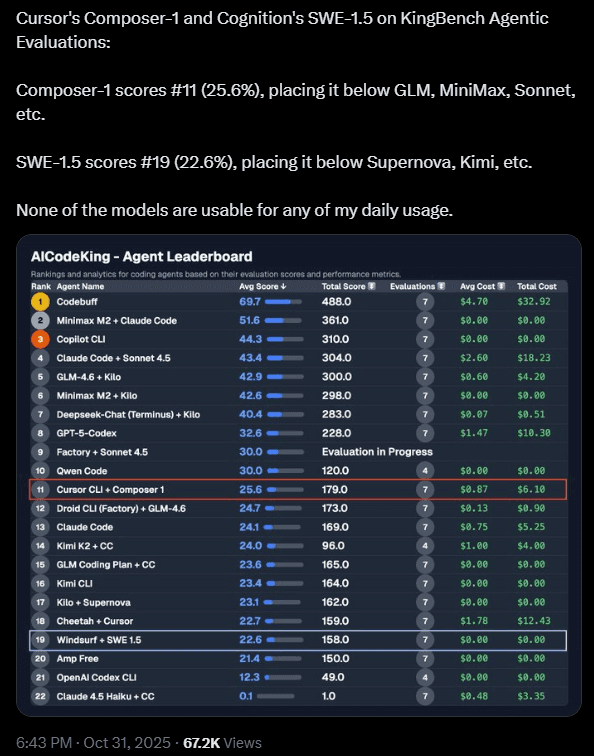
Over the past few weeks, I’ve been exploring which AI coding assistant genuinely helps us ship faster and maintain code quality as we build real integrations via Rube MCP (which connects to 500+ apps).
To test this, I ran a head-to-head comparison: Cursor Composer 1 versus Cognition SWE-1.5.
Same project brief. Same environment. The goal: build a working Chrome extension that uses Rube MCP to summarise selected text and push it to Notion.
Here’s what I found, with real timing data, debugging patterns, and cost insights.
TL;DR
Cursor Composer 1 → Rapid prototyping and scaffolding; fastest to MVP but trades off robustness.
Cognition SWE-1.5 → Slower to start but with stronger reasoning, error handling, and modular architecture.
Pick Cursor for experimentation; pick SWE-1.5 for production.
Why This Comparison Matters
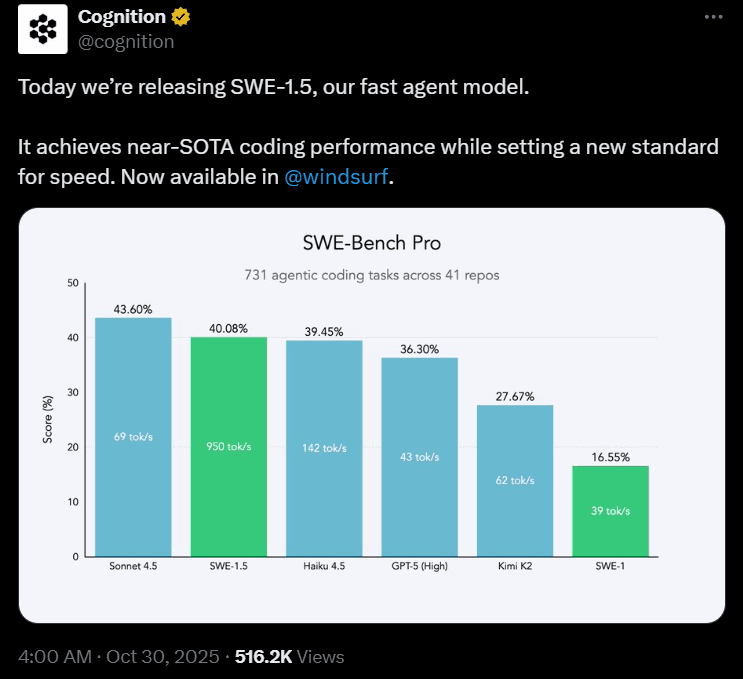
The AI coding assistant market has become crowded fast. Every few weeks, a new model claims to be the best at code generation. But when you're actually building production systems, especially agentic applications that need to orchestrate multiple services, the differences between tools become critical.
