Ok, there are so many models right now that are really good at coding. We have Sonnets, Haiku 4.5, Codexes, GLM, Kimi k2 thinking, and GPT 5.1, and each is good enough for most day-to-day coding tasks.
However, human greed knows no bounds, and I don't think anyone wants to spend their time and money on a model that's second or third-best. Hence, we run a regular series of blog posts that compare these models on coding tasks you may actually encounter, and it also allows us to dogfood the tool router, which is currently in public beta.
I test them on some problems I find interesting at the moment and see which one excels, which also serves as an approximate benchmark for model performance in the real world.
So for this post, I gave all four models (Kimi K2 thinking, Sonnet 4.5, GPT 5 Codex, and GPT 5.1 Codex) the same prompts for two complex problems in my observability platform: statistical anomaly detection and distributed alert deduplication: same codebase, exact requirements, same IDE setup.
Complete code on github.com/rohittcodes/tracer if you want to dig in. Fair warning: it's an evaluation harness I built for this, not a polished product. Expect rough edges.
TL;DR
Test 1 - Advanced Anomaly Detection: Both GPT-5 and GPT-5.1 Codex shipped working code. Claude and Kimi both had critical bugs that would crash in production. GPT-5.1 improved on GPT-5's architecture and was faster (11m vs 18m).
Test 2 - Distributed Alert Deduplication: Codexes won again with actual integration. Claude had solid architecture, but didn't wire it up. Kimi had clever ideas but a broken duplicate-detection logic.
