It's 4:00 PM on Friday. Your AI sales agent just told your largest customer they'll receive a 50% discount. Nobody authorized it.
The demo worked perfectly last week. You connected it to Confluence, gave it Salesforce API access, and it answered questions correctly. But now it's in production, and it's making things up. Your VP wants answers about why you're rolling back the pilot. You're stuck explaining that the LLM works fine, but the data it receives is garbage — a common result of the deep integration gap between AI agents and sales tools.
Sound familiar? You're not alone. 2025 was the "Year of the Agent" according to every conference keynote. We'd have autonomous systems writing code, managing sales pipelines, and handling support tickets. Instead, we got the "Stalled Pilot" syndrome.
You've seen that MIT study claiming 95% of AI pilots fail. The methodology is questionable (they mix "learning pilots" with "production failures" without clear definitions), but the core problem is real. The gap between a working demo and a reliable production system is where projects die.
Andrej Karpathy nailed it when he described this as a new programming paradigm. We have a powerful new kernel (the LLM) but no Operating System to run it properly.
We've been obsessing over the brain while ignoring the nervous system. Yes, model choice matters. Poor reasoning or slow tool-use will tank your project. But even GPT-5 is useless when it gets bad data or can't execute actions reliably.
Inference costs and weak evaluation frameworks kill plenty of projects. But the biggest, most overlooked bottleneck? Integration. It's not sexy, but it's what separates demos from production.
Key Takeaways
Stalled Pilots: Most AI agent pilots fail because they lack an "Operating System" to manage memory, I/O, and permissions. The LLM kernel isn't the problem.
The 3 Traps: Projects die from "Dumb RAG" (dumping everything into context), "Brittle Connectors" (broken API integrations), and the "Polling Tax" (no event-driven architecture).
The Solution: Build an "Agent-Native" Integration Layer that acts as the LLM's OS. It manages context, governs actions, and provides observability.
The 2026 Roadmap: Move from a centralized "Agent Team" (Pattern A) to a "Self-Serve Platform" (Pattern B) that lets the entire organization build safely.
Beyond the Demo: The True Business Cost of Stalled AI Pilots
That failed demo isn't just embarrassing; it's humiliating. It has real, measurable costs that you need to communicate to leadership.
Wasted Engineering Capital: Five senior engineers spending three months on custom connectors for a shelved pilot equals $500k+ in salary burn. That's half a million on plumbing instead of product.
Lost Competitive Edge: While you debug OAuth tokens for a read-only wiki bot, competitors are shipping agents that write to CRMs, accelerate quote-to-cash, and flag churn risks proactively.
Erosion of Internal Trust: This one hurts the most. When high-visibility AI projects fail, leadership loses faith in AI investment. VPs dismiss it as hype. Your best engineers get frustrated and leave.
Why Did So Many AI Agent Pilots Fail in 2025
I've spent 20 years building platforms and API products. What we're seeing now isn't new. It's the same integration problems with fresh acronyms.
Every stalled pilot made the same mistakes. They treated agents as drop-in replacements rather than as new architectural components. They fell into three specific traps.
Trap 1: The "Dumb RAG" Problem – Why Vector Databases Aren't Enough
What it is: Dumping all your Confluence docs, Slack history, and Salesforce data into a vector database, hoping the LLM figures it out.
Why it failed: Karpathy calls the context window the LLM's "RAM." This approach dumps your entire hard drive into RAM and expects the CPU to find one specific byte. You get thrashing and context-flooding, not reasoning.
The Hidden Complexity: The LLM drowns in irrelevant, unstructured, conflicting information. This leads to high-confidence hallucinations. Research now shows that sometimes less context produces better results.
The Fix: You need context precision, not volume. Karpathy calls the context window the "RAM." Do not dump your hard drive into RAM.
Trap 2: The "Brittle Connector" (Ignoring Legacy API Chaos)
What it is: Pointing the agent at existing REST/SOAP APIs and expecting it to call endpoints correctly.