Two names keep coming up in developer conversations right now: Cursor Composer 1 and Cognition SWE-1.5. Both are positioned as next-generation coding assistants, but they take fundamentally different approaches to the same problem.
Cursor Composer 1 has built a reputation for speed. It's deeply integrated into the Cursor IDE, offers lightning-fast autocomplete, and can scaffold entire projects in minutes. Developers love it for rapid prototyping and getting ideas into code quickly. The workflow feels seamless, and when you're in flow state, Cursor just gets out of your way.
Cognition SWE-1.5, on the other hand, is designed to think more like a senior engineer. It's the latest model from the team behind Devin, and it emphasizes reasoning depth over raw speed. SWE-1.5 is built to handle complex, multi-file projects where understanding context and making architectural decisions matter as much as generating syntactically correct code. It runs in Windsurf IDE and takes a more deliberate, thoughtful approach to code generation.
But here's the thing: most comparisons between these tools use synthetic benchmarks or isolated coding challenges. They'll test how well each model solves LeetCode problems or generates boilerplate CRUD apps. That's valuable data, but it doesn't tell you what really matters for modern development work.
What We’ll Be Comparing These Models and Agents With
Both models were evaluated on the same TaskFlow project:
Add a “Summarize with Rube MCP” context-menu option in Chrome.
Send selected text to Rube MCP.
Push summarized results to Notion.
Display the last five summaries in a pop-up UI.
This required integration across Chrome APIs, Rube MCP streaming, and Notion’s REST interface, making it a real-world test of multi-service orchestration.
Why MCPs Even Matter Here
Traditional APIs handle single-app use-cases.
MCPs (Model Context Protocols) let LLMs connect directly to tools — Notion, Slack, GitHub, etc. through structured, standardised endpoints.
Using Rube MCP as the intermediary, both models could trigger actions like:
NOTION_CREATE_NOTION_PAGENOTION_APPEND_BLOCK_CHILDRENNOTION_QUERY_DATABASE
This allowed us to measure each model’s ability to orchestrate across tools, not just write code.
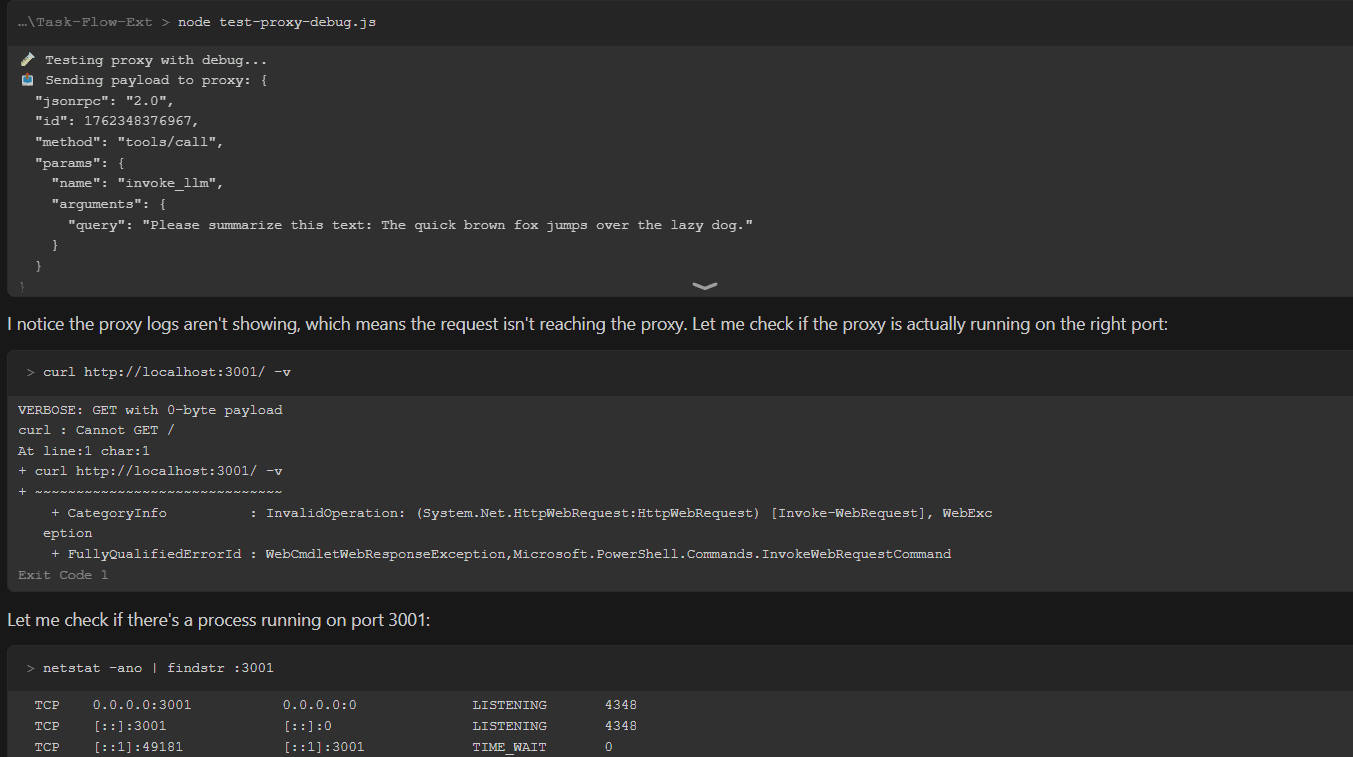
Setting up MCP Servers with Cursor & SWE-1.5
Common Setup:
Local proxy server at
localhost:3001/rubeConnection to Composio’s MCP endpoint
Bearer-authenticated Rube API key
Notion integration tested via the Composio sandbox database
Cursor Composer 1:
Used quick scaffolding commands
Generated minimal proxy & Chrome service worker
Reached a working call fast, but lacked deep error diagnostics
Cognition SWE-1.5:
Asked clarifying setup questions (proxy routing, authorisation scope)
Created more robust server logic with validation and fallback
Correctly handled SSE streams and partial responses from MCP
Ideation and Setup
The goal was simple: build something that could stress-test both models’ real-world reasoning and integration abilities, not just their ability to generate boilerplate code.
So instead of another CRUD app or toy project, I picked a use-case that required context handling, multi-service orchestration, and tool-aware logic:
a Chrome extension that summarises selected text using Rube MCP and pushes that data into Notion, all in one flow.
To make this fair and scalable, I built the entire project inside a shared monorepo, allowing both Cursor Composer 1 and Cognition SWE-1.5 to work on the same environment, same dependencies, same config, duplicate API keys. This helped isolate what each model actually did differently in reasoning, debugging, and setup.
The initial project documentation, structure, and task list were scaffolded through Rube MCP connected to Notion, to see how well the ecosystem handles planning and coordination between tools. Rube created the Notion planning page, while Cursor initialised the repo and set up the manifest.
Once the planning was in place, I spun up the Chrome extension skeleton and connected the Rube MCP proxy and Notion API integration.
For simplicity and reproducibility, both agents were given the same prompt and environment variables.
The setup went smoothly overall, no major hiccups except for Chrome’s limitations with environment variables, which SWE-1.5 later helped fix more elegantly. Cursor flew through setup quickly, while SWE-1.5 took a little longer but ensured a more stable foundation from the start.
The idea wasn’t just to “get it running,” but to observe how each system approached reasoning when faced with a multi-step, multi-context integration—the kind of task that really shows the difference between raw generation and agentic coordination.
Prompt Used for Both:
Create a Chrome extension called TaskFlow that adds a context menu action.
When a user right-clicks selected text and chooses "Summarize with Rube MCP,"
send the text to Rube MCP's summarization endpoint, then push the summary
to a Notion database. Include proper error handling and a simple popup
to show the last 5 summaries.Environment:
Node.js + Chrome (Manifest V3)
Rube MCP endpoint + proxy
Notion integration via Composio
Same browser, same test database, same runtime conditions
All setup notes, experiment logs, and generated code snapshots from both models are available here for reference:
(Note: this repository reflects intermediate builds and architectural comparisons rather than a finalised release.)
