534 | 999,040 | $3.34 |
terminal-bench/regex-chess | 1 | 9m 3s | 0 | 27,059 | 20,885 | 167,424 | $0.85 |
terminal-bench/torch-pipeline-parallelism | 1 | 12m 29s | 0 | 25,245 | 16,067 | 265,600 | $0.74 |
terminal-bench/torch-tensor-parallelism | 1 | 7m 8s | 0 | 15,665 | 10,249 | 143,744 | $0.46 |
terminal-bench/write-compressor | 1 | 9m 41s | 0 | 34,281 | 21,029 | 642,176 | $1.12 |
Claude Opus 4.8
Claude Opus 4.8 was slower in this run.
The biggest issue was regex-chess. It ran for 58m 5s, and just froze, literally.

Because of that, I had to run Opus 4.8 in two sessions. The first session got stuck on regex-chess for almost an hour with no real progress, so I stopped it and ran the remaining in a second session.
Because of that, the total runtime, including the cancelled task, comes out to around:
Opus 4.8 total: ~2h 22m 54s
The longest completed Opus 4.8 task was:
path-tracing-reverse: 17m 12s
The most expensive completed Opus 4.8 task was:
make-mips-interpreter: $3.55
The known cost we got from the completed task, excluding the regex-chess comes around:
Claude Opus 4.8: $13.42 (+~$10)
Again, the plus sign matters because the cancelled regex-chess task did not report a final cost. But in the Claude dashboard, I could see around $10 more usage than what was shown.
The interesting part is the password-recovery test. GPT-5.5 failed it, but Opus 4.8 completed it in 3m 53s.
Even though Opus was expensive and slower, it did solve one task that GPT-5.5 couldn't. That's the only good side of this run.
Token usage was much higher on Opus 4.8:
Uncached input: 662,502 (GPT-5.5: 1,114,940)
Output: 422,758 (GPT-5.5: 126,107)
Cached input: 15,387,898 (GPT-5.5: 3,930,112)
The difference in output tokens is the largest. Opus 4.8 generated around 3.35x more output tokens than GPT-5.5, which is wild.
Here’s the entire Claude Opus 4.8 test run summary with cost, input, and output token usage:
Task | Trials | Avg Duration | Errors | Uncached Input | Output | Cached Input | Cost |
|---|---|---|---|---|---|---|---|
terminal-bench/feal-differential-cryptanalysis | 1 | 4m 1s | 0 | 20,440 | 14,355 | 120,457 | $0.54 |
terminal-bench/fix-code-vulnerability | 1 | 1m 28s | 0 | 8,986 | 1,727 | 123,016 | $0.16 |
terminal-bench/llm-inference-batching-scheduler | 1 | 13m 37s | 0 | 70,092 | 48,656 | 1,816,147 | $2.56 |
terminal-bench/make-mips-interpreter | 1 | 16m 14s | 0 | 102,835 | 61,540 | 2,748,918 | $3.55 |
terminal-bench/password-recovery | 1 | 3m 53s | 0 | 21,286 | 12,019 | 400,762 | $0.63 |
terminal-bench/path-tracing-reverse | 1 | 17m 12s | 0 | 114,838 | 68,368 | 1,797,550 | $3.32 |
terminal-bench/regex-chess | 1 | 58m 5s | 1 | 236,246 | 145,655 | 7,669,059 | - |
terminal-bench/torch-pipeline-parallelism | 1 | 13m 34s | 0 | 30,281 | 24,642 | 235,099 | $0.92 |
terminal-bench/torch-tensor-parallelism | 1 | 5m 43s | 0 | 16,595 | 12,714 | 153,767 | $0.50 |
terminal-bench/write-compressor | 1 | 9m 7s | 0 | 40,903 | 33,082 | 323,123 | $1.24 |
Final Verdict
This is only 10 hard tasks from Terminal-Bench 2.1, not the full benchmark.
There are still around 59 easy, medium and other hard tasks I didn’t run, so I wouldn’t treat this as some final answer on which model is better.
If we count the Opus 4.8 run getting stuck on regex-chess as a failed task, then the result is actually pretty close. Both models had one task that didn’t go well.
GPT-5.5 was faster and cheaper in this run. Opus 4.8, solvedpassword-recovery, which GPT-5.5 failed.
For this run, GPT-5.5 was more efficient.
Automating the Benchmark Workflow with Composio
Now that we’re already in the flow, how about we do a little more than just the Terminal-Bench 2.1 test? 😉
The idea is to build an application that parses the task outputs, logs, and run results, then gives us a dashboard where we can take actions on top of them
By that I mean, we could generate a summary of the run and post it to Slack, create a Notion report, or create Linear tickets for failed tasks.
The possibilities are endless. And to build this, we will use Composio.
Claude Opus 4.8
Opus 4.8 is actually pretty damn good at the frontend. That was my first thought after seeing the UI.
