Moonshot Labs has released the Kimi k2, a new state-of-the-art open-source model purpose-built for agentic tasks, a direct rival of Claude 4 Sonnet, but at ~one-tenth the cost.
It is a non-thinking model with one trillion parameters and an approximate size of ~960 GB. In comparison, the Deepeek v3 has a 671B param and ~685GB in disk size (in original fp 16). So, if you want to host and run the model, you’d need roughly 10-12x H100 or 16x A100. For 4-bit quantised models, you’d need 3x H100 and 10 RTX 4090. The only way you’re getting these is if you received Meta’s exploding offers.
The model, just after the launch, got immense fanfare from the open model enthusiasts while scorn from many OpenAI employees.
Kimi AI has made this model exclusively for agentic applications. What Deepseek v3 was for GPT 4, Kimi k2 is for Claude 4 Sonnet.

Yang Zhilin and Kimi
Kimi is the flagship product from Moonshot AI, founded in March 2023 by three co-founders, Yang Zhilin (杨植麟) – CEO, Zhou Xinyu (周昕宇), and Wu Yuxin (吴雨欣). Yang pursued a Phd from CMU in AI/ML, following prior studies at Tsinghua University.
Interestingly, the name Moonshot was inspired by PinkFloyd’s album The Dark Side of the Moon, a favourite of Yang.

Yang was also the first author of XLNet and TransformerXL. They were the first models in Hugging Face's Transformers library.
A very good post from Justin Wang from Moonshot on Kimi K2 and the model-product relationship in the AI coding era.
Wang’s note on why open-source,

They noticed the agents without Claude are useless, so they made an open-source alternative to Claude.

Things you love to read,

Kimi K2 architecture design analysis
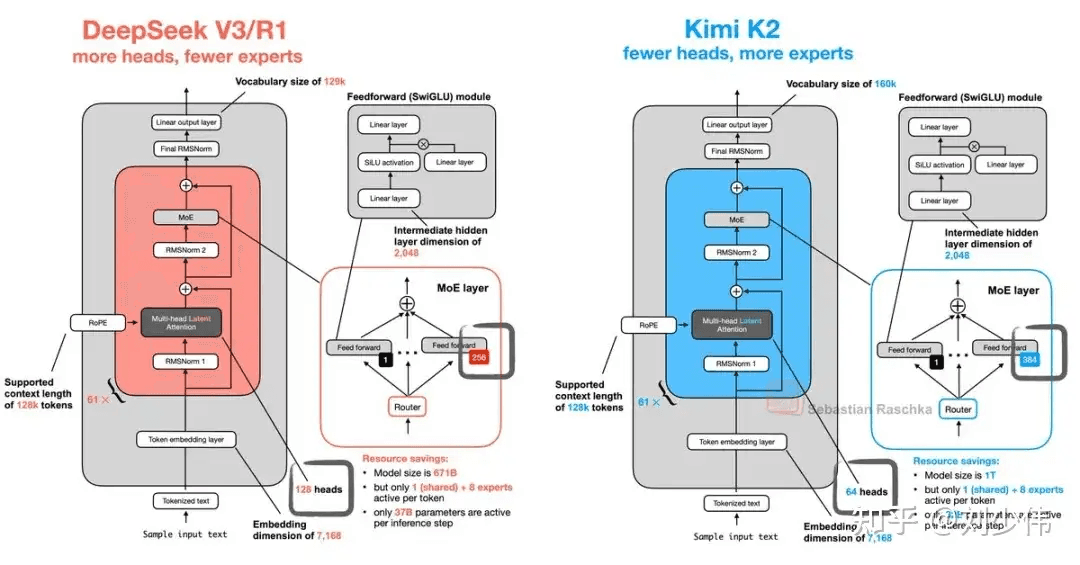
One of the key design decisions was to borrow what was already working and improve on areas where possible. The Kimi team conducted a thorough scaling experiment related to model structure, ultimately narrowing it down to Deepseek v3, as there wasn’t anything beating it. If you look at the config files of Deepseek v3 and Kimi k2, they would look identical except for some subtle changes, which resulted in drastic improvements in LLM performance.
The K2 is a one-trillion-parameter MoE transformer model with 32 billion active parameters, comprising 384 experts, each activated per token.
