

Kimi K2.5 vs. Opus 4.5: David vs. Goliath for AI Coding Agents
Kimi K2.5 vs. Opus 4.5: David vs. Goliath for AI Coding Agents
Moonshot AI is the Chinese Anthropic, not in the sense of their ideology, but in the general direction. From their early launch of Kimi K2, it was pretty clear they were after that juicy enterprise agent automation. The models are essentially RL'd for tool calling and code generation.
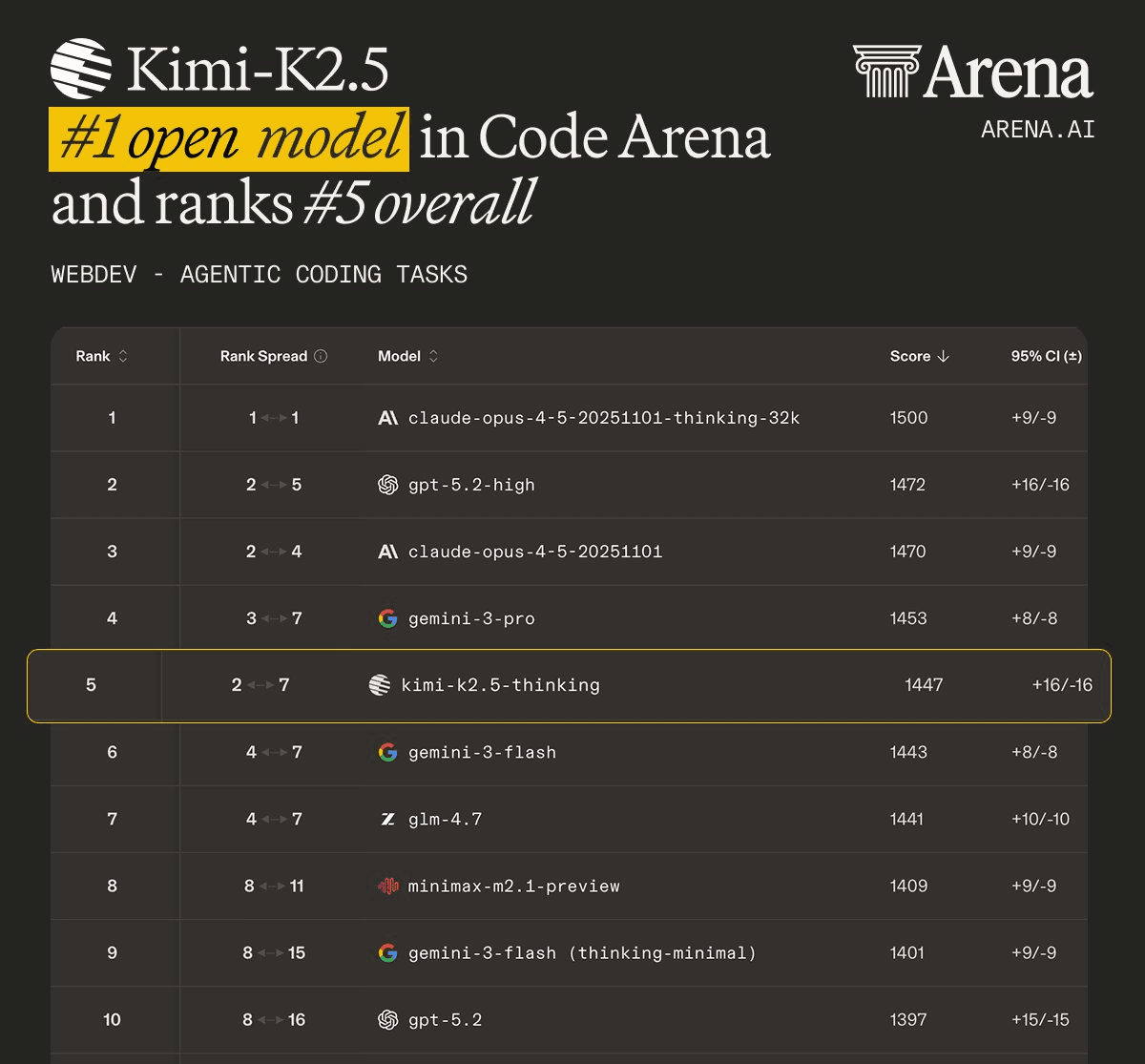
And the latest launch strengthens their position as the leading open-source alternative to Claude models. It beats frontier models on certain fronts, like frontend design, and ranks 1 on the OS-world leaderboard for real-world computer environments, while being much cheaper.
It ships with a 256K context window and a pretty wild “agent swarm” idea, where the model can spin up to 100 sub-agents and coordinate up to 1,500 tool calls for wide, long tasks.
I have been using Opus for a while; it's insanely good when paired with Claude Code, and I really wanted to see how many of the tasks Kimi K2.5 can do, so I can think about cancelling my Max subscription.
While Claude Opus 4.5 comes with $5/M input token and $25/M output token, Kimi-K2.5 is a fraction of that, at $0.45/M input token and $2.50/M output token.
To summarise the difference, Kimi-K2.5 is the open-source alternative with a bigger context window and a very agent-heavy design.
I have been using Opus for a while; it's insanely good when paired with Claude Code, and I really wanted to see how good Kimi K2.5 perform, so I can cut down on Claude expenses and save more.
TL;DR
If you want a short take on the results, here's how the two models did in two standard tests:
Kimi-K2.5: Safest overall pick in my runs. It got to a working build faster, and the “fix loop” was much shorter. Test 2 (Auth + Composio + PostHog) was the main challenge, and Opus basically just shipped it. Still the most expensive and can be a bit slow as it loves to do web searches a bit too much.
