After so long, OpenAI finally unveiled GPT-4.5, its biggest-ever base model. The initial vibe checks from taste testers have been outstanding. The model has many different vibes than the previous corporate drone-sounding models. It is more expressive, feels natural, and generates excellent green text. Summarizing Karpathy's vibe check post
The model is great at making creative analogies.
It better comprehends subtleties and implicit requests. It picks up on context cues and handles ambiguous prompts more gracefully.
Improved social cues, emotional sensitivity, conversational smoothness, and empathetic engagement.
GPT-4.5, trained only via pretraining and supervised/RLHF fine-tuning, so reasoning will not be on par with frontier thinking models.
It is not a “slam dunk” improvement over GPT-4.
But it is equally good at coding as well.
However, I have been using Claude 3.7 Sonnet, which is insanely good at generating codes but tends to overdo things. Given the insanely good instructions following, I wanted to know how good OpenAI’s new GPT-4.5 is at coding.
So, let’s dive in.
Table of Contents
Brief on the new GPT-4.5
What makes it super expensive
Coding Comparison
Masonry Image gallery design
Typing Speed tester
Real-time collaborative dashboard
Summary
When to use GPT-4.5
TL;DR
If you want to skip straight to the result, Claude 3.7 Sonnet dominates GPT-4.5 in coding. GPT-4.5 is not even close (kinda sucks!) even after being about 10x costlier than Claude 3.7 Sonnet.
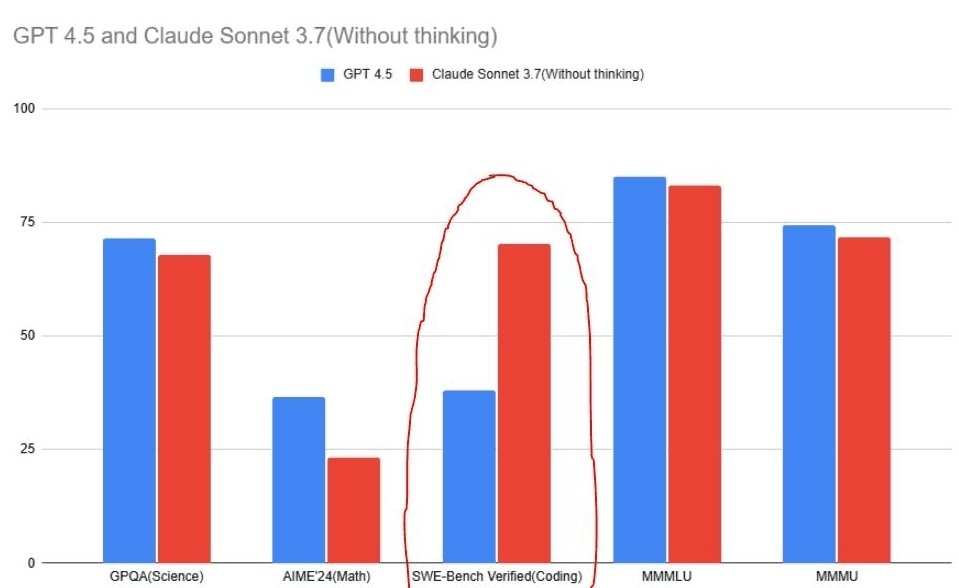
And yeah, that’s fair. Claude 3.7 Sonnet is built for coding, while GPT-4.5 is mainly for writing and designing.
Brief on the new GPT-4.5
On Thursday, OpenAI released an early version of GPT-4.5, a new version of its flagship large language model. The team claims it to be the "biggest and their best model," which feels like talking to a native human.

No, this is not a reasoning model, as OpenAI CEO Sam Altman stated.

This seems to be true. Compared to other models, like Claude 3.7 Sonnet and the earlier GPT-4o models on coding, the percentage accuracy appears to be significantly lower.