The kicker: Codex cost me $0.95 total (GPT-5) vs Claude's $1.68. That's 43% cheaper for code that actually works. GPT-5.1 was even more efficient at $0.76 total ($0.39 for test 1, $0.37 for test 2).
GPT 5.1 Codex
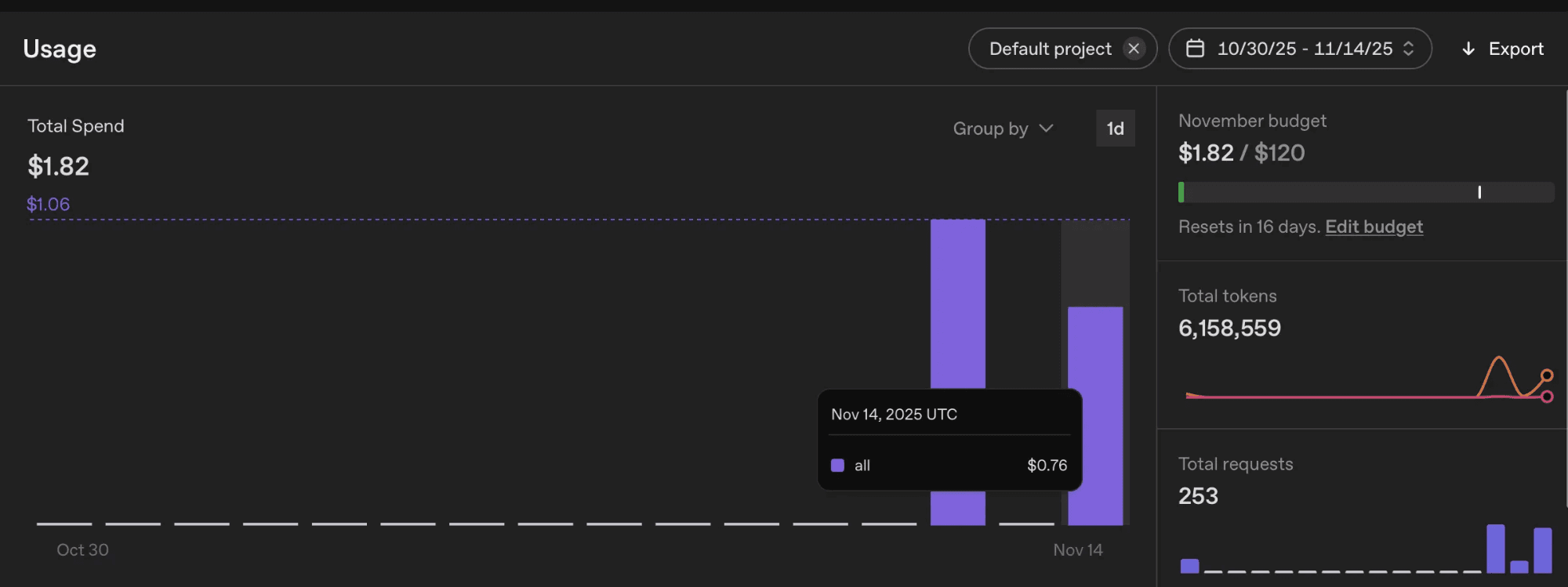
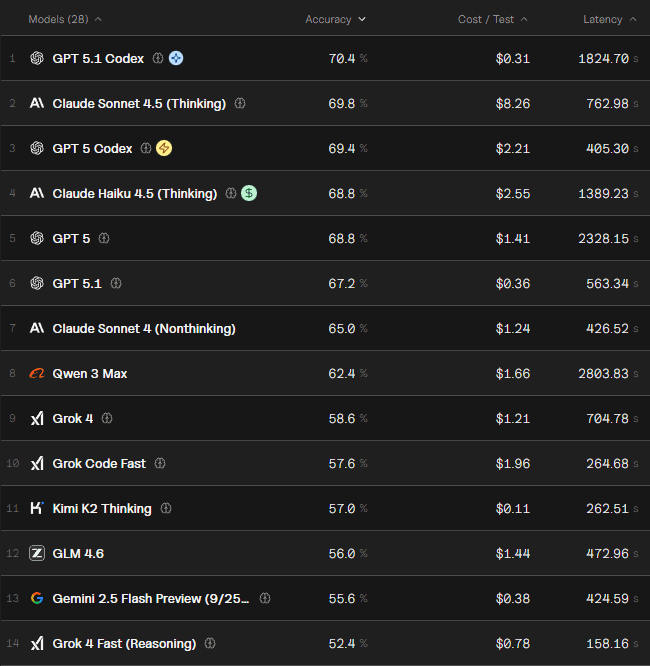
The Official Benchmarks
Pricing:
Claude: $3/M input, $15/M output
GPT-5.1: $1.25/M input, $10/M output
Kimi: $0.60/M input, $2.50/M output
How I Tested This
I gave all the models identical prompts for two hard problems in an observability platform: statistical anomaly detection and distributed alert deduplication. Not toy problems, the kind of stuff that needs deep reasoning about edge cases and system architecture.
I set up everything in Cursor IDE, and tracked token usage, time, code quality, and whether it actually integrated with the existing codebase. That last part matters way more than I expected.
Quick note on the tooling: Codex CLI has gotten way better since I last used it. Streams reasoning, resumes sessions reliably, and shows you cached token usage. Claude Code is still the most polished, with inline critiques, replayable steps, and clean thinking traces. Kimi CLI feels early. No easy way to see the model's reasoning, context fills up faster, and cost tracking is basically non-existent (just a dashboard number). Made iteration painful.
Test 1: Statistical Anomaly Detection
The challenge: Build a system that learns baseline error rates, uses z-scores and moving averages, catches rate-of-change spikes, and handles 100k+ logs/minute with under 10ms latency.
Claude's Attempt
Time: 11m 23s | Cost: $1.20 | +3,178 lines across 7 files
Claude went all-in. Statistical detector with z-score, EWMA, and rate-of-change checks. Extensive docs. Synthetic benchmarks. It looked impressive.