Claude Opus 4.5: Insanely good for an open model, and the price is honestly wild. Test 1 was solid after a small fix pass, but it did hit a Cesium base-layer rendering issue. Test 2 worked but felt a bit more fragile, like it needs a little more babysitting to get everything clean.
💡 If you want the safer pick for real project work, I’d still go with Opus 4.5. If cost and a bigger context window matter more and you’re okay doing some extra fixing and polishing, Kimi-2.5 is a great choice.
Test Workflow
For the test, we will use the following CLI coding agents:
Claude Opus 4.6: Claude Code with API Usage
Kimi-K2.5: Claude Code using Ollama Cloud with a Pro subscription (set up to run external models)
We will check the models on two different tasks:
Task 1: Build TerraView (Google Earth-style globe viewer)
Each model is asked to build a Google Earth-inspired web app called TerraView using Next.js (App Router). The app must ship a working 3D globe viewer with smooth pan, rotate, zoom, and a small set of base layers (for example, OpenStreetMap imagery plus at least one alternate base layer).
Task 2: Authentication + Live User Location System (Composio + PostHog)
This was a fun test that lets you visualise your users on the globe. I built it to dogfood our newly updated Posthog MCP integration. Do check it out or other SaaS toolkits to build your dream workflow.
Each model must add authentication to TerraView and integrate PostHog through Composio. Once users sign in, the app should capture their approximate location and display all active users on the globe as markers.
We’ll compare code quality, token usage, cost, and time to complete the build.
💡 NOTE: I will share the source code changes for in a
.patchfile. This way, you can easily view them on your local system by creating a brand new next.js app and applying the patch file usinggit apply <path_file_name>.
Real-World Coding Comparison