Why it failed: This is broken I/O. Earlier in my career, I worked with APIs we fully controlled. In the enterprise, you don't control Salesforce's API. You definitely don't control your customer's 5,000 custom fields and undocumented workflows.
The Hidden Complexity: You're giving a naive agent access to undocumented rate limits, brittle middleware, 200-field dropdowns, and duplicate logic. It's like giving a new hire server room keys without documentation. Something will break.
The Fix: Use managed tooling interfaces that handle the schema normalization for you.
Trap 3: The "Polling Tax" (Lacking Event-Driven Architecture)
What it is: Having the agent check for updates constantly ("Is the order ready? How about now? Now?").
Why it failed: This is an architectural failure. At Facebook, we learned this lesson with billions of events. Polling doesn't scale. It wastes 95% of your API calls, burns through quotas, and never achieves real-time responsiveness.
The Hidden Complexity: You can't build event-driven agents on request-response infrastructure. Your OS needs interrupts and signals, not infinite loops.
The Fix: You cannot build autonomous agents on request-response infrastructure. You need webhooks or event-driven systems.
What is the Solution: An "Agent-Native" Integration Layer
The teams succeeding aren't just running the kernel. They're building the Operating System around it.
This "Agent-Native" Integration Layer is that OS. It makes your un-ready enterprise agent-ready through four core principles.
Principle 1: Context Precision (Memory Management)
You don't give new hires the entire company archive (Dumb RAG). You give them a five-page briefing necessary for their function and role.
This layer does the same for agents. It acts as the memory manager, translating requests into precise queries, fetching only the specific customer record, and loading clean, minimal context into the LLM's RAM.
Principle 2: Bi-Directional & Event-Driven (I/O & Syscalls)
An agent that only reads data is a fancy search box. Production agents need write access to update CRMs, create tickets, and provision users.
More importantly, they need event-driven architecture. React to "Deal Closed" webhooks instead of polling for changes.
Principle 3: Policy and Governance (Permissions & "Sudo Prompts")