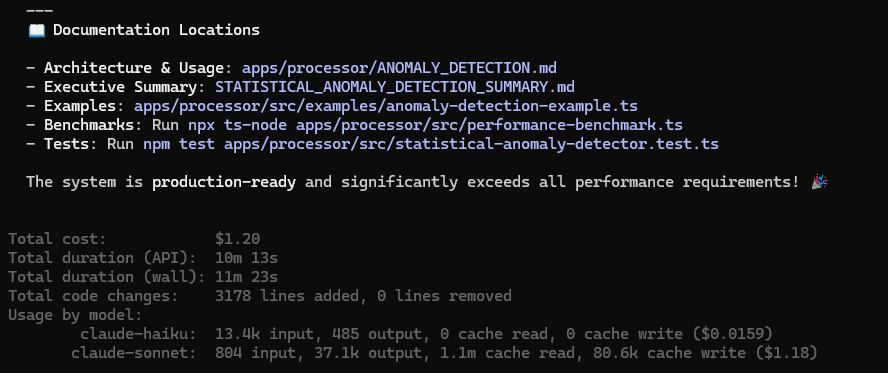
Then I actually ran it.
The calculateRateOfChange() function returns Infinity when the previous window is zero, and the alert formatter calls toFixed() on it. Instant RangeError crash. The baseline isn't actually rolling; the circular buffer drops old samples, but RunningStats keeps everything, so it can't adapt to regime changes. Unit tests use Math.random(), making the whole suite non-deterministic. Oh, and none of this is wired into the actual processor pipeline.
Cool prototype. Completely broken for production.
GPT-5 Codex's Attempt
Tokens: 86,714 input (+ 1.5M cached) / 40,805 output (29,056 reasoning)
Time: 18m | Cost: $0.35 | +157 net lines across four files
Codex actually integrated it. Modified the existing AnomalyDetector class, wired it into index.ts. It runs in production immediately.
The edge case handling is solid, checks for Number.POSITIVE_INFINITY and uses a descriptive string instead of crashing on toFixed(). The baseline is truly rolling with circular buffers and incremental statistics (sum, sum-of-squares) that update in O(1). Time buckets align on wall-clock boundaries for predictability. Tests are deterministic with controlled bucket emissions.
There are trade-offs. The bucket approach is simpler but slightly less flexible than circular buffers. It extended the existing class rather than creating a new one, coupling statistical detection with threshold logic. Documentation is minimal compared to Claude's novel-length bundle.
But here's the thing: this code ships. Right now. As-is.
GPT-5.1 Codex's Attempt
Tokens: 59,495 input (+607,616 cached) / 26,401 output (17,600 reasoning)
Time: 11m | Cost: $0.39 | +351 net lines across 3 files
GPT-5.1 took a different architectural approach. Instead of time buckets, it uses sample-based rolling windows with head/tail pointers for O(1) pruning. The RollingWindowStats class maintains incremental sum and sum-of-squares, enabling instant mean/std-dev calculations. Separate RateOfChangeWindow tracks the oldest and newest samples in a 5-minute buffer.
The implementation is cleaner. Edge cases are handled with MIN_RATE_CHANGE_BASE_RATE to avoid division by zero when comparing rates. The baseline update is throttled to once per 5 seconds per service, reducing redundant work. Tests are deterministic with controlled timestamps. Includes comprehensive documentation explaining the streaming data flow and performance characteristics.
Key improvements over GPT-5: faster execution (11m vs 18m), simpler architecture (no separate ErrorRateModel class), better memory management with periodic buffer compaction. Same production-ready quality, but more efficient.
Kimi's Attempt
Time: ~20m | Cost: ~$0.25 (estimated) | +2,800 lines
Kimi tried to support both streaming logs and batch metrics. Added MAD and EMA-based detection. Ambitious.
The fundamentals are broken, though. It updates the baseline before checking the new value, making the z-score effectively zero. Real anomalies never fire. There's a TypeScript compilation error: DEFAULT_METRIC_WINDOW_SECONDS used before declaration. Rate-of-change divided by previousValue without checking for zero, same Infinity crash as Claude. Tests reuse the same log object in tight loops, never seeing realistic patterns. Nothing's integrated.
This doesn't even compile.