Test 1: Google Earth Simulation
Here's what I ask: I will start a brand new Next.js project, and they will begin from the same commit and follow the same prompt to build what's asked.
All the results here are evaluated from the best of 3 responses from each model, so you can expect them to be very fair. We're not judging based on a model's unlucky response.
You can find the prompt I've used here: Google Earth Prompt
If you look at the prompt, it's a lot to implement, but given how capable our models are, it shouldn't really be much of a problem. 😮💨
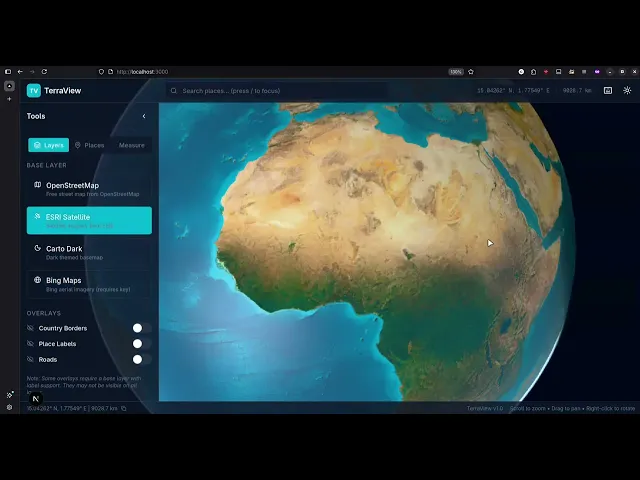
To summarise, the models are asked to build a polished Google Earth-style Next.js app with a smooth 3D globe, search, layers, pins, saved places, measuring tools, and production-ready code that runs locally out of the box.
Kimi-K2.5
Kimi K2.5 got surprisingly far on the first draft. Most of the core features were in place without me having to babysit them too much.
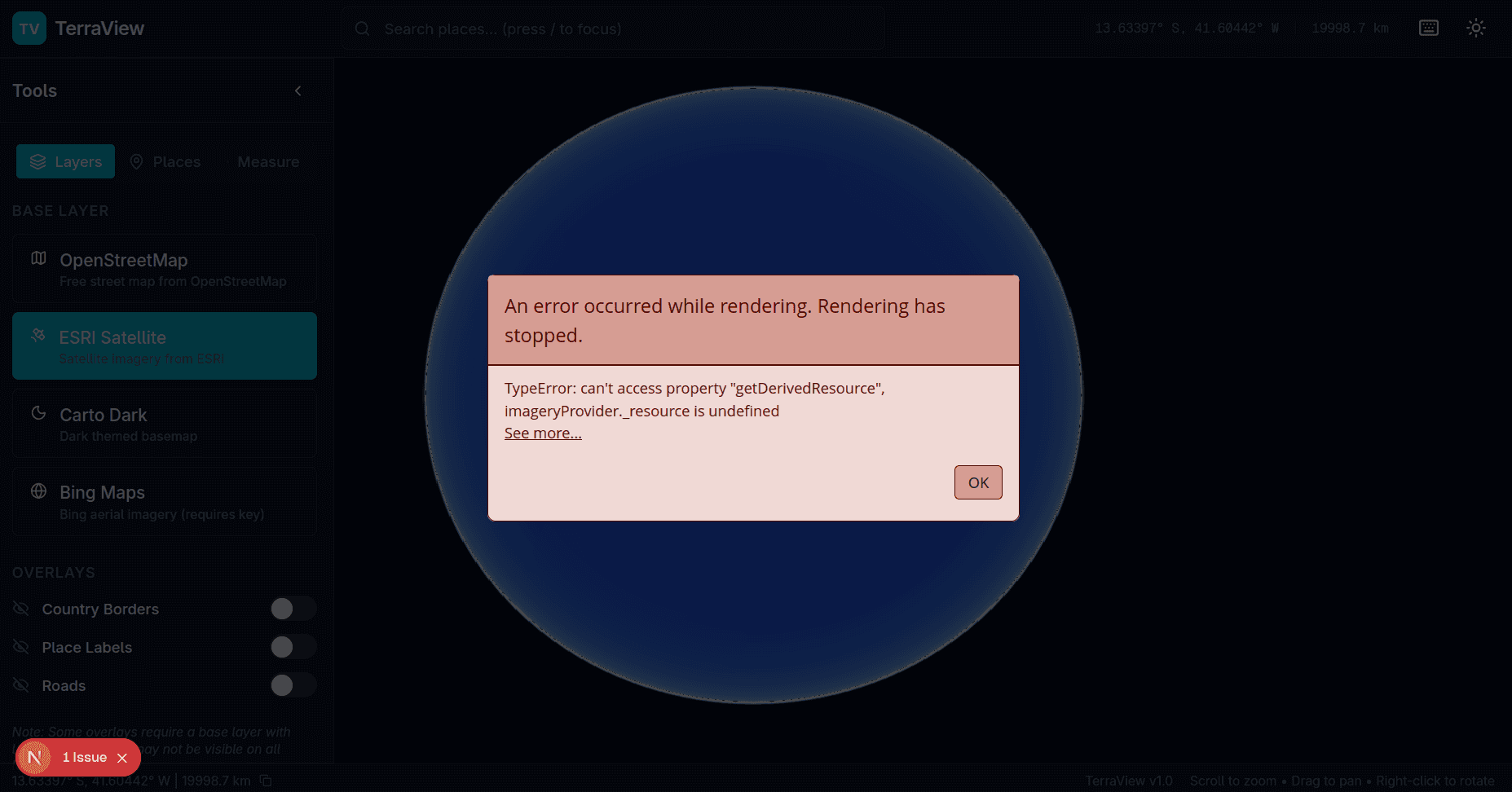
That said, the first run was not perfect. It hit a nasty rendering issue when switching certain base layers (the Cesium error popup: imageryProvider._resource is undefined), which basically stopped the globe render. I had to do a follow-up fix pass to get the base layer implementation working.
Time-wise, it took ~29 minutes to get the first draft out, then +9 min 43 sec to patch the issues. It surprisingly took a lot of time, considering this is a fast model. It takes a lot of time to reason. The fixes were not huge, but it's the same AI model problem (fixing one part breaks another working part of the code. 🤷♂️)
Here's the demo:
Token usage (from Claude Code’s model stats) looked like this:
Token Usage (before the fix): 15k output
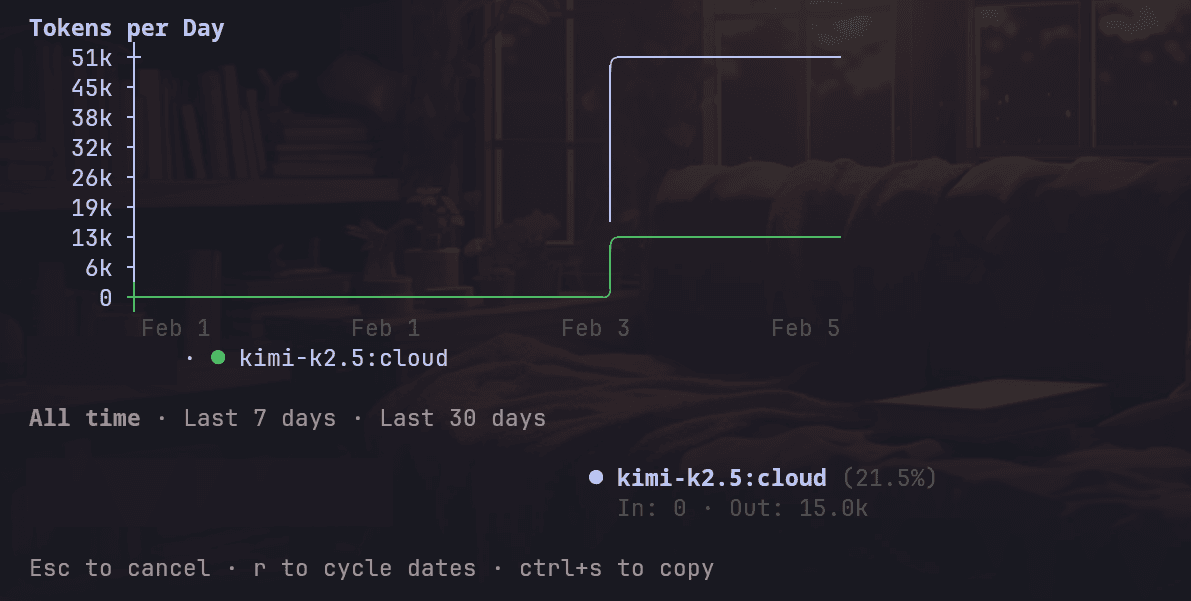
Token Usage (final): 15.9k output
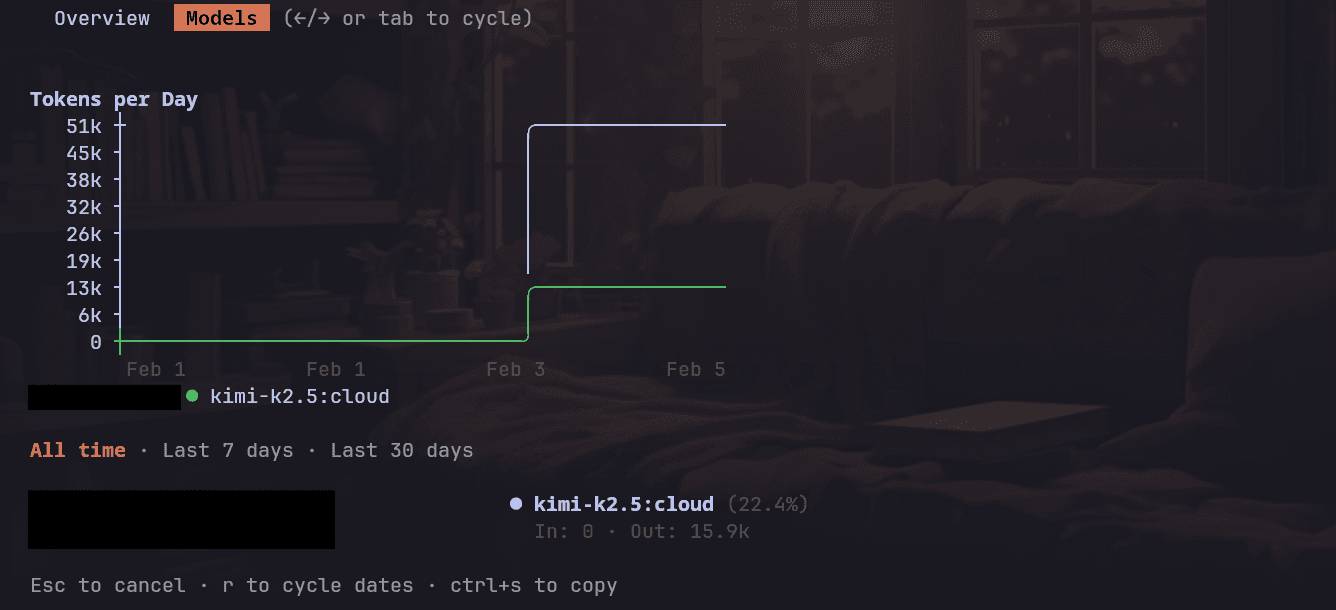
The fix pass added roughly ~900 tokens in total.