Regarding pricing, this is OpenAI's most expensive AI model, with $75 per million input token and $150 per million output token. You can compare the pricing of this model to some of their earlier models side by side:
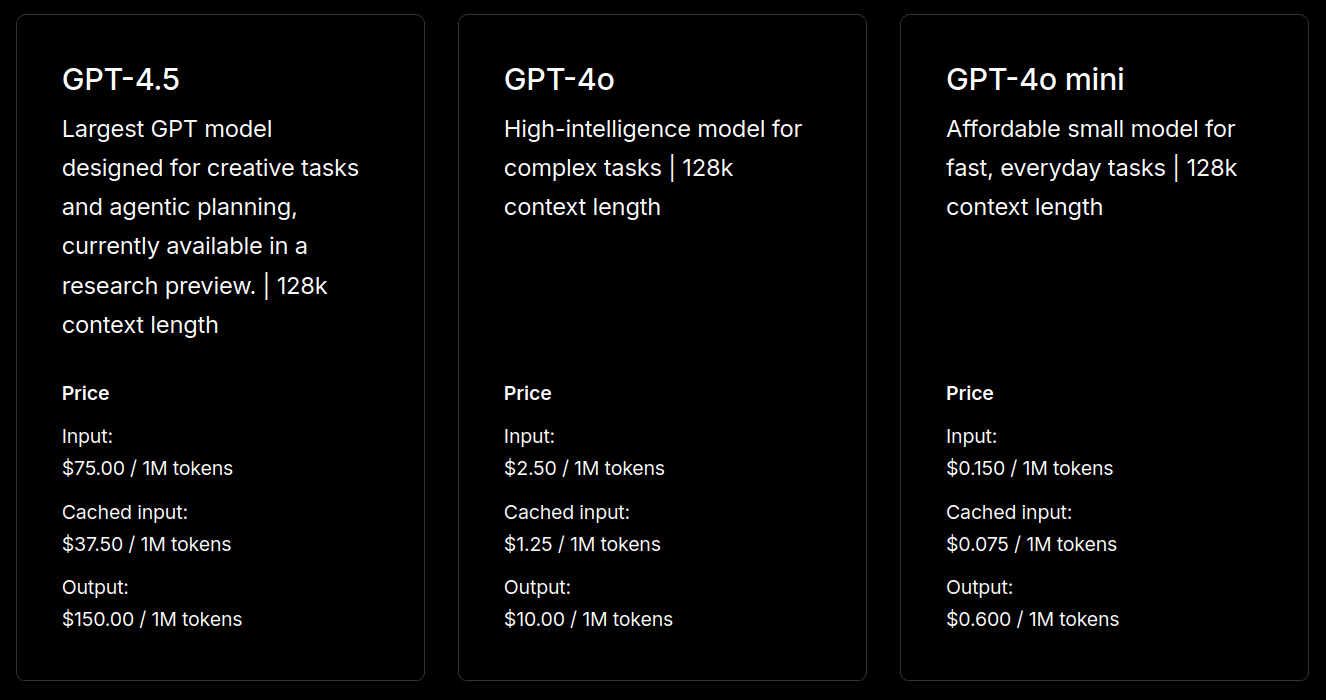
People with a $200-a-month ChatGPT Pro account can try out GPT-4.5 today. OpenAI says it will begin rolling out to Plus users next week.
What makes it super expensive?
Unlike other reasoning models like o1 and o3-mini, which work through the answer step by step, typical large language models like GPT-4.5 spit out the first response they come up with.