But the other thing is that this model is just so slow and token-heavy that you are probably going to spend twice as much, or maybe even more, than running the same thing with GPT-5.5, which is already an expensive model.
This whole run of building the automation app cost me $28. Let that sink in.
And honestly, the app itself was not complex enough to justify that kind of cost.
Again, it took more than an hour of continuous building, fixing, and going back and forth.
I ran into so many errors that I could not even document them properly.
The other thing is that this model hallucinated a LOT. Probably the worst experience I have had with any Opus model so far, even compared to 4.6.
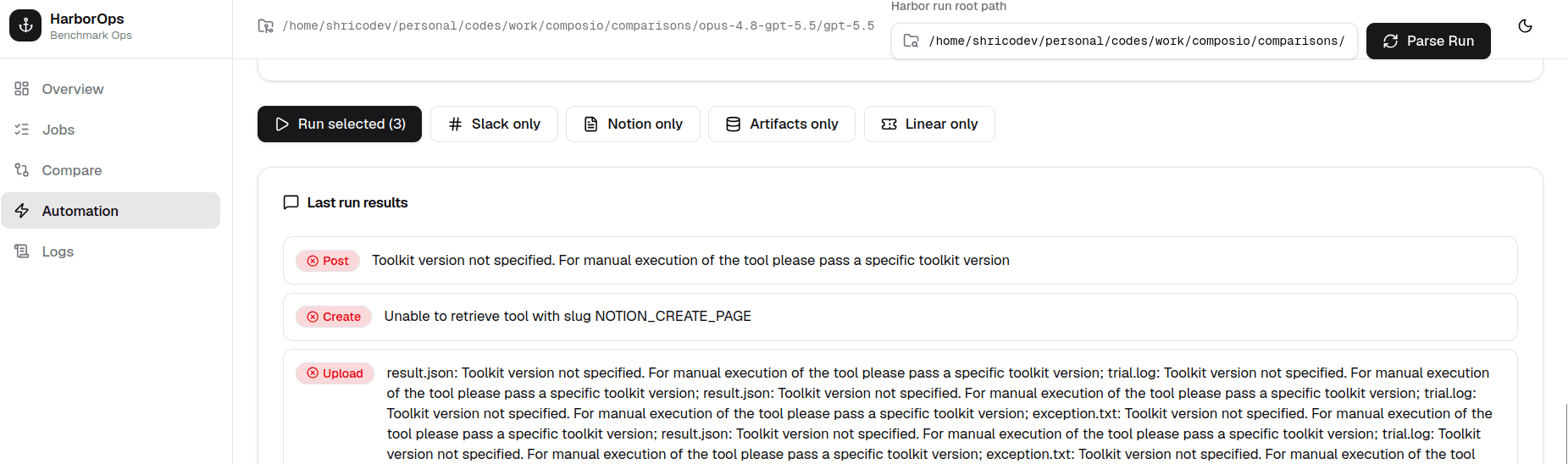
After hours of debugging, I finally got a working build. But there were so many loopholes and so many DIY-style fixes that I honestly would not trust this code in production.
Here’s the demo:
The only good part is that, after all of this, it worked.
I had high hopes for this model in this run, but it completely smoked me.
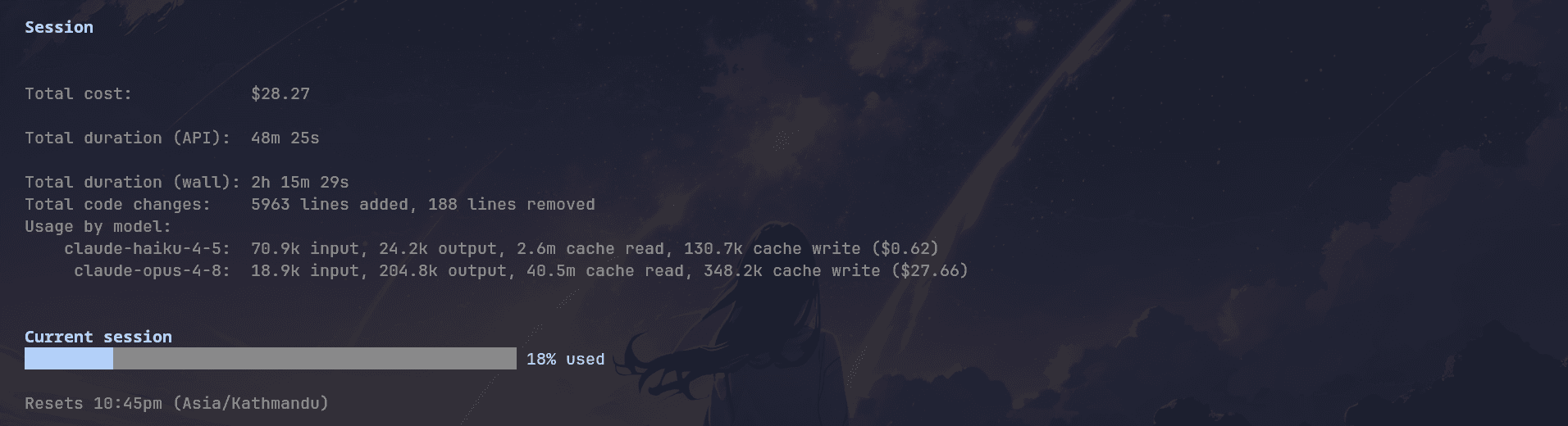
Cost: ~$28.27
Duration: ~2h 15min 29sec
API Duration: ~48min 25sec
Code Changes: +5,963 lines, 188 lines removed
Usage by Model: Claude Haiku 4.5: 70.9k input, 24.2k output, 2.6m cache read, 130.7k cache write
Usage by Model: Claude Opus 4.8: 18.9k input, 204.8k output, 40.5m cache read, 348.2k cache write
Context Window Used: 18%
GPT-5.5
GPT-5.5 was a bit of a disappointment.