Overall, after the fixes, the final build looked pretty solid.
Duration: ~29 min (first draft) + ~9 min 43 sec (fix pass)
Code Changes: 429 files changed (including asset files), 60,387 insertions(+), 100 deletions(-)
Claude Opus 4.5
Opus 4.5 ended up looking very close to Kimi’s build, even down to the UI. It had the same overall layout, though I'm not sure how this happened.
Like Kimi, Opus did not achieve a fully working build on the first draft. It chose Resium for the globe integration, which immediately ran into a Next.js + React 18 style runtime crash.
TypeError: can't access property "recentlyCreatedOwnerStacks", W is undefined
TypeError: can't access property "recentlyCreatedOwnerStacks", W is undefined
TypeError: can't access property "recentlyCreatedOwnerStacks", W is undefined
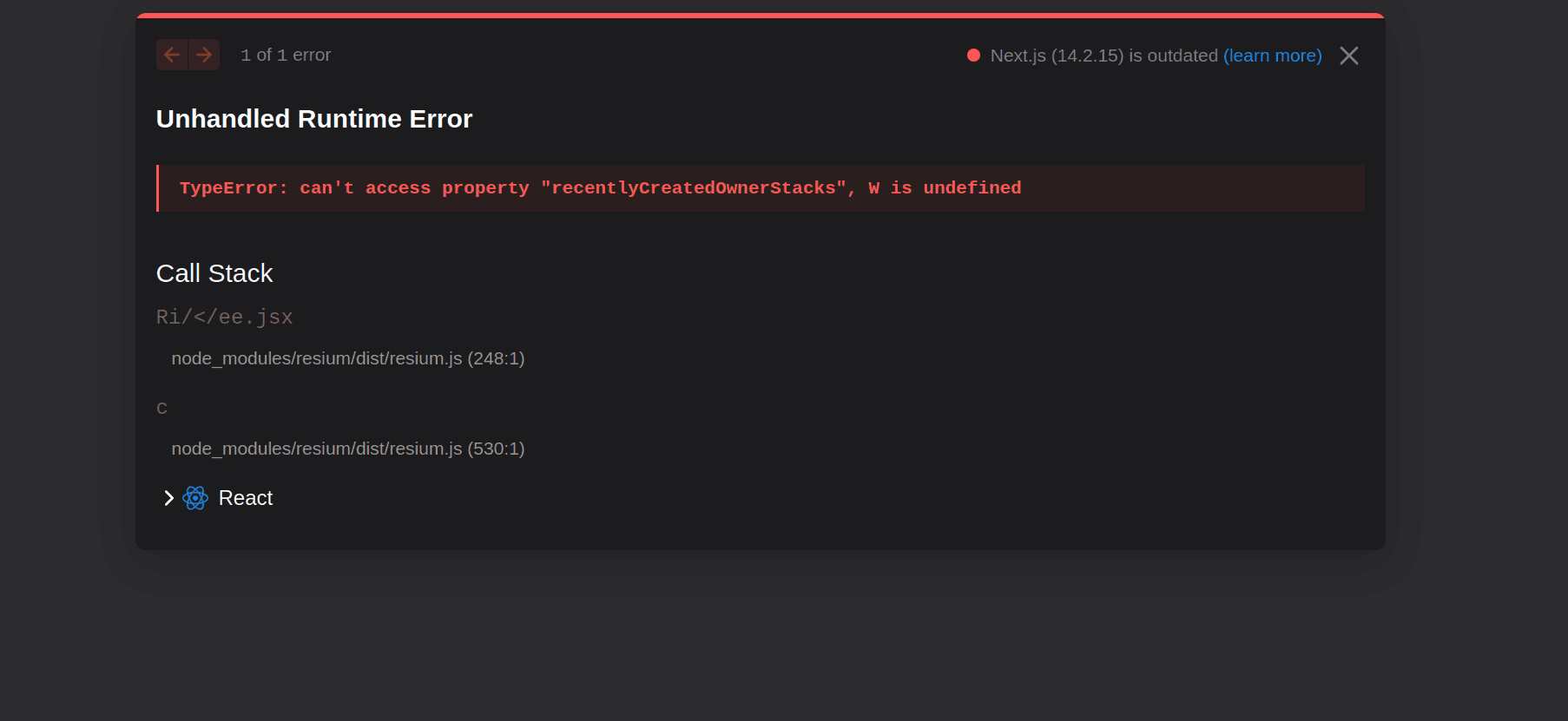
The first draft took ~23 min, and then it took about ~7 min to remove Resium and replace it with Caesium directly. That immediately fixed the issues, and everything was running as expected.