"Please don't delete customer records" isn't a security policy. It's a wish. Establishing a clear framework for agent permissions and security is critical, as we detail in our complete AI agent governance guide.
Production governance requires OS-level permissions. The most effective pattern is Human-in-the-Loop (HITL), which works like sudo prompts. The system pauses high-privilege operations for human confirmation.
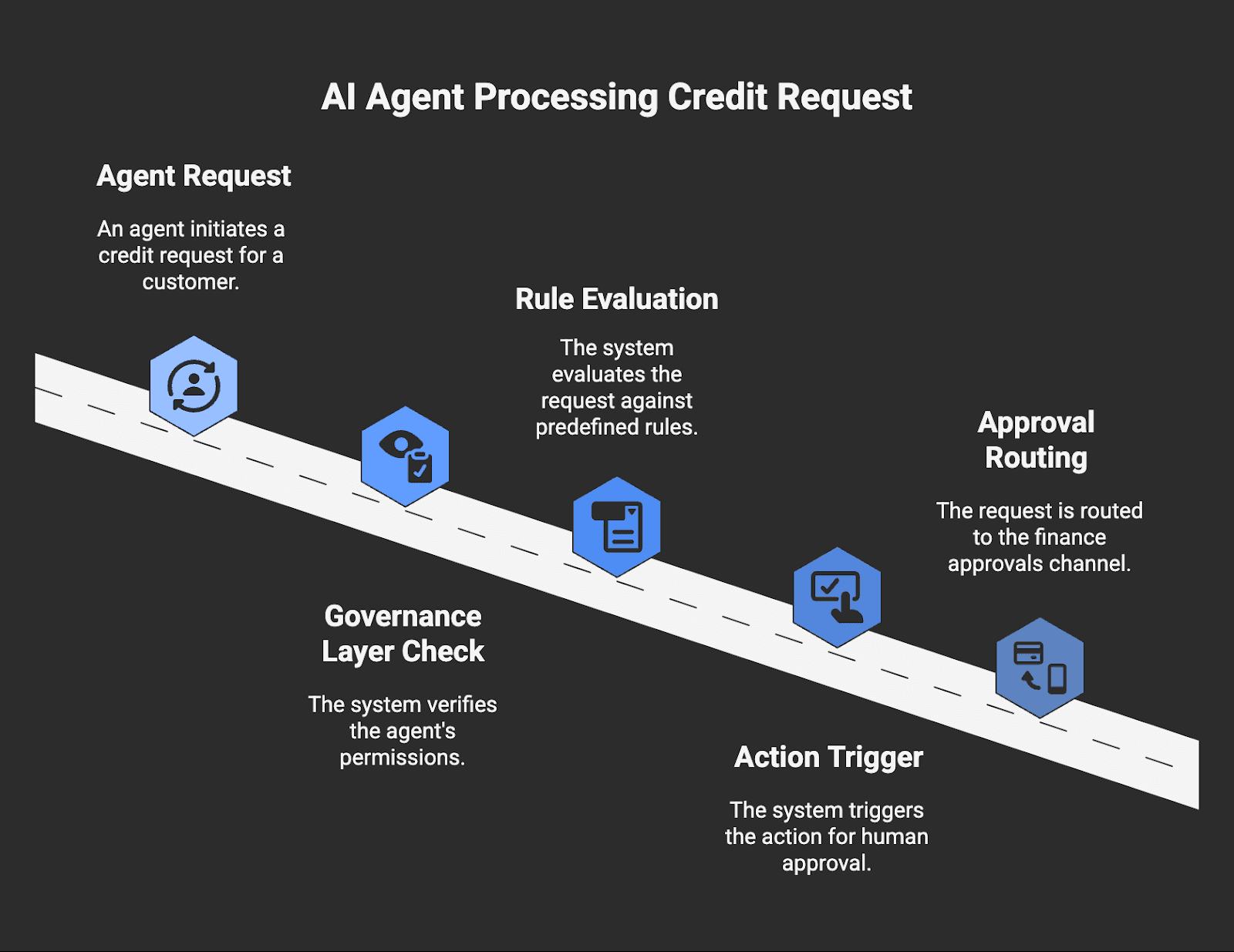
Principle 4: Observability and Testability (Debugging & Stack Traces)
Remember that 50% discount hallucination? That's a testing failure. How do you regression test non-deterministic systems?
This layer captures the full trace. Karpathy calls chain-of-thought the LLM's stack trace. The integration layer captures that, along with the API calls and context that led to the bad output. It can mock API responses and validate agent behavior in a production-like environment before deployment.
The 2026 Playbook: AI Agent Implementation Patterns
Two organizational strategies are emerging for building on this Agent-Native OS. We've seen this pattern before during the web and mobile shifts.
The winners started with small, centralized teams to figure out the new platform. Then they evolved to distributed models where a central platform team enabled everyone else to build.
AI agents follow the same maturity curve.
Implementation Pattern | Pattern A: The "Centralized Agent Team" | Pattern B: The "Self-Serve Platform" |
What it is | A single "Center of Excellence" builds all agents. | A central platform team enables other teams to build agents. |
Best For | Proving initial ROI, building complex, high-value agents. | Scaling AI across the entire organization. |
Pros | High quality, strong governance, deep integration. | Massively scalable, empowers domain experts, and avoids bottlenecks. |
Cons | Creates a central bottleneck that scales slowly. | Requires a mature platform team and vision for governance. |
Pattern A: The "Centralized Agent Team" (The "Get it Done" Model)
What it is: A single AI Center of Excellence builds and maintains all company agents. When sales needs an agent, they file a ticket.
How it's built: This team builds vertical specialist agents one by one (GTM Agent, then Billing Agent) to tackle high-value workflows.
When to use: Most companies start here. It proves ROI, teaches you the technology, and builds reliable agents for critical problems while the platform matures.