Improvements over DsV3
The information is from Liu Shaowi’s post on Zhihu on Kimi K2.
Number of experts = 384 vs. 256:
The team observed that adding more experts doesn’t violate the scaling law, meaning the train and test losses keep dropping. This helps the model achieve lower loss and higher effective capacity without increasing the number of activated parameters or the computational cost during inference. However, this also means an increase in the overall model weight footprint, which raises memory-bandwidth pressure during the decode phase and disk/VRAM requirements.
Number of Attention Heads = 64 vs. 128:
An increased number of experts swelled the model size by 2.5GB per rank (~50%↑ overall), and to reduce the memory footprint, they halved the number of attention heads compared to DsV3.
This halving shrinks the Q/K/V projection matrices from 10 GB to 5 GB per rank, cutting both activation memory traffic and prefill latency in half while leaving the KV-cache untouched. The loss ablation confirmed that the MoE gain far outweighs the quality drop, so the 5 GB saved per rank more than compensates for the extra 2.5 GB taken by the 384 experts, yielding a net 2.5 GB memory saving at every parallel rank and freeing headroom for longer contexts or larger batch sizes.
With half the number of heads, the overall attention FLOPs get halved (Attention FLOPs ∝ h s²). This was in line with their vision of making Kimi K2 ideal for agentic tasks where input length is significant (tool descriptions, logs, code bases, etc). The h in the equation is the number of attention heads, and s is the sequence length.
first_k_dense = 1 vs 3:
The router in the very first MoE layer has a tough time balancing tokens across experts, but it wasn’t an issue for later layers. So, the first MoE layer was replaced by a dense FFN. This adds no strain on the prefill stage and is very negligible (~100s of MB) in weight per GPU rank during the decode stage.
n_group = 1 vs. 8:
As the model is huge, with 384 experts, and the Expert parallel (EP) degree is large, only one expert could be accommodated in a GPU device. The old trick of grouping experts inside a single GPU no longer helps even out the work, so they dropped the groups (n_group = 1). The real balancing is handled by EPLB’s dynamic re-sharding and extra expert replicas, while the router is left free to choose any expert combination, which slightly improves model quality.