Here's the demo:
You can find the code it generated here: Claude Opus 4.6 Code
For token usage, I unfortunately ran this on Claude Max, so I could not get the exact output token breakdown from the CLI. But Claude Code showed it used 53% of the session limit, so it was definitely a big run.

Duration: ~23 min (first draft) + ~9 min 43 sec (fix pass)
Code Changes: 22 files changed, 3018 insertions(+), 45 deletions(-)
Overall, I slightly preferred Opus 4.5
here. It was a bit faster end-to-end, and the path to a working product was shorter. Kimi felt slower in comparison, which might just be Ollama Cloud latency, but either way, Opus got to the finish line with little friction. 🤷♂️
Test 2: Authentication + User Location System
Here’s what I ask: I take the TerraView codebase from the final output of Test 1, reset it to a clean commit, and then both models start from that exact same state. They get the same prompt and constraints, and implement the feature as a real production addition.
Just like Test 1, the results are evaluated from the best of 3 runs per model, so we are not judging anyone based on one unlucky response.
You can find the prompt here: Composio Auth + PostHog + User Locations Prompt
To put it together, the models are asked to add authentication to TerraView, then integrate PostHog via Composio to track signed-in and registered users and their activity. The app should capture each user’s approximate location and then render all active users on the 3D globe as distinct markers. Clicking a marker should display basic user details, such as name and email.
Kimi-K2.5
This one was a mess, honestly.
First, it tried to run a server-only package in the browser. That’s not an edge case; that’s just broken.
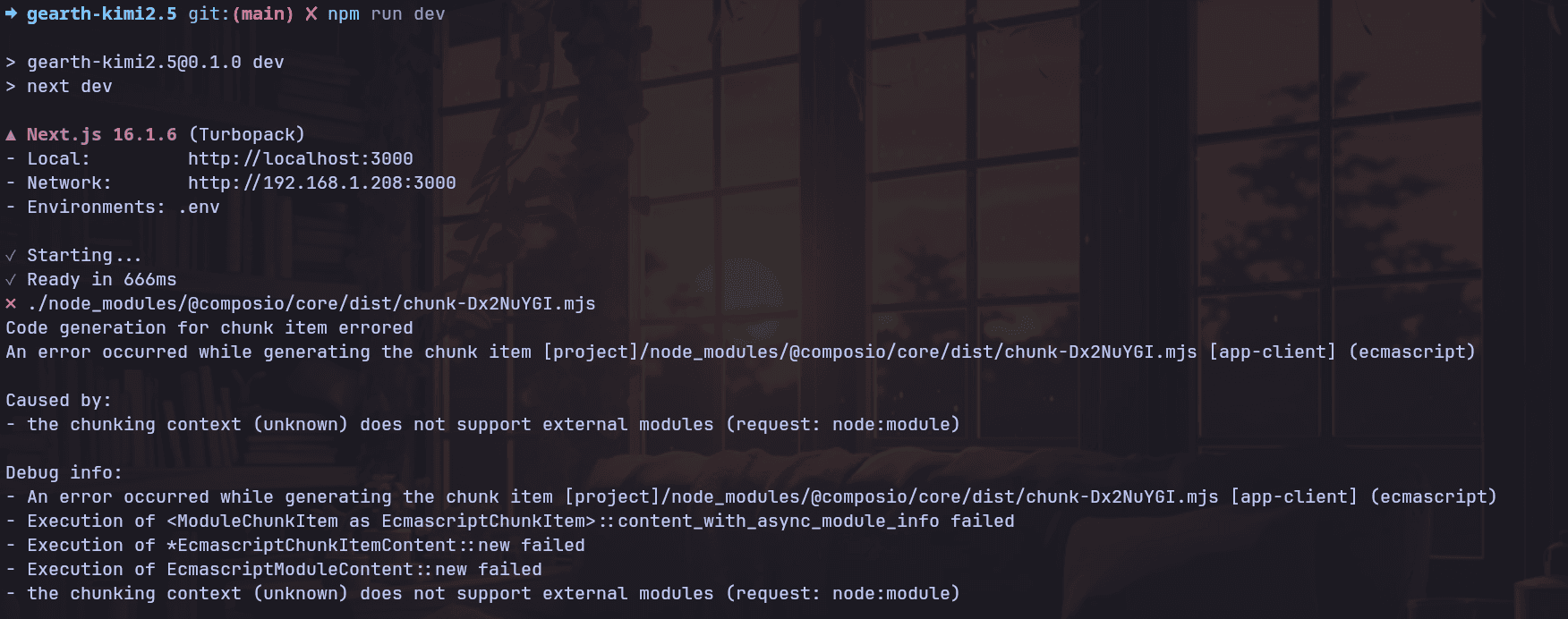
After I pushed it to fix that, authentication was the next failure. It initially went with NextAuth, but the implementation was so flawed that I had to tell it to remove it and do something simpler.