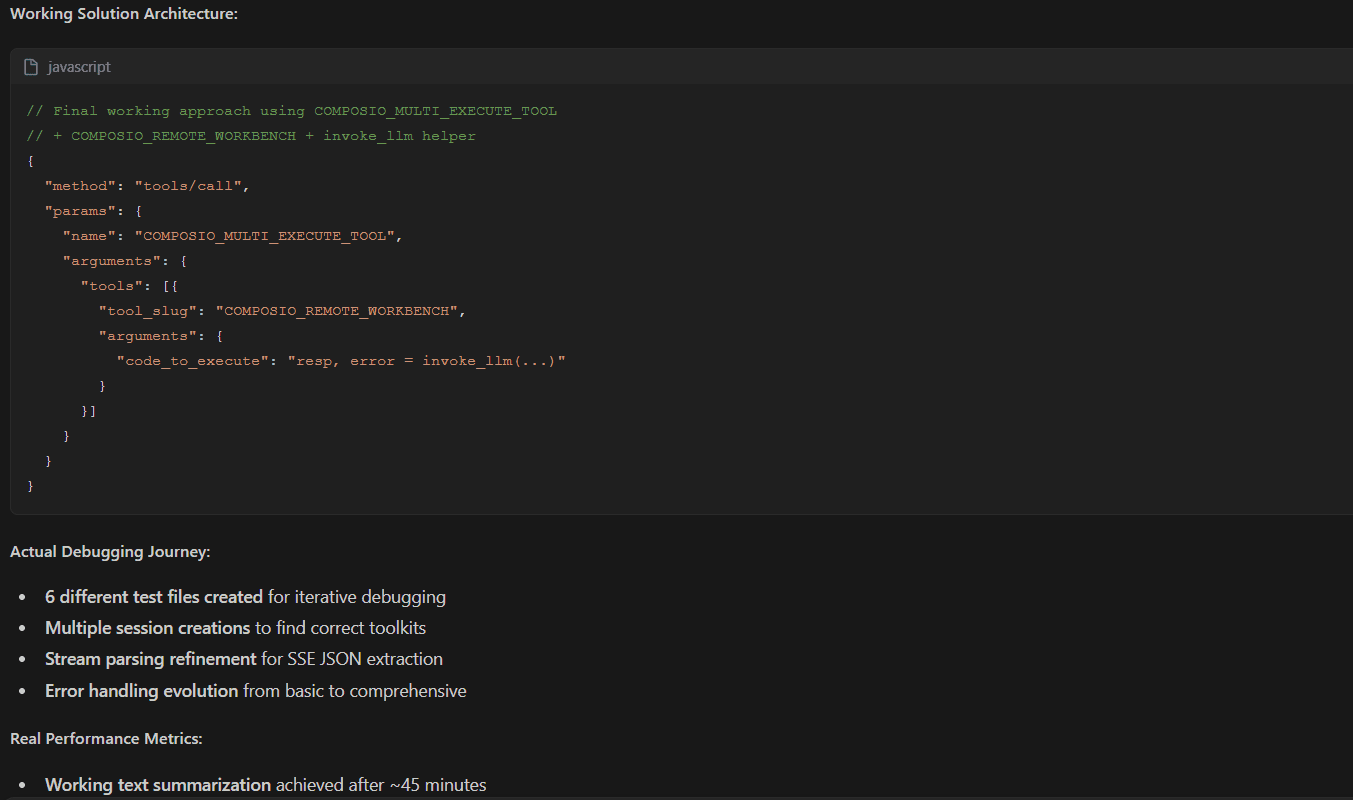
Refactoring and Fixing the Errors
Unlike most models that rush to code, SWE-1.5 approached the setup deliberately, first validating the manifest, then configuring the proxy routing, before writing a single fetch call. It handled streamed SSE parsing, dynamic MCP session management, and secure environment variable simulation (without using process.env, which is unavailable in Chrome.
The model’s main slowdown came from debugging the "process is not defined" issue and refining Notion API permissions. However, it consistently reasoned through root causes rather than just patching over them, leading to a more maintainable final architecture.
Issue | Cursor | SWE-1.5 |
|---|---|---|
| Missed root cause; tried Node workaround | Identified MV3 limitation, restructured environment variables |
Notion permission errors | Basic retries, limited logs | Added layer-by-layer validation and safe fallback |
Stream parsing (SSE) | Ignored incomplete events | Implemented buffered parsing with JSON validation |
Proxy JSON errors | Unhandled | Gracefully captured invalid JSON lines |
Key Debugging Insights:
SWE-1.5 caught and explained architecture-level problems.