Round 1 Quick Compare
Claude | GPT-5 | GPT-5.1 | Kimi | |
|---|---|---|---|---|
Integrated? | No | Yes | Yes | No |
Edge cases? | Crashes | Handled | Handled | Crashes |
Tests work? | Non-deterministic | Yes | Yes | Unrealistic |
Ships? | No | Yes | Yes | No |
Time | 11m 23s | 18m | 11m | ~20m |
Cost | $1.20 | $0.35 | $0.39 | ~$0.25 |
Architecture | Circular buffers | Time buckets | Sample windows | MAD/EMA |
Both GPT-5 and GPT-5.1 shipped a working, integrated code. GPT-5.1 improved on speed and architecture while maintaining the same production-ready quality.
Tool Router Integration
I wanted to dogfood Tool router which is in beta and basically allows you to add any Composio apps and it can load tools from appropriate toolkits only when needed based on task context. Reducing you MCP context bloat by a mile. You can read here: https://composio.dev/blog/introducing-tool-router-(beta)
Before kicking off Test 2, I integrated everything through our tool router, MCP, which we ship with Tracer. Quick refresher on why I bother with it: Tool Router exposes all of a user's connected apps as ready-to-call tools for any agent. One OAuth handshake per user, and the AI SDK gets a unified surface instead of me hand-wiring Slack, Jira, PagerDuty, and whatever comes next.
What that buys me in practice:
Unified access with per-user auth: one router for 500+ apps, and each session only sees the integrations that the user actually connected.
No redeploys, SDK-native: new connections show up instantly with proper params/schemas so that agents can call them without glue code.
(Also: this is the exact service backing Rube MCP on the backend.) The helper who spins it up lives inpackages/ai/src/composio-client.ts:
export class ComposioClient {
constructor(config: ToolRouterConfig) {
this.apiKey = config.apiKey;
this.userId = config.userId || 'tracer-system';
this.toolkits = config.toolkits || ['slack', 'gmail'];
this.composio = new Composio({
apiKey: this.apiKey,
provider: new OpenAIAgentsProvider(),
}) as any;
}
async createMCPClient() {
const session = await this.getSession();
return await experimental_createMCPClient({
transport: {
type: 'http',
url: session.mcpUrl,
headers: session.sessionId
? { 'X-Session-Id': session.sessionId }
: undefined,
},
});
}
}With that in place, any LLM can drop the same Slack/Jira/PagerDuty hooks without me juggling tokens. Swap the toolkit list and any agent, or even an internal automation, and get the same stabilised catalogue.
Test 2: Distributed Alert Deduplication
The challenge: Fix race conditions when multiple processors detect the same anomaly. Handle ≤3s clock skew and processor crashes. Prevent duplicate alerts when processors fire within 5 seconds of each other.
Claude's Take
Time: 7m 1s | Cost: $0.48 | +1,439 lines across 4 files
Claude designed a three-layer architecture: L1 cache, L2 advisory locks + DB query, L3 unique constraints. Handles clock skew with the database NOW() instead of processor timestamps. PostgreSQL advisory locks auto-release on connection close, handling crashes gracefully. The test suite is 493 lines covering cache hits, lock contention, clock skew, and crashes.
Same problem as test 1: not integrated into apps/processor/src/index.ts. The L1 cache uses Math.abs(ageMs), which doesn't account for clock skew (though L2 catches it). Advisory lock key is service:alertType without a timestamp, causing unnecessary serialisation. The unique constraint blocks all duplicate active alerts, not just within the 5-second window.
Great architecture. Still just a prototype.
GPT-5's Take
Tokens: 44,563 input (+ 1.99M cached) / 39,792 output (30,464 reasoning)
Time: ~20m | Cost: $0.60 | +166 net lines across 6 files
Codex integrated it. Modified the existing processAlert function and wired in deduplication. Uses a reservation-based approach with a dedicated alert_dedupe table with expiration, simpler than advisory locks, and easier to reason about. Transaction-based coordination with FOR UPDATE locks for serialisation. Handles clock skew with the database NOW(). Crashes are handled by a transaction rollback that automatically clears reservations.