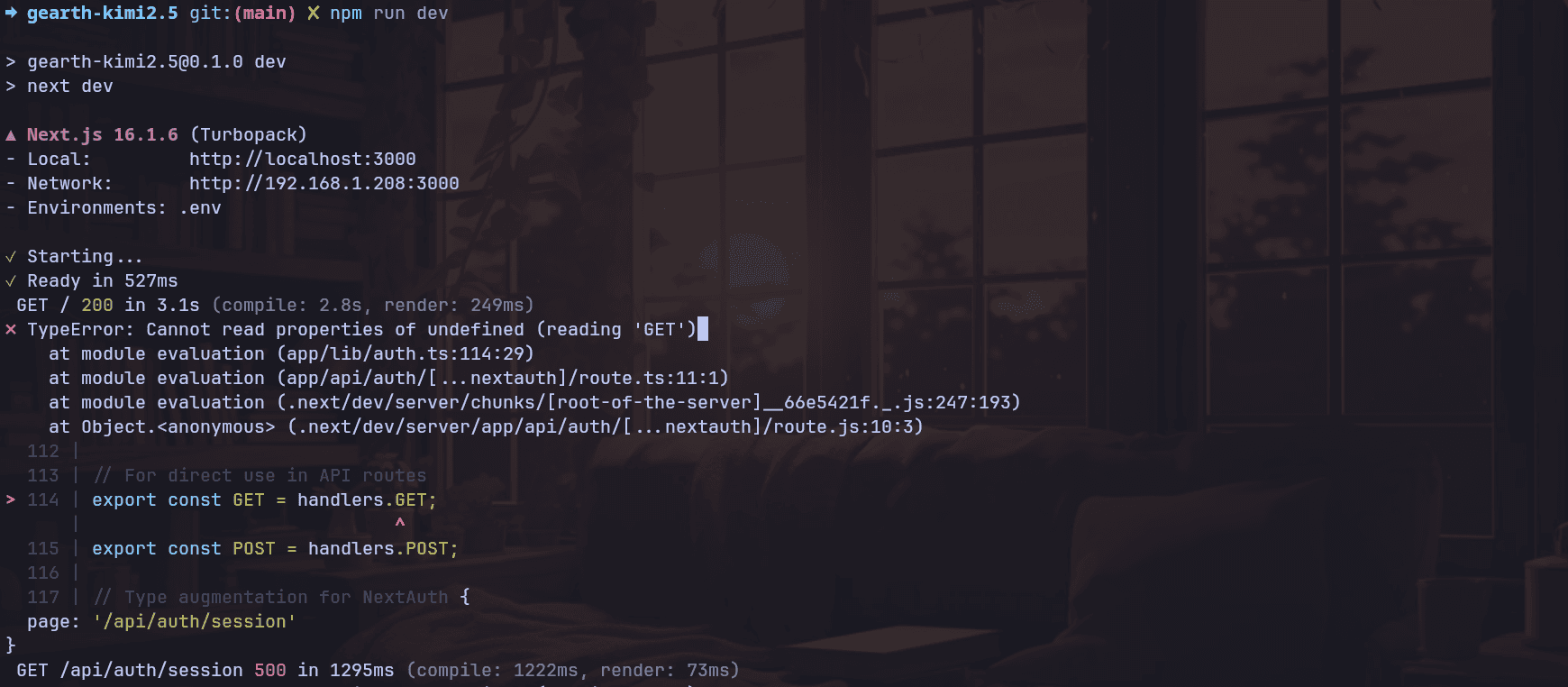
Even after that, the “fixes” kept making things worse. I could get the UI back, but then the globe disappeared entirely, which is kind of the whole app. At that point, I stopped because it wasn’t converging; it was just breaking down. The only thing the app is about. The Globe is gone.
Here's the demo:
Duration: ~18 min (first draft) + 5m 2s (fix) + ~1m 3s (another fix that still broke stuff)
Token usage: 24.3k output (first draft was ~15k, so +9.3k on top)
Code changes: 21 files changed, 1881 insertions(+), 76 deletions(-)
Claude Opus 4.5
Opus 4.5 absolutely nailed it.
I had basically zero hopes going in, honestly. This task is the kind where models usually fall apart. It has to understand the existing codebase, work around Composio, wire up auth properly, get PostHog tracking working, capture user location, render active users on the globe as markers, and keep the whole thing working end to end.
I mean, there's a lot to implement. Somehow it just… did it.
Here's the demo:
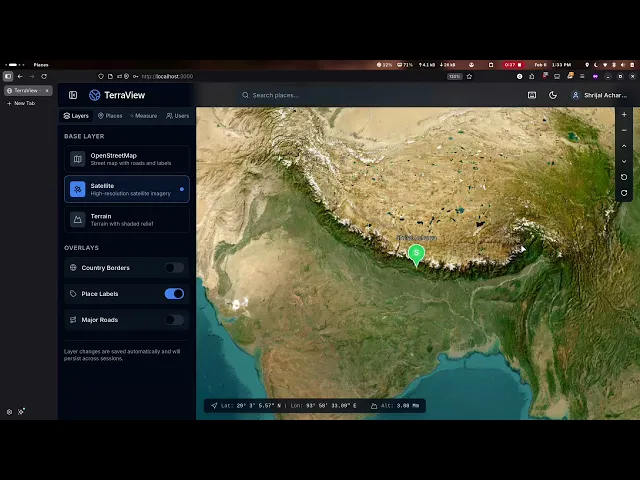
You can find the code it generated here: Claude Opus 4.5 Code
The entire authentication flow works, events are stored, the location is pulled, and active users appear on the globe as distinct markers. Clicking a marker displays basic user details, such as name and email, exactly as requested.
On code quality, I honestly can’t nitpick much. It’s decent. Recent models don’t really write “bad code” like the old ones did anymore, and this is probably cleaner than what I’d have written myself in a fast build, so I’m not going to pretend I have some perfect standard here. 🤷♂️
Time-wise, it took about 40 minutes (which I tracked manually). Most of that time is just spent on web searches.
Token usage came out to 21.6k output tokens.