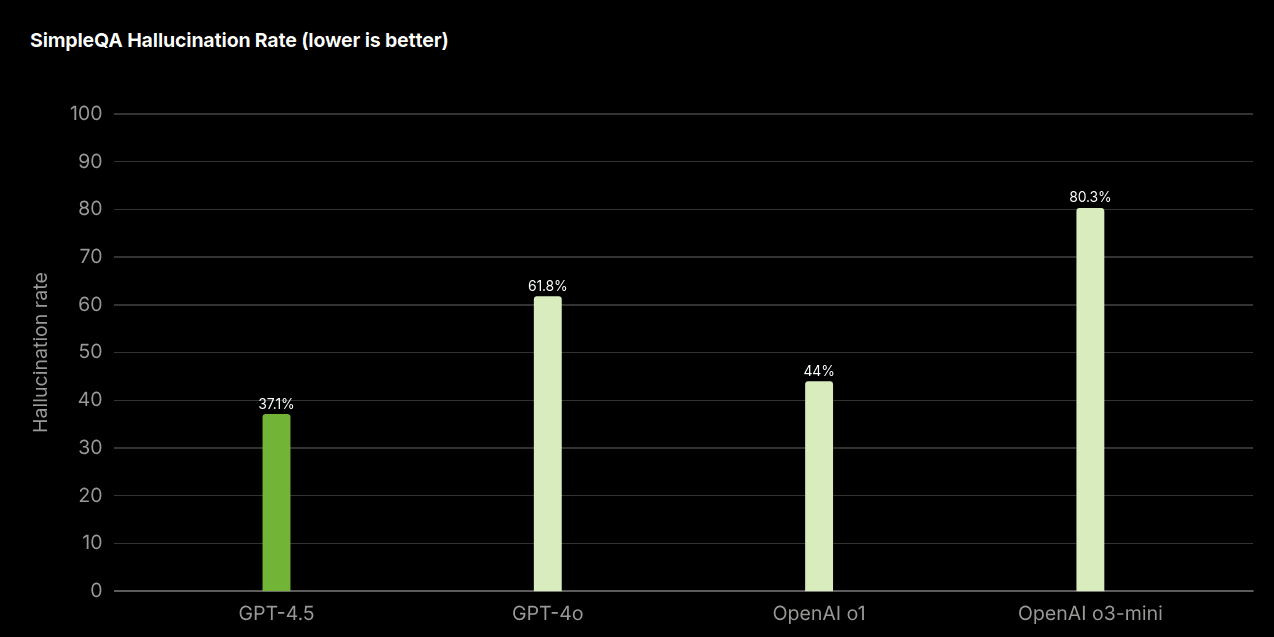
In a general-knowledge quiz developed by OpenAI last year called SimpleQA, which includes questions on everything, models like GPT-4o scored 38.2%, o3-mini scored 15%, and GPT-4.5 scored 62.5%.
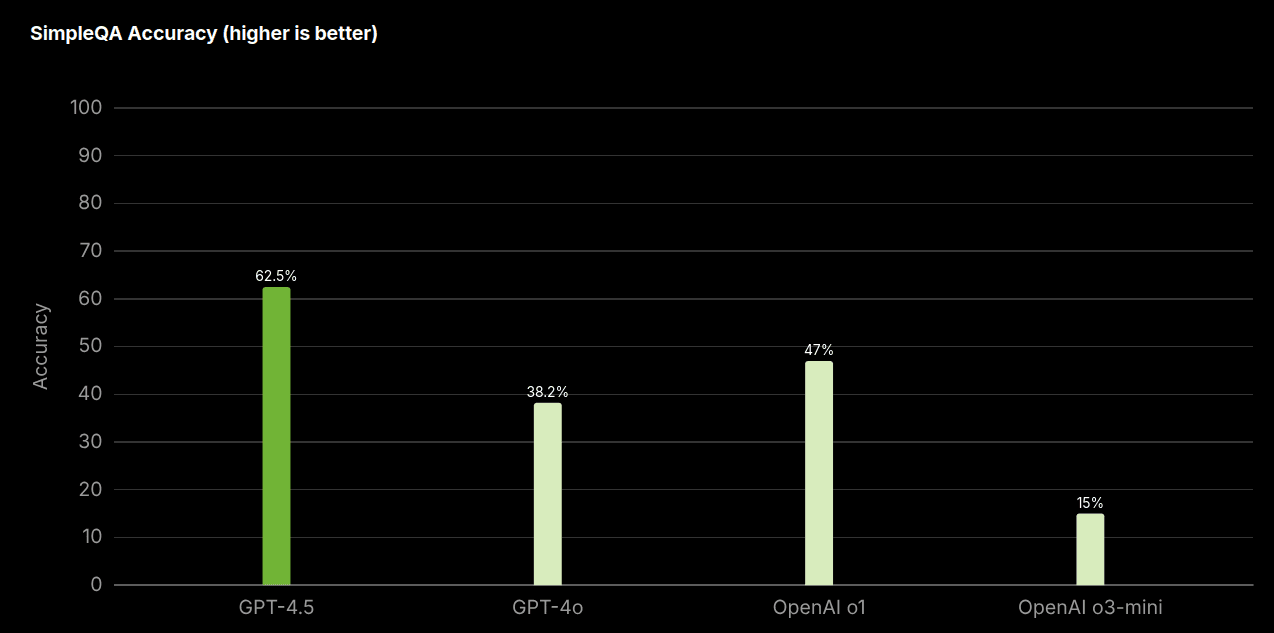
OpenAI claims that GPT-4.5 produces far fewer made-up answers, which are also referred to as hallucinations in AI terms.
It has also enhanced contextual knowledge and writing skills, which is why the model's output sounds more natural with less unnecessary reasoning.