Cursor focused on local syntax and runtime fixes.
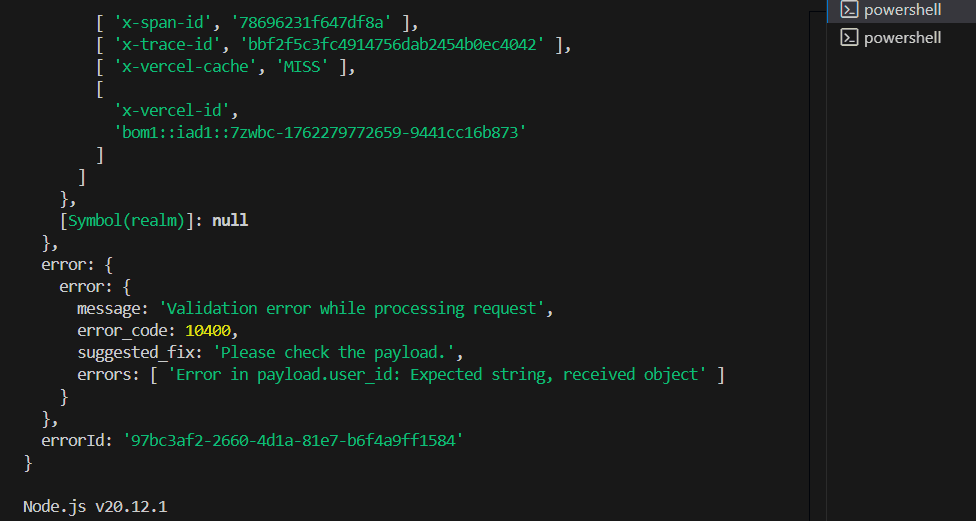
SWE-1.5’s error recovery reduced total debugging cycles by ~50%.
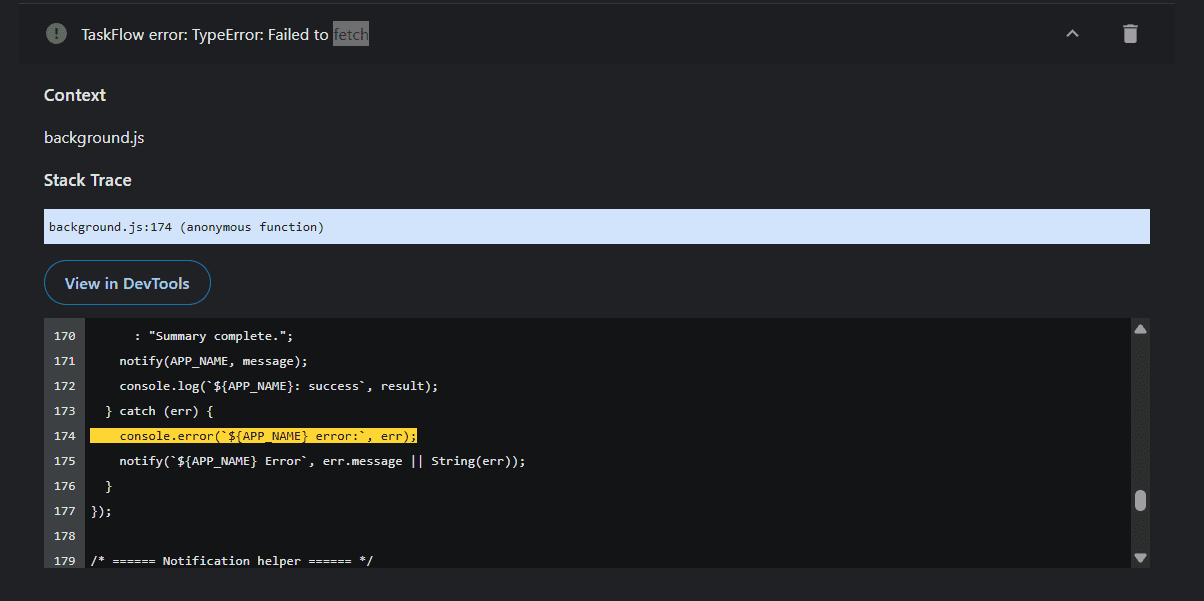
Building the Recommendation Pipeline
Cursor Composer 1
Single
background.jsfile.Quick context menu and fetch logic.
