OpenAI just shipped GPT-5. It’s built on top of the GPT and O-series reasoning models, aiming to be faster, smarter, and more efficient. I put it head‑to‑head with Anthropic’s Claude Opus 4.1 to see which one actually helps more with real dev work.
All the generated code from this comparison can be found here: github.com/rohittcodes/gpt-5-vs-opus-4-1.
TL;DR
Don't have time? Here's what happened:
Algorithms: GPT‑5 wins on speed and tokens (8K vs 79K)
Web dev: Opus 4.1 matched the Figma design better but cost more tokens (900K vs 1.4M+ tokens)
Overall, GPT-5 is the better everyday development partner (fast and cheaper), costs ~90% less tokens than Opus 4.1. If design fidelity matters and budget is flexible, Opus 4.1 shines.
Cost: GPT‑5 (Thinking) ~$3.50 vs Opus 4.1 (Thinking, Max) $7.58 (~2.3×) for converting Figma design to code.
GPT-5 vs. Opus 4.1
Claude Opus 4.1 comes with a 200K token context window. GPT-5 bumps this up to 400K tokens with a maximum output of 128K. Despite having double the context space, GPT-5 consistently uses fewer tokens to achieve the same work, making it more cost-effective to run.
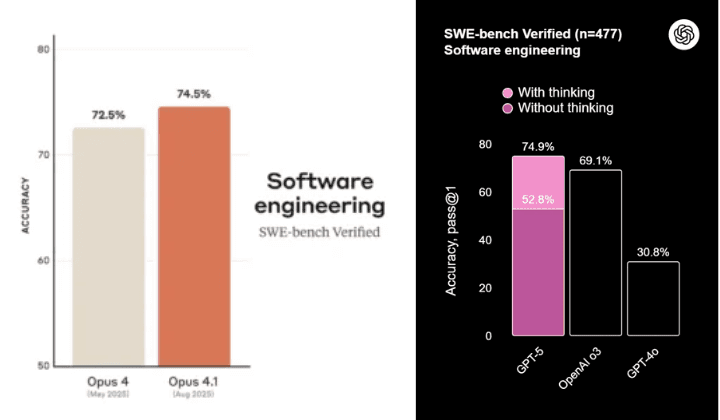
SWE-bench results show GPT-5 is slightly ahead of Opus 4.1 on coding benchmarks, but benchmarks don't tell the whole story. That's why I tested them on real tasks.
How I tested these models
I ran both models through identical challenges:
Languages: Java for algorithms, TypeScript/React for building web apps
Tasks:
Figma design to NextJS code via Rube MCP - universal MCP layer (this is our new product btw, try it out, it's awesome.
Leetcode Advanced
A customer churn predictor model pipeline
Environment: Cursor IDE with Rube MCP integration
Measure: Token usage, time taken, code quality, actual results
Both got the exact same prompts to keep things fair.
Rube MCP - Universal MCP Server
Rube MCP (by Composio) is the universal connection layer for MCP toolkits like Figma, Jira, GitHub, Linear, and more. Explore toolkits: docs.composio.dev/toolkits/introduction.
How to connect:
Go to rube.composio.dev.
Click “Add to Cursor”
Install the MCP Server when prompted and enable it.
Coding Comparison
1) Round 1: Figma design cloning
I picked a complex dashboard design from Figma Community and asked both models to recreate it using Next.js and TypeScript. Figma design: link. I plugged our universal MCP and have it converted to HTML, CSS, and Typescript.
Prompt:
Create a Figma design clone using the given Figma design as a reference: [FIGMA_URL]. Use Rube MCP's Figma toolkit for this task.
Try to make it as close as possible. Use Next.js with TypeScript. Include:
- Responsive design
- Proper component structure
- Styled-components or CSS modules
- Interactive elementsGPT‑5 results
GPT-5 delivered a working Next.js app in about 10 minutes using 906,485 tokens. The app functioned well, but the visual accuracy was disappointing. It captured the basic idea but missed tons of design details, colours, spacing, typography, all noticeably different from the original.