Summary
Although the model size was increased by 1.5 times, the Kimi team was able to claw back the extra memory and latency cost by halving the attention heads (saving ~5 GB per GPU rank), keeping only the first layer dense (a few-hundred-MB hit), and eliminating expert grouping—yielding a net per-rank memory reduction and no-worse decode time compared to DeepSeek-V3.
Muon Optimizer
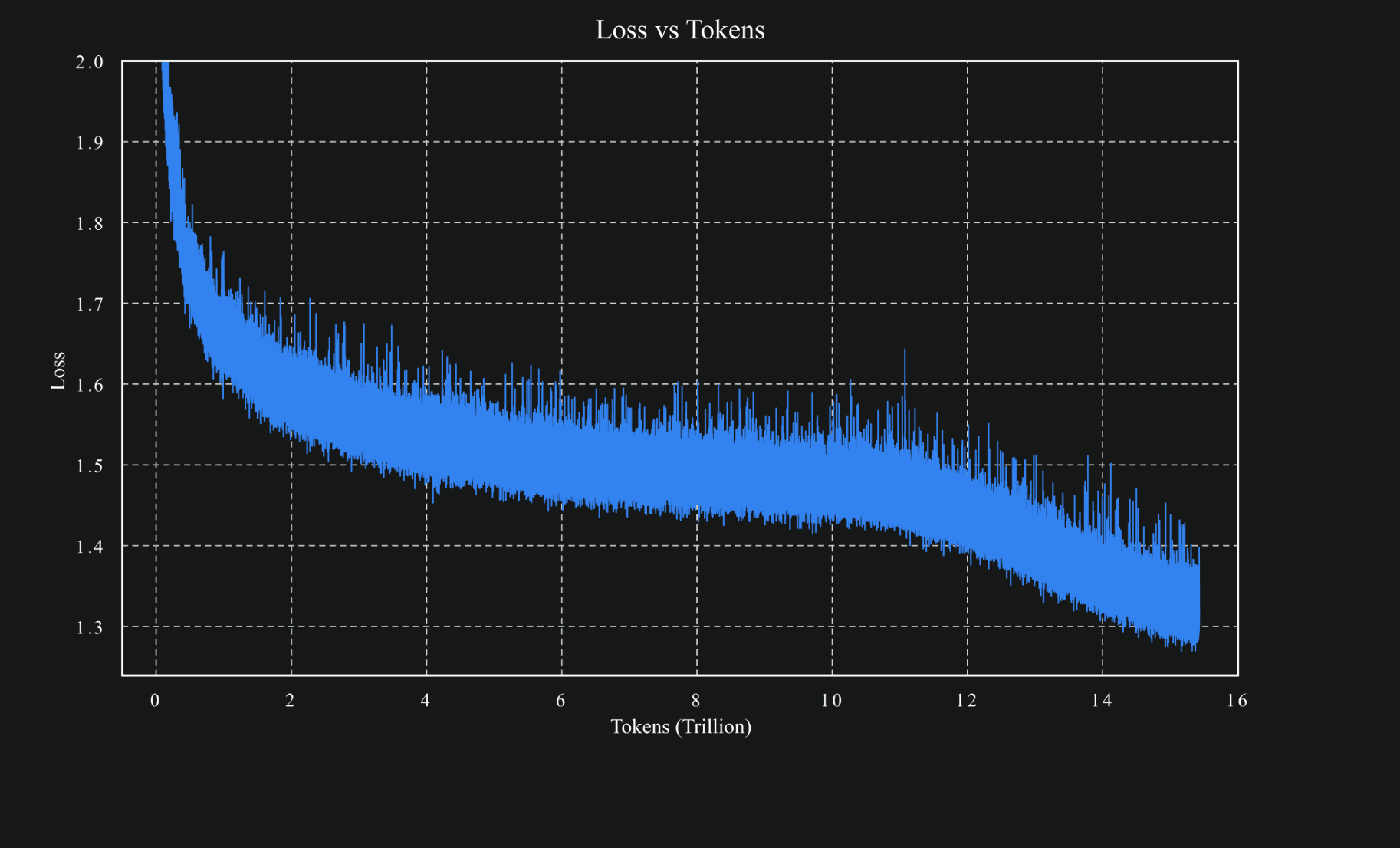
Muon was a key ingredient that made a significant difference to Kimi K2’s performance. Instead of going with the industry standard, AdamW, the Kimi opted for Muon, a much less popular alternative.
With their Moonlight project, they validated that Muon works with small-scale LLMs, but it had not yet been validated for bigger models like Kimi K2.
While it was promising, there was a reason why AdamW is the industry standard.
While scaling up, we encountered a persistent challenge: training instability caused by exploding attention logits, an issue that occurs more frequently with Muon but less with AdamW in our experiments. Existing solutions such as logit soft-capping and query-key normalization were found inadequate.
- Kimi K2 blog post
To retain Muon’s token-efficiency while eliminating its instability, Kimi introduced MuonClip, a drop-in extension that adds qk-clip:

Probably the most circulated image in the context of Kimi K2 training. MuonClip was instrumental in stabilising the decay at such a large scale.
RL for Agentic Abilities
The Kimi team conducted extensive reinforcement learning to make the model ideal for agentic use cases. They did two main things
Generate synthetic data for tool use
General RL
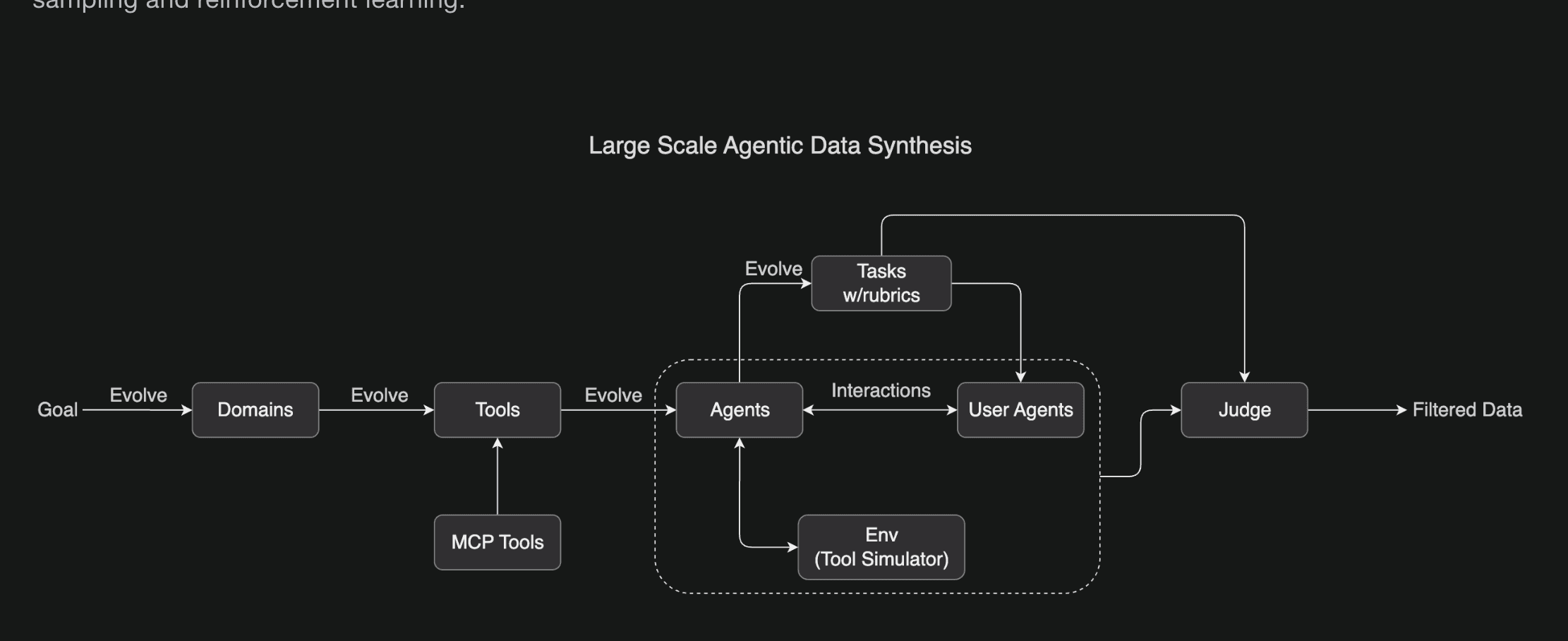
Large-Scale Agentic Data Synthesis for Tool Use Learning: To teach the model sophisticated tool-use capabilities, we developed a comprehensive pipeline inspired by ACEBench that simulates real-world tool-using scenarios at scale. Our approach systematically evolves hundreds of domains containing thousands of tools—including both real MCP (Model Context Protocol) tools and synthetic ones—then generates hundreds of agents with diverse tool sets.