Tradeoffs: You get high-quality, deeply integrated, centrally-governed agents. But this team becomes an immediate bottleneck. Everyone else waits months in the queue.
Pattern B: The "Self-Serve Platform" (The "Scaling" Model)
What it is: A platform team builds and maintains the core Agent-Native Integration Layer (the OS, plumbing, auth, governance) as an internal service.
How it's built: The platform team doesn't make final agents. Individual teams (Marketing, Support, Product) use the platform to develop their own domain-specific agents.
When to use: This model scales. Use it after proving value with Pattern A, when you need to empower the entire organization. It's the same playbook as web and mobile platform teams from 2010.
Tradeoffs: It's massively scalable and empowers non-AI teams. But it requires a dedicated platform team and mature governance vision to prevent chaos.
This isn't either/or. It's a maturity curve. The 5% who successfully navigate platform shifts win.
Should You Build vs. Buy an Agent Integration Layer?
You have two paths to this Agent-Native OS layer.
The Critical Difference: Agent-Native Layers vs. Legacy ESB/iPaaS
This is the top question people ask when building AI agents. As Karpathy argues, this is a fundamentally new programming paradigm.
Legacy ESB/iPaaS solutions, such as MuleSoft or Zapier, were built for data transformation. It moved and mapped data between systems (ETL) in deterministic, imperative ways. It was built for machine-to-machine, "pass the JSON" workflows.
An Agent-Native Layer, like Composio, is built for context preparation. It manages state, constraints, and context for non-deterministic reasoning kernels. It doesn't just pass JSONs. It enables you to orchestrate context, handles sudo prompts, and manages I/O for thinking agents. It's built for machine-to-agent workflows.
When to Build In-House
Only consider this if you have a dedicated platform team and your core systems are 100% unique, proprietary, internal tools that no vendor will ever support.
The Hidden Cost: You become Chief Integration Officer forever. You maintain all API schemas, custom field mappings, authentication flows, and retry logic for every tool. It's a massive, ongoing engineering tax that pulls your best engineers from building your actual product.
When to Use External Tools (The "Buy" Option)
Choose this if you want to focus on agent logic (your secret sauce) instead of plumbing.
The Landscape: Zapier and MuleSoft were well-suited for human-in-the-loop workflows; many developers are outgrowing them for AI agents that require real-time, bi-directional, and context-aware capabilities.
This gap created a new category of agent-native integration platforms, purpose-built as Agent-Native layers. They let you focus on the AI.
Dimension | Build Your Own Agent-Native Layer | Buy an Agent-Native Integration Platform (e.g., Composio) |
Time to first production workflow | 6–18 months of platform engineering before the first stable workflow ships. | Days to weeks; plug into existing connectors and focus on agent logic. |
Upfront engineering effort | Dedicated platform team (3–8 engineers) building core plumbing: auth, routing, retriers, observability, tooling. | Minimal; small team integrates SDK/API and defines workflows/tools. |
Ongoing maintenance cost | Permanent ownership of every schema change, API version bump, rate-limit tweak, incident, and retry policy. | Vendor absorbs most API and connector churn; you maintain only your logic. |
Coverage of tools & APIs | Starts at zero; every new SaaS or internal system is a new integration project. | Dozens of production-ready connectors out of the box (GitHub, Salesforce, Slack, etc.). |
Event-driven architecture | Must design and operate your own event bus, webhook ingestion, routing, and retries. | Built-in event/webhook handling; agents can react to events with minimal extra infra. |
Context preparation & RAG | You design schemas, views, and context windows from scratch for each workflow. Easy to fall into “Dumb RAG.” | Opinionated patterns for context shaping and task-level tools, tuned for agents. |
Governance & HITL | Custom design for permissions, approvals, “sudo” prompts, and audit trails. Often an afterthought. | HITL, role-based permissions, and audit are baked into the platform primitives. |
Observability & testability | You must instrument traces, logs, test harnesses, and replay tooling for non-deterministic behavior. | Built-in traces for tool calls, context, and decisions; easier regression testing. |
Scalability across teams | Hard to productize; other teams depend on the original builders to add features and workflows. | Designed as a shared platform that GTM, Support, and Product teams can self-serve on. |
Flexibility/uniqueness | Maximum control; can deeply optimize for highly unique, proprietary systems. | High flexibility via SDKs and custom tools, but within platform abstractions. |
Risk profile | High delivery risk; easy to under-scope integrations and overrun timelines. | Lower delivery risk; the main risk is vendor choice and integration fit. |
Best suited for… | Companies whose core moat lies in their integration layer and can justify a long-term platform team. | Companies whose moat is the agent logic and product, not the plumbing underneath. |
Summary
Building an agent-native integration layer in-house means your best engineers spend months on OAuth flows and API maintenance instead of agent logic. For most teams, buying beats building.