In the same test conducted, the GPT-4.5 model came up with made-up answers 37.1% of the time, compared with 61.8% for GPT-4o and 80.3% for o3-mini.
Coding Comparison
As mentioned earlier, we will mainly compare the two models on front-end questions.
1. Masonry Grid Image Gallery
Prompt: Build a Next.js image gallery with a masonry grid, infinite scrolling, and a search bar for filtering images by keywords. Style it like Unsplash with a clean, modern UI. Optimize image loading. Place all code on page.tsx.
Response from Claude 3.7 Sonnet
You can find the code it generated here: Link
Here's the output of the program:
The output from Claude is pure insanity. Everything is just so perfectly implemented.
I only noticed one small issue: the footer does not stick to the bottom.
Response from GPT-4.5
You can find the code it generated here: Link
Here's the output of the program:
The output from GPT-4.5 is not what I expected. It's savvy that it didn't use npm modules like @tanstack/react-query, but the Masonry Grid layout is missing, and the way infinite scrolling is implemented feels a bit more DIY.
I can't complain much, but it is nowhere near the Claude 3.7 generated code.
Final Verdict: No doubt, the Claude 3.7 Sonnet output is far superior. ✅ It has implemented everything correctly, from the Masonry Grid layout to perfect infinite scrolling using the @tanstack/react-query library. There is still a lot missing in the GPT-4.5 output.
2. Typing Speed Test
Let's test both models by asking them to build a Typing Speed Test app similar to Monkeytype.
Prompt: Build a Next.js basic typing test app. Users type a given sentence with mistakes highlighted in red, allowing corrections. Display real-time typing speed, both raw (with errors) and adjusted (without errors). Once the user types to the end, the test should be over. Place all code in page.tsx.
Response from Claude 3.7 Sonnet
Find the code here: Link
Claude 3.7 Sonnet generated app
It just feels illegal to use this model for coding. How good is this? I have no words to say.
In no time, with everything implemented correctly, it built this entire typing test site with more than what I asked for. It even added an accuracy display.
Response from GPT-4.5
You can find the code it generated here: Link
App created by GPT-4.5
GPT-4.5 got this one correct, but there's one minor issue with the code it generated. Once the user reaches the end, the test is supposed to end, but it doesn't unless the user goes back and fixes it.
Final Verdict: The generated code response from GPT-4.5 has one minor issue, but it's fair to say both models got it correct.
3. Collaborative Real-time Whiteboard
This one's pretty tough, and I am unsure if Claude 3.7 will also correct it. It requires setting up a separate web socket server and listening on the connections.
Let’s see how they generate the code for this problem.
Prompt: Build a real-time collaborative whiteboard in Next.js with Tailwind for styling. Multiple users should be able to draw and see updates instantly. But, when a user clears their canvas, the other user's canvas should not be removed.
Response from Claude 3.7 Sonnet
You can find the code it generated here: Link
Here's the output of the program:
Okay, now I see some complete junior developers getting replaced by AI pretty soon.
It would take me a long time to code this. I am starting to see why this model is called a beast when it comes to coding—it is just perfection!
Response from GPT-4.5
You can find the code it generated here: Link
Here's the output of the program:
GPT-4.5 failed severely here. The web-socket connection was established, but there was an issue parsing the data received from it on the client.
Final Verdict: Claude 3.7 Sonnet just crushed this one as well. The code generated is perfect, and the output is exactly what I wanted. GPT-4.5 established the web-socket connection but had an issue parsing the data. Even after I tried to iterate on its mistake, it couldn't fix it.
Summary
You should be pretty clear on the results here. Claude 3.7 won by a considerable margin, and hey, again, I'm going to say that this comparison is not fair on GPT-4.5 as it is not trained to be good at coding. But at least it got the first two problems working, even though it was imperfect.
When to use the GPT-4.5 model
Now that we have a general understanding of this model's abilities, let's look at situations in which you might prefer this model over anything else.
Overall, GPT-4.5 is not a model you can rely on for reasoning tasks. GPT-4.5 better understands what humans mean and can interpret subtle cues. It's designed to improve conversations, design, and writing, adding that bit of human touch.
This model is ideal when you need a use case for which you're very specific about writing or designing.

Conclusion
We can conclude that Claude 3.7 Sonnet is just miles ahead when generating raw codes compared to GPT-4.5, and the only model on par is Grok 3. You can check our code comparison of Claude 3.7 Sonnet and Grok 3.