All tasks are rubric-based, enabling consistent evaluation. Agents interact with simulated environments and user agents, creating realistic multi-turn tool-use scenarios. An LLM judge evaluates simulation results against task rubrics, filtering for high-quality training data. This scalable pipeline generates diverse, high-quality data, paving the way for large-scale rejection sampling and reinforcement learning.
General Reinforcement Learning: The key challenge is to apply RL to tasks with both verifiable and non-verifiable rewards; typical examples of verifiable tasks are math and competition coding, while writing a research report is usually viewed as non-verifiable. Going beyond verifiable rewards, our general RL system uses a self-judging mechanism where the model acts as its own critic, providing scalable, rubric-based feedback for non-verifiable tasks.
Meanwhile, on-policy rollouts with verifiable rewards are used to continuously update the critic so that the critic keeps improving its evaluation accuracy on the latest policy. This can be viewed as a way of using verifiable rewards to improve the estimation of non-verifiable rewards.
I’ve been using their chat app on kimi.com, and I can attest to how well K2’s tool uses its capabilities to enhance search. This is much better than what we had with Deepseek v3.
Though I am yet to test the model on actual tool use, going with what people are talking about, it seems on par with Claude 4 Sonnet, if not better.
Having a model 1/12th of the cost of the Claude 4 Sonnet is what we call progress.
Kimi K2 Capability
At the end of the day, this is what people pay the most attention to, and the K2 doesn’t disappoint. It is rightfully the SOTA in open-source. And while I was writing this blog post, I asked a lot of dumb questions to it, the interesting thing is it doesn’t assume you’re dumb, unlike ChatGPT, Claude, and Gemini.
The way it talks is more normal, zero-sycophancy, and precise. No doubt it has scored the highest in the Creative Writing bench. One of the benches, you’d actually trust.