Tokens: 906,485
Time: ~10 minutes
Cost: Reasonable for the output

Claude Opus 4.1 results
Opus 4.1 burned through 1.4M+ tokens (55% more than GPT-5) and initially got stuck on Tailwind configuration, despite my specific request for styled-components. After I manually fixed the config issues, the result was stunning; the UI matched the Figma design almost perfectly. Way better visual fidelity than GPT-5.
Tokens: 1,400,000+ (~55% more than GPT‑5)
Time: Longer due to more iterations
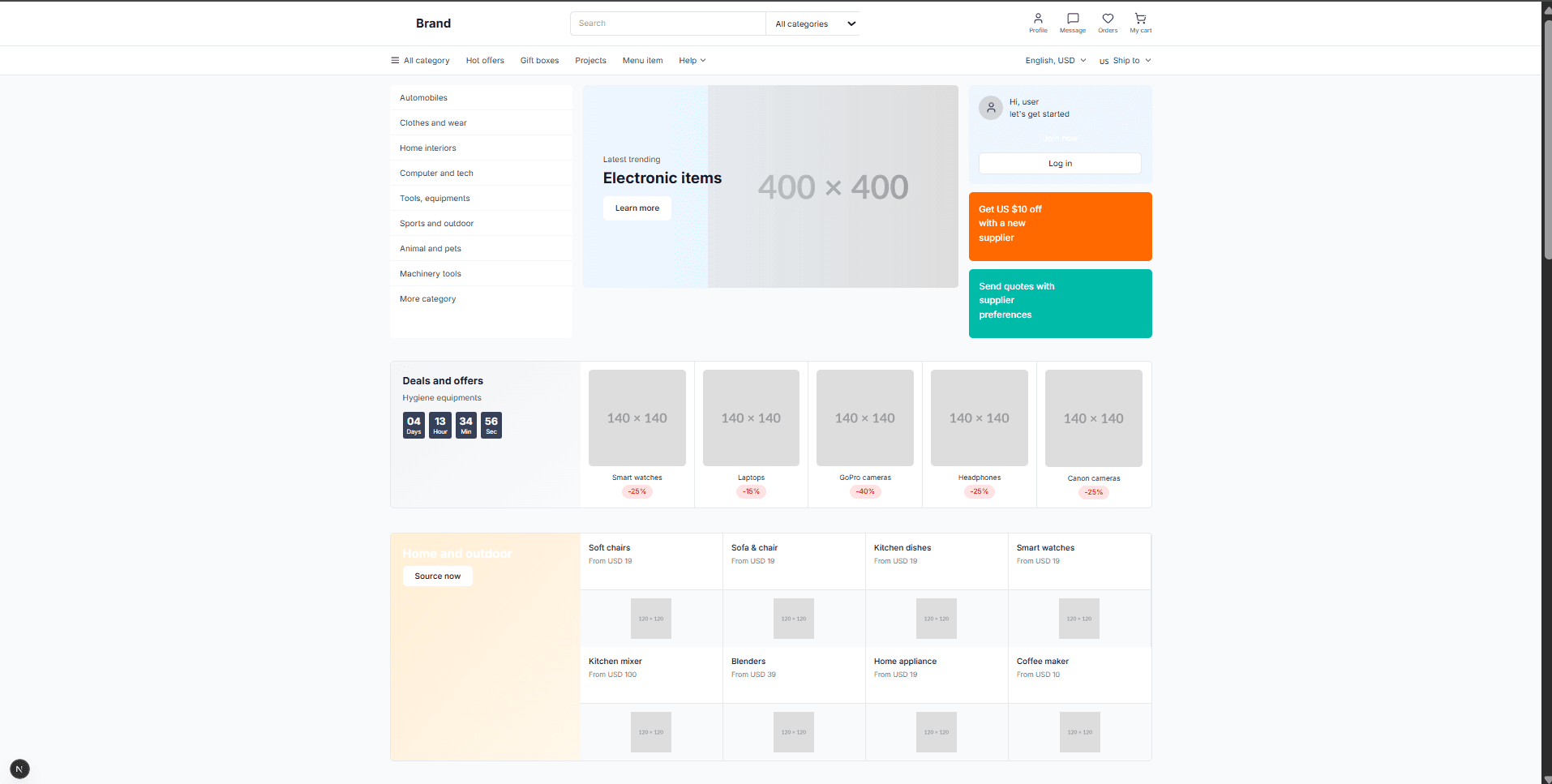
Opus 4.1 delivered far better visual fidelity, but at a higher token cost and with some manual setup.