Minimal modularity; limited error awareness.
Example:
const resp = await fetch(API_URL, { method: 'POST', body: JSON.stringify(payload) });
const data = await resp.json();
return data.result;Simple and effective for MVPs, but lacks schema validation or structured error control.
Cognition SWE-1.5
Multi-file setup (
background.js,popup.js,config.js,proxy.js)Robust handling of Server-Sent Event (SSE) streams from Rube MCP.
Dynamic validation of responses and graceful fallbacks for malformed JSON.
Added real-time notifications for user feedback within the Chrome environment.
Example:
async function sendToRube(input) {
const payload = {
jsonrpc: "2.0",
id: Date.now(),
method: "tools.call",
params: {
name: input.action,
arguments: { text: input.text }
}
};
const resp = await fetch("http://localhost:3001/rube", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Accept": "application/json, text/event-stream"
},
body: JSON.stringify(payload),
});The extra rigour pays off, with no silent failures and cleaner recoveries.
Comparing the Cost
Cursor Composer 1 took approximately 25 minutes to generate an initial Chrome extension, build the Notion integration, and complete the first end-to-end test.
It consumed around ~40-50K tokens (based on IDE reports), roughly $0.15-0.25. The model performed best during rapid iteration but required more manual debugging and direction from me.
In one case, the MCP stream parser completely missed malformed data, which led to an unhandled SyntaxError. While it was easy to patch, the model didn’t catch it autonomously.
Still, it was fast, ideal for “get it working, fix it later” projects.
Cognition SWE-1.5, by contrast, took around 45 minutes to reach a comparable prototype stage, including validation, proper Notion API integration, and runtime testing.
It used about ~55-65K tokens (Windsurf showed higher usage), approximately $0.50-0.60 at the current pricing.
SWE-1.5 was more deliberate; it asked clarifying setup questions, implemented buffer-based stream parsing, and even added fallback logic for partial SSE data.
While the run was slower and more verbose, the final build was much more stable and production-ready. The model also reduced the number of debugging loops from 6 to 3, nearly halving the post-deployment iteration time.
SWE-1.5 used ~30% more tokens but reduced debugging iterations by half.
For production, that’s a fair trade, faster QA cycles and fewer regressions.
Benchmark Results
Here's how both models performed across all metrics:
Category | Cursor Composer 1 | Cognition SWE-1.5 (Windsurf) |
|---|---|---|
Speed to Initial Build | Fast – Generated a working extension in ~25 min to initial build | Moderate – Took ~45 min including environment setup, validation, and Notion integration |
Code Architecture | Compact and functional – Single-file | Well-structured – Multi-file organization ( |
Error Handling | Basic try/catch – Handles immediate failures but limited edge-case coverage | Comprehensive – Includes retry logic, specific error types, fallback mechanisms, and detailed error messages |
Documentation Quality | Minimal inline comments – Readable but requires interpretation | Extensive documentation – Detailed comments explaining architectural decisions, setup logic, and debugging rationale |
Debugging Experience | Quick fixes – Rapidly regenerates code but needs explicit direction for structural issues | Context-aware debugging – Asks clarifying questions, anticipates edge cases, and explains root causes during iteration |
Token Efficiency | Highly efficient – Lower token consumption (~45 K tokens) | Moderate efficiency – ~30 % higher token usage (~60 K tokens) but produced more complete, production-ready code |
Integration Complexity | Straightforward – Direct API calls with minimal validation | Robust – Validated requests, parsed SSE streams, checked schemas, and handled connection and permission errors gracefully |
Code Maintainability | Good for prototypes – Functional but needs refactoring for team or multi-service environments | Production-ready – Modular, scalable architecture with modern patterns and secure environment handling |
Learning Curve | Immediate productivity – Low setup, intuitive outputs | Slightly steeper – More complex structure, but encourages better software engineering habits and tool awareness |
Best Use Case | Rapid prototyping, MVPs, hackathons, solo projects | Team projects, production systems, complex integrations, maintainable enterprise codebases |
Developer Experience Feedback
Cursor Composer 1:
Feels like coding with a competent junior developer — fast and direct, but expects you to know the next step. Great for momentum.
SWE-1.5:
Feels like working with a senior