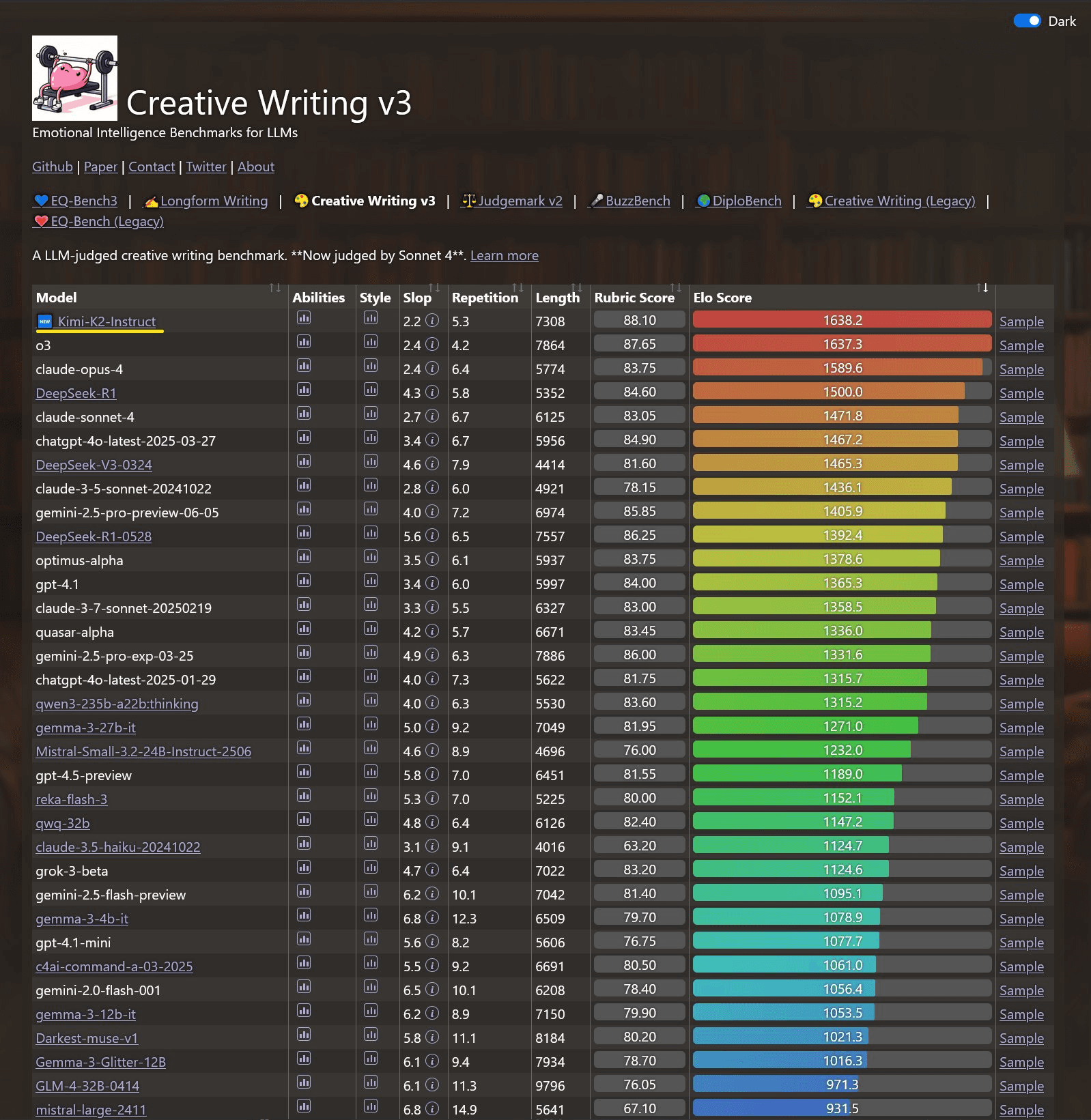
You can find all other benchmark details on their official release post. They are really impressive.
Comparison with Claude 4 Sonnet
What I mostly care about in a model is how natural they are in human conversations and how aesthetically pleasing their abilities can be. These are not real-world use cases, and I am sure most are not. They reflect the creativity of the model weights, and I have yet to see a bad model outperform a good one in this regard.