2) Algorithm challenge
I threw the classic "Median of Two Sorted Arrays" LeetCode hard problem at both models. This tests mathematical reasoning and optimisation skills with a O(log(m+n)) complexity requirement. This is not at all a difficult problem for these models, and most probably in the training data. All I wanted to know was how fast and token-efficient they are.
Prompt:
For the below problem description and the example test cases try to solve the problem in Java. Focus on edge cases as well as time complexity:
Given two sorted arrays nums1 and nums2 of size m and n respectively, return the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
Example 1:
Input: nums1 = [1,3], nums2 = [2]
Output: 2.00000
Example 2:
Input: nums1 = [1,2], nums2 = [3,4]
Output: 2.50000
Template Code:
class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
}
}GPT‑5 results
Straight to business. Used 8,253 tokens in 13 seconds and delivered a clean O(log(min(m,n))) binary search solution. Proper edge case handling, optimal time complexity. Just works.
Tokens: 8,253
Time: ~13s
Claude Opus 4.1 results
Much more thorough. Consumed 78,920 tokens across multiple reasoning steps (almost 10x more than GPT-5). Took a methodical approach with detailed explanations, comprehensive comments, and built-in test cases: same algorithm, way more educational value.
Tokens: 78,920 (~10× more, across multiple reasoning steps)
Time: ~34s

Both solved it optimally. GPT-5 used approximately 90% fewer tokens.
3) ML/Reasoning task (and cost reality)
I planned a third, bigger test around ML and reasoning: building a churn prediction pipeline end‑to‑end. After seeing Opus 4.1 use 1.4M+ tokens on the web app, I skipped running it there due to cost. I did run GPT‑5.
Prompt
Build a complete ML pipeline for predicting customer churn, including:
1. Data preprocessing and cleaning
2. Feature engineering
3. Model selection and training
4. Evaluation and metrics
5. Explain the reasoning behind each step in detailGPT‑5 results
Tokens: ~86,850
Time: ~4-5 minutes
GPT‑5 produced a solid, working pipeline: clean preprocessing, sensible feature engineering; multiple models (Logistic Regression, Random Forest, optional XGBoost with randomized search); SMOTE for class balance, best‑model selection via ROC‑AUC, and thorough evaluation (accuracy, precision, recall, F1). The explanations were clear without being verbose.
What does it cost for the test (real numbers)
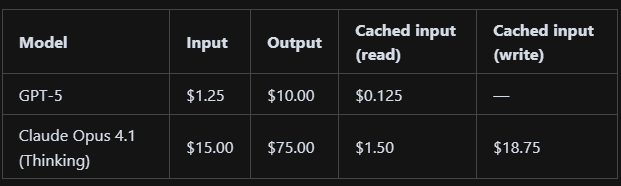
GPT‑5 (Thinking): ~$3.50 total - Web app ~$2.58, Algorithm ~$0.03, ML ~$0.88. It wasn’t as expensive as Opus-4.1.
Opus 4.1 (Thinking + Max mode on cursor): $7.58 total - Web app ~$7.15, Algorithm ~$0.43.
Conclusion
Both models use large context windows well, but they spend tokens differently, hence the big cost gap.
GPT‑5 strengths
~90% fewer tokens on algorithm tasks
Faster and more practical day‑to‑day
Cost‑effective for most work
Opus 4.1 strengths
Clear, step‑by‑step explanations
Great for learning as you code
Excellent design fidelity (very close to Figma)
Deep analysis when you can afford it
My take? Use GPT‑5 for algorithms, prototypes, and most day‑to‑day work; it’s faster and cheaper. Choose Opus 4.1 when visual accuracy really matters (client‑facing UI, marketing pages) and you can budget more tokens. Practical flow: build the core with GPT‑5, then use Opus 4.1 to polish key screens.