If we map that to Opus 4.5 pricing at $25 per 1M output tokens, then 21.6k output tokens cost about $0.54 in output costs alone.
Duration: ~40+ minutes
Token Usage (output): 21.6k
Estimated output cost: ~$0.54
Code Changes: 6 files changed, 654 insertions(+), 426 deletions(-)
Final Thoughts
Kimi-K2.5 is genuinely a good model, especially with all its agentic capabilities and vision support. It’s roughly 8-9x cheaper than Opus 4.5, the specs are crazy, and for an open model, it’s way more capable than I expected.
But after using it in this test on a real project, I still prefer Claude Opus 4.5 for actual software work.
Kimi gets far fast (usually, not all the time), but when something breaks, the fix loop can turn into that annoying back-and-forth where one patch breaks something else out of place. Opus just feels more consistent end-to-end.
So yeah, if you care mostly about cost and want a strong open model with a huge context window, Kimi-K2.5 is an easy pick. But if you care about getting working code with the fewest issues, I’d still bet on Opus 4.5.
Kimi-K2.5 feels a lot better than open models like DeepSeek v3 speciale, GLM, Minimax, and even Sonnet 4.5, but I wouldn’t say it’s better than, or even close to, Opus 4.5.
Moonshot AI is the Chinese Anthropic, not in the sense of their ideology, but in the general direction. From their early launch of Kimi K2, it was pretty clear they were after that juicy enterprise agent automation. The models are essentially RL'd for tool calling and code generation.
And the latest launch strengthens their position as the leading open-source alternative to Claude models. It beats frontier models on certain fronts, like frontend design, and ranks 1 on the OS-world leaderboard for real-world computer environments, while being much cheaper.
It ships with a 256K context window and a pretty wild “agent swarm” idea, where the model can spin up to 100 sub-agents and coordinate up to 1,500 tool calls for wide, long tasks.
I have been using Opus for a while; it's insanely good when paired with Claude Code, and I really wanted to see how many of the tasks Kimi K2.5 can do, so I can think about cancelling my Max subscription.
While Claude Opus 4.5 comes with $5/M input token and $25/M output token, Kimi-K2.5 is a fraction of that, at $0.45/M input token and $2.50/M output token.
To summarise the difference, Kimi-K2.5 is the open-source alternative with a bigger context window and a very agent-heavy design.
I have been using Opus for a while; it's insanely good when paired with Claude Code, and I really wanted to see how good Kimi K2.5 perform, so I can cut down on Claude expenses and save more.
TL;DR
If you want a short take on the results, here's how the two models did in two standard tests:
Kimi-K2.5: Safest overall pick in my runs. It got to a working build faster, and the “fix loop” was much shorter. Test 2 (Auth + Composio + PostHog) was the main challenge, and Opus basically just shipped it. Still the most expensive and can be a bit slow as it loves to do web searches a bit too much.
Claude Opus 4.5: Insanely good for an open model, and the price is honestly wild. Test 1 was solid after a small fix pass, but it did hit a Cesium base-layer rendering issue. Test 2 worked but felt a bit more fragile, like it needs a little more babysitting to get everything clean.
💡 If you want the safer pick for real project work, I’d still go with Opus 4.5. If cost and a bigger context window matter more and you’re okay doing some extra fixing and polishing, Kimi-2.5 is a great choice.
Test Workflow
For the test, we will use the following CLI coding agents:
Claude Opus 4.6: Claude Code with API Usage
Kimi-K2.5: Claude Code using Ollama Cloud with a Pro subscription (set up to run external models)
We will check the models on two different tasks:
Task 1: Build TerraView (Google Earth-style globe viewer)
Each model is asked to build a Google Earth-inspired web app called TerraView using Next.js (App Router). The app must ship a working 3D globe viewer with smooth pan, rotate, zoom, and a small set of base layers (for example, OpenStreetMap imagery plus at least one alternate base layer).
Task 2: Authentication + Live User Location System (Composio + PostHog)
This was a fun test that lets you visualise your users on the globe. I built it to dogfood our newly updated Posthog MCP integration. Do check it out or other SaaS toolkits to build your dream workflow.
Each model must add authentication to TerraView and integrate PostHog through Composio. Once users sign in, the app should capture their approximate location and display all active users on the globe as markers.
We’ll compare code quality, token usage, cost, and time to complete the build.
💡 NOTE: I will share the source code changes for in a
.patchfile. This way, you can easily view them on your local system by creating a brand new next.js app and applying the patch file usinggit apply <path_file_name>.
Real-World Coding Comparison
Test 1: Google Earth Simulation
Here's what I ask: I will start a brand new Next.js project, and they will begin from the same commit and follow the same prompt to build what's asked.
All the results here are evaluated from the best of 3 responses from each model, so you can expect them to be very fair. We're not judging based on a model's unlucky response.
You can find the prompt I've used here: Google Earth Prompt
If you look at the prompt, it's a lot to implement, but given how capable our models are, it shouldn't really be much of a problem. 😮💨
To summarise, the models are asked to build a polished Google Earth-style Next.js app with a smooth 3D globe, search, layers, pins, saved places, measuring tools, and production-ready code that runs locally out of the box.
Kimi-K2.5
Kimi K2.5 got surprisingly far on the first draft. Most of the core features were in place without me having to babysit them too much.
That said, the first run was not perfect. It hit a nasty rendering issue when switching certain base layers (the Cesium error popup: imageryProvider._resource is undefined), which basically stopped the globe render. I had to do a follow-up fix pass to get the base layer implementation working.