Sisyphus, Icarus, and Narcissus
This is a small test to assess the creativity of each model, where they must write a short play featuring the three most popular Greek Mythology characters conversing with one another.
The prompt:
Write a short play with characters Sisyphus, Icarus, and Narcissus in the 21st century. While the era is different, they retain their original characteristics and the lore but with a modern flavour to it. They are long-distance friends and once they decided to meet at a place, they used. to meet in their college days. Time has passed, and each is reminiscing about their lives so far. It should be humorous but still thought provoking. The humour should be understated and not forced. Contrary to expectation, almost none of their talk involve boulder rolling, flying close to sun, and falling in love with the reflection metaphors (though they do sneak one each subtle in there). We are also going against the obvious fish-out-of-water trope; in fact, they are surprisingly natural. In all of this , it's important to show, don't tell. 1000 words.
The output was interesting; you can check both responses here, Kimi K2 and Sonnet 4.
Before I formed my conclusions, I asked Claude 4 Opus to judge both of them.
This was the verdict. Response 1 was Kimi’s, and Response 2 was Sonnet’s.
Verdict: Response 1 is significantly superior. It achieves the delicate balance of being "humorous but thought-provoking" through lines that work on multiple levels, creates a more authentic modern setting that doesn't feel like a gimmick, and demonstrates mastery of the theatrical form. The ending alone - with its meditation on failure, success, and the pigeon's simple claim to presence - elevates it beyond mere cleverness to genuine insight.
Response 1 best fulfills the prompt's challenging requirements, particularly the demand for subtlety, natural integration, and showing rather than telling.
This is close to what I felt. Kimi K2 is more natural and sets the tone and backdrop of the play more vividly. Claude 4 Sonnet was good, but lacked narrative depth. Humour was more natural in Kimi’s response.
Particle Simulation
A simple simulation that I usually do to test the taste of the models. Here’s the prompt:
Implement a single‐file HTML+JavaScript demo using Three.js and WebGL that displays a cloud of GPU‐accelerated particles which the user can morph among several predefined shapes. Your code must import and use anything that's required. here's some that you might require:
The demo must include:
Particle System & Morph Targets
Start with particles arranged as a sphere.
Provide three alternative morph targets:
A sphere
A stylized bird in flight
A human face
A tree
Smoothly tween particle positions when switching targets.
Post‐Processing & Lighting
Set up an EffectComposer with a RenderPass and an UnrealBloomPass.
Use GammaCorrectionShader to correct final output.
Add minimal ambient + directional light so morph targets are visible.
Camera & Controls
Use OrbitControls for mouse/touch rotation, pan, and zoom.
Center the camera on the particle cloud.
UI Sliders & Dat.GUI (or similar)
Particle size (range 0.1 → 5.0)
Rotation speed (−2.0 → 2.0 radians/sec)
Particle color (hue selector or hex input)
Bloom strength (0.0 → 3.0)
Motion trail opacity (0.0 → 1.0)
Morph target selector (Sphere, Face, Bird, Text)
Performance Considerations
Use a single BufferGeometry with custom attributes to drive GPU particle positions.
Update positions in a ShaderMaterial vertex shader.
No External Assets
Procedurally generate geometry for the face mesh, bird, and text.
You may use Three.js’s built-in TextGeometry or simple custom paths.
Deliverables
A single index.html file containing all HTML, CSS, and JS.
Inline <script> and <style> tags only—no module bundler.
Thorough comments explaining:
How morph targets are built and interpolated
Shader logic for GPU particle updates
How postprocessing pipeline is assembled
Remember: your goal is to implement a complete, runnable demo in one shot. Reason step‐by‐step to ensure you include every import, initialization, GUI control, morph target, and postprocessing pass correctly.Kimi K2’s response
Sonnets' response
I mean, Kimi somehow not only has better aesthetics but also did this in two attempts, clean. The Sonnet was out of context and required another three iterations to address minor issues. However, it’s not a general representation of their coding skills. K2 seems to be better than Claude 4 Sonnet so far.
Final Note
There is always satisfaction in seeing the open-source model improving. Deepseek v3 and r1 closed the gap with proprietary models, and now Kimi K2 has taken a step further, becoming the SOTA non-reasoning model with a price 1/12th that of Claude 4 Sonnet. This is going to unlock a different level of agentic applications, and we're at Composio here to power it.