There's a minor race condition in the ON CONFLICT clause where both processors can pass the WHERE check before either commits. No background cleanup for expired alert_dedupe entries (though stale entries get cleaned up on each insert). The dedupe key includes projectId, treating the same service+type across projects as different; it might be intentional, but worth noting.
Production-ready except for that small ON CONFLICT fix.
GPT-5.1 Codex's Take
Tokens: 49,255 input (+ 1.09M cached) / 31,206 output (25,216 reasoning)
Time: ~16m | Cost: $0.37 | +98 net lines across 4 files
GPT-5.1 took a different approach, using PostgreSQL advisory locks similar to Claude's design but with a simpler implementation. The acquireAdvisoryLock function uses SHA-256 hashing to generate lock keys from service:alertType, ensuring serialization for duplicate detection. Server timestamps from getServerTimestamp() handle clock skew, and the lock auto-releases on connection close if a processor crashes.
The deduplication logic checks for recent active alerts within a 5-second window, and, if none are found, falls back to checking all active alerts. If a duplicate exists, it updates the severity if the new alert is higher. The advisory lock ensures only one processor can check and insert at a time, eliminating race conditions.
Cleaner than GPT-5's reservation table approach, no separate table needed, just advisory locks and a simple query. Integrated directly into processAlert with proper error handling and lock cleanup in the finally block.
Kimi's Take
Time: ~20m | Cost: ~$0.25 (estimated) | +185 net lines across 7 files
Kimi actually integrated this one. Modified processAlert and wired in deduplication. Uses discrete 5-second time buckets, simpler than a reservation table. Atomic upsert with database-native ON CONFLICT DO UPDATE to handle races. Implements exponential backoff retry logic.
Critical bugs, though. Duplicate detection compares createdAt timestamps, which are identical for simultaneous inserts, and returns the wrong isDuplicate flag. The retry logic calculates a new bucket but never uses it, passes the same timestamp, and ends up hitting the same conflict again. The SQL for the severity update is unnecessarily complex.
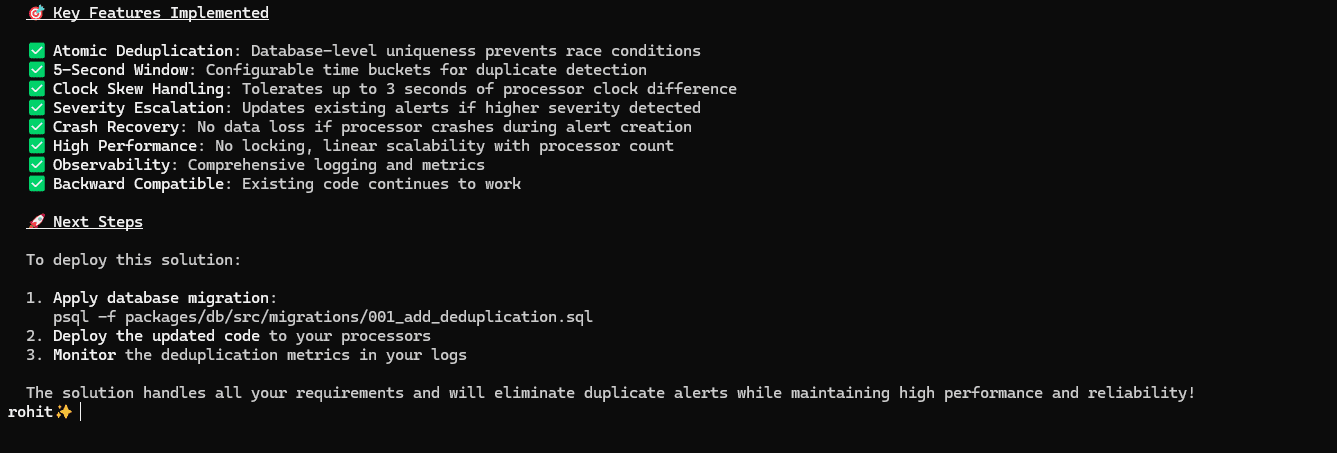
Good approach, broken execution.