Conclusion: Your 2026 Roadmap to Production-Ready AI
2025 proved the LLM kernel works. The thinking part is possible. But the Stalled Pilot syndrome showed us that brilliant kernels are useless without functional Operating Systems.
In 2026, the integration layer (the OS) determines who wins.
The teams moving from demos to production value will stop focusing on kernels and start obsessing over the OS that feeds them. They'll solve dumb RAG, brittle connectors, and polling tax problems by building true Agent-Native Integration Layers.
Want to be in that winning group? Here's your roadmap:
1. Stop All "Dumb RAG" Pilots. If your plan is "vectorize the wiki and see what happens," kill it now. You're building an expensive, unreliable search box. Pick one high-value workflow instead.
2. Audit Your "Legacy Bottleneck." Map that one workflow (like quote-to-cash). Document every system, API, custom field, and tribal knowledge step it touches. That's your real integration surface area.
3. Find Your "Event-Driven" Gaps. Where do you poll for updates? Which critical systems lack webhooks? These missing interrupts cripple your OS.
4. Explore Agent-Native Platforms. Before writing custom OAuth code, investigate agent-native integration platforms. Understand the build vs. buy trade-off and the long-term cost of becoming Chief Integration Officer.
The truth? You can't escape integration complexity. You can only choose how to manage it.
You can build this entire Agent-Native OS in-house, accepting permanent engineering tax. Or you can build on platforms designed for precisely this purpose. Agent-Native Integration Platforms like Composio let you connect agents to GitHub, Salesforce, and Slack with a single line of code, instantly resolving governance and I/O issues.
The choice isn't just build vs. buy. It's whether your best engineers spend 2026 building brittle plumbing or building the OS that runs your business.
This is a guest post by Manveer Chawla. He is co-founder of Zenith, where they are building AI Agents for marketing teams. He was previously Director of Engineering at Confluent and led Growth Engineering platforms at Dropbox.
Frequently Asked Questions
Why do AI agents fail in production?
AI agents fail due to integration issues, not LLM failures. They run the LLM kernel without an Operating System. The three leading causes are Dumb RAG (bad memory management), Brittle Connectors (broken I/O), and Polling Tax (no event-driven architecture).
What is the difference between an Agent-Native Integration Platform and a traditional iPaaS like MuleSoft?
Traditional iPaaS was built for machine-to-machine data transformation (ETL). An Agent-Native Integration Platform is an OS for the LLM kernel, designed to prepare the machine-to-agent context. It curates context, manages non-deterministic actions, and provides governance.
What is "Human-in-the-Loop" (HITL) for AI agents?
HITL is a governance pattern that works like OS-level permissions. Think of it as a sudo prompt: high-stakes agent actions (like applying a $5,000 credit) automatically route to humans for approval before execution.
Is Composio an Agent Framework?
No, Composio is the Integration Layer (the OS) that connects your agent framework (like LangChain or AutoGPT) to real-world tools (GitHub, Salesforce) with managed authentication and governance.