Though, to be fair, I kind of expected it. This model has not been the best for me in real-world use cases so far, so there’s that.
The thing is, it got me a somewhat broken product that only had parts working in no time. It took around 15 to 20 minutes.
There were also minor TypeScript type errors that it kept trying to fix repeatedly.
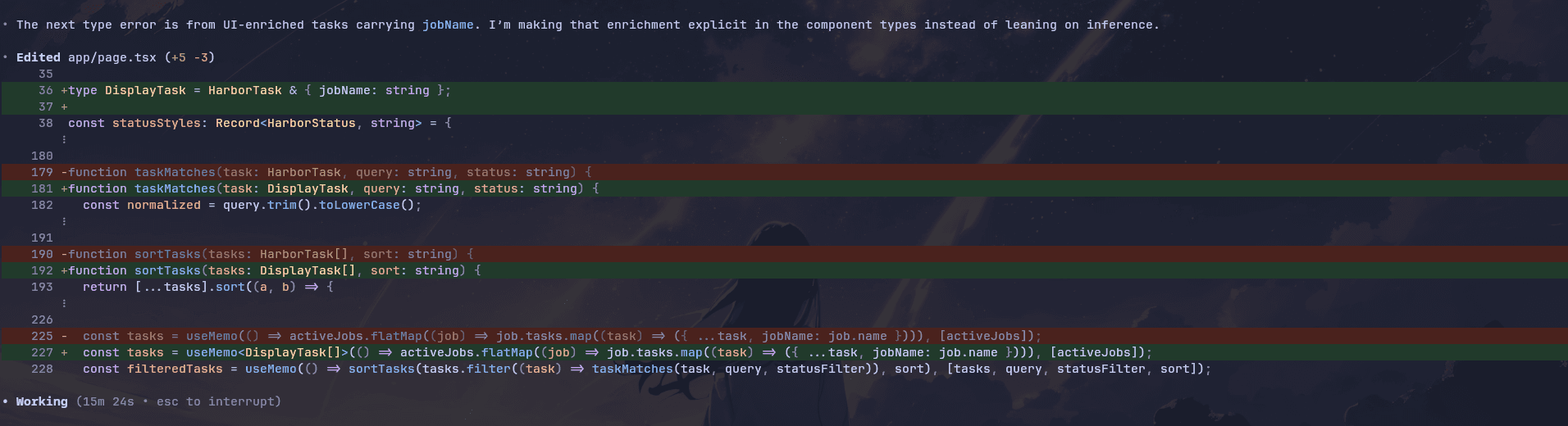
Here’s the demo:
Another thing I noticed is that Claude Opus 4.8 is definitely better in real-world use cases. Even with this simple app idea, if you look at the overall frontend, Opus 4.8 produced much better output than GPT-5.5.
This was a test I did on a subscription plan, so I don’t have the exact cost. Here’s a small breakdown:
Duration: ~20 min
Code Changes: 17 files changed, 2,685 insertions(+), 147 deletions(-)
Context Used: 57% (118K used / 258K)

💁 I didn’t have much hope with this general model. I just ran this test along with Opus 4.8 to give you an idea. That’s it. From my personal experience so far, this model does not compare to Opus 4.8 on anything other than Terminal-Bench 2.1.
Final Verdict
Yes, Opus 4.8 is good.
But don’t expect some massive jump where you instantly feel everything is different from Opus 4.7.
From what I’ve seen, it seems like a small improvement over Opus 4.7, which the benchmark numbers also suggest. Better, yes. Completely different, no. ❎

I’ve been using it continuously for around two days now, and honestly, it’s decent. I don’t think it is bad.
The experience will probably depend a lot on how you use it. If your work involves long context, tool calls, debugging, and agentic coding, you might notice the improvements more.
If you mostly use it for regular coding, it may feel almost the same.