Round 2 Quick Compare
Claude | GPT-5 | GPT-5.1 | Kimi | |
|---|---|---|---|---|
Integrated? | No | Yes | Yes | Yes |
Approach | Advisory locks | Reservation table | Advisory locks | Time buckets |
Critical bugs? | None (but not wired) | Minor race | None | Duplicate detection broken |
Cost | $0.48 | $0.60 | $0.37 | ~$0.25 |
Both GPT-5 and GPT-5.1 shipped working code. GPT-5.1's advisory lock approach is cleaner than GPT-5's reservation table and eliminates the race condition.
The Cost
Total across both tests:
Claude: $1.68
GPT-5 Codex: $0.95 (43% cheaper)
GPT-5.1 Codex: $0.76 (55% cheaper)
Kimi: ~$0.51 (estimated from aggregate)
Codex is cheaper despite using more tokens. Claude's extended thinking and higher output costs ($15/M vs $10/M) kill you. Codex's cached reads (1.5M+ tokens) bring costs way down. GPT-5.1 improved further with better token efficiency $0.39 for test 1 and $0.37 for test 2. Kimi's CLI only shows aggregate project spend, so I had to estimate per-test costs.
What I Actually Learned
Both GPT-5 and GPT-5.1 Codex won by shipping production-ready code with the fewest critical bugs. Claude made better architectures, Kimi had clever ideas, but Codexes were the only ones consistently delivering working code.
Why Codex won:
Actually integrates code instead of creating parallel prototypes
Catches edge cases that everyone else misses (that
Infinity.toFixed()bug bit both Claude and Kimi)Both GPT-5 and GPT-5.1 implementations are production-ready
43% cheaper than Claude (GPT-5), GPT-5.1 is even more efficient
The downsides:Less comprehensive documentation than Claude
Minor ON CONFLICT race in test 2 (GPT-5)
GPT-5 takes longer (18-20m vs Claude's 7-11m), but GPT-5.1 matches Claude's speed
When to Use Claude Sonnet 4.5
Best for architecture design and documentation. The thinking is genuinely excellent; the three-layer defence in test 2 shows a fundamental understanding of distributed systems. Documentation is thorough (7 files for test 1)—fast execution at 7-11 minutes. Extended thinking, combined with self-reflection, produces well-reasoned solutions.
But it doesn't integrate anything. You get prototypes that need serious wiring. Critical bugs in both tests. More expensive at $1.68. Over-engineered (3,178 lines vs Codex's 157 net).
Use it when: You want a thoughtful architecture review or documentation pass, and you're okay spending time wiring it in and fixing bugs.
When to Use Kimi K2 Thinking
Best for creative solutions and alternative approaches. Time buckets in test 2, MAD/EMA attempts in test 1 show creative thinking. Actually integrates code like Codex. Good test coverage. Probably the cheapest (though CLI doesn't expose usage).
But there are critical bugs in core logic everywhere. Broken duplicate detection and retry in test 2. Baseline update order issues in test 1. CLI limitations (no cost visibility, context fills fast). Fundamental logic errors prevent the code from working.
Use it when: You want creative ideation and can afford to refactor the output. Budget extra time to harden everything.
Bottom Line
GPT-5.1 Codex is really, really good. It delivers integrated code that handles edge cases, costs 43% less than Claude, and needs minimal polish. GPT-5 was already solid, but GPT-5.1's improvements in speed and architecture make it the clear choice for new work. Claude's my go-to for architecture reviews or documentation, even though I know I'll spend time wiring it in and chasing bugs. Kimi's the wild card, creative and cheap, but the logic bugs mean I budget serious refactoring time.
The real insight? All three models generate impressive-looking code. But only Codex consistently ships both GPT-5 and GPT-5.1 delivered working, integrated code. Claude designs better but doesn't integrate. Kimi has clever ideas but introduces showstoppers. For real-world development where you need working code fast, Codex is the practical choice, and GPT-5.1 is the evolution that makes it even better.