Time-wise, it took ~29 minutes to get the first draft out, then +9 min 43 sec to patch the issues. It surprisingly took a lot of time, considering this is a fast model. It takes a lot of time to reason. The fixes were not huge, but it's the same AI model problem (fixing one part breaks another working part of the code. 🤷♂️)
Here's the demo:
Token usage (from Claude Code’s model stats) looked like this:
Token Usage (before the fix): 15k output
Token Usage (final): 15.9k output
The fix pass added roughly ~900 tokens in total.
Overall, after the fixes, the final build looked pretty solid.
Duration: ~29 min (first draft) + ~9 min 43 sec (fix pass)
Code Changes: 429 files changed (including asset files), 60,387 insertions(+), 100 deletions(-)
Claude Opus 4.5
Opus 4.5 ended up looking very close to Kimi’s build, even down to the UI. It had the same overall layout, though I'm not sure how this happened.
Like Kimi, Opus did not achieve a fully working build on the first draft. It chose Resium for the globe integration, which immediately ran into a Next.js + React 18 style runtime crash.
TypeError: can't access property "recentlyCreatedOwnerStacks", W is undefined
The first draft took ~23 min, and then it took about ~7 min to remove Resium and replace it with Caesium directly. That immediately fixed the issues, and everything was running as expected.
Here's the demo:
You can find the code it generated here: Claude Opus 4.6 Code
For token usage, I unfortunately ran this on Claude Max, so I could not get the exact output token breakdown from the CLI. But Claude Code showed it used 53% of the session limit, so it was definitely a big run.
Duration: ~23 min (first draft) + ~9 min 43 sec (fix pass)
Code Changes: 22 files changed, 3018 insertions(+), 45 deletions(-)
Overall, I slightly preferred Opus 4.5
here. It was a bit faster end-to-end, and the path to a working product was shorter. Kimi felt slower in comparison, which might just be Ollama Cloud latency, but either way, Opus got to the finish line with little friction. 🤷♂️
Test 2: Authentication + User Location System
Here’s what I ask: I take the TerraView codebase from the final output of Test 1, reset it to a clean commit, and then both models start from that exact same state. They get the same prompt and constraints, and implement the feature as a real production addition.
Just like Test 1, the results are evaluated from the best of 3 runs per model, so we are not judging anyone based on one unlucky response.
You can find the prompt here: Composio Auth + PostHog + User Locations Prompt
To put it together, the models are asked to add authentication to TerraView, then integrate PostHog via Composio to track signed-in and registered users and their activity. The app should capture each user’s approximate location and then render all active users on the 3D globe as distinct markers. Clicking a marker should display basic user details, such as name and email.
Kimi-K2.5
This one was a mess, honestly.
First, it tried to run a server-only package in the browser. That’s not an edge case; that’s just broken.
After I pushed it to fix that, authentication was the next failure. It initially went with NextAuth, but the implementation was so flawed that I had to tell it to remove it and do something simpler.
Even after that, the “fixes” kept making things worse. I could get the UI back, but then the globe disappeared entirely, which is kind of the whole app. At that point, I stopped because it wasn’t converging; it was just breaking down. The only thing the app is about. The Globe is gone.
Here's the demo:
Duration: ~18 min (first draft) + 5m 2s (fix) + ~1m 3s (another fix that still broke stuff)
Token usage: 24.3k output (first draft was ~15k, so +9.3k on top)
Code changes: 21 files changed, 1881 insertions(+), 76 deletions(-)
Claude Opus 4.5
Opus 4.5 absolutely nailed it.
I had basically zero hopes going in, honestly. This task is the kind where models usually fall apart. It has to understand the existing codebase, work around Composio, wire up auth properly, get PostHog tracking working, capture user location, render active users on the globe as markers, and keep the whole thing working end to end.
I mean, there's a lot to implement. Somehow it just… did it.
Here's the demo:
You can find the code it generated here: Claude Opus 4.5 Code
The entire authentication flow works, events are stored, the location is pulled, and active users appear on the globe as distinct markers. Clicking a marker displays basic user details, such as name and email, exactly as requested.
On code quality, I honestly can’t nitpick much. It’s decent. Recent models don’t really write “bad code” like the old ones did anymore, and this is probably cleaner than what I’d have written myself in a fast build, so I’m not going to pretend I have some perfect standard here. 🤷♂️
Time-wise, it took about 40 minutes (which I tracked manually). Most of that time is just spent on web searches.
Token usage came out to 21.6k output tokens.
If we map that to Opus 4.5 pricing at $25 per 1M output tokens, then 21.6k output tokens cost about $0.54 in output costs alone.
Duration: ~40+ minutes
Token Usage (output): 21.6k
Estimated output cost: ~$0.54
Code Changes: 6 files changed, 654 insertions(+), 426 deletions(-)
Final Thoughts
Kimi-K2.5 is genuinely a good model, especially with all its agentic capabilities and vision support. It’s roughly 8-9x cheaper than Opus 4.5, the specs are crazy, and for an open model, it’s way more capable than I expected.
But after using it in this test on a real project, I still prefer Claude Opus 4.5 for actual software work.
Kimi gets far fast (usually, not all the time), but when something breaks, the fix loop can turn into that annoying back-and-forth where one patch breaks something else out of place. Opus just feels more consistent end-to-end.
So yeah, if you care mostly about cost and want a strong open model with a huge context window, Kimi-K2.5 is an easy pick. But if you care about getting working code with the fewest issues, I’d still bet on Opus 4.5.
Kimi-K2.5 feels a lot better than open models like DeepSeek v3 speciale, GLM, Minimax, and even Sonnet 4.5, but I wouldn’t say it’s better than, or even close to, Opus 4.5.
Recommended Blogs
Recommended Blogs


Connect AI agents to SaaS apps in Minutes
Connect AI agents to SaaS apps in Minutes
We handle auth, tools, triggers, and logs, so you build what matters.

Stay updated.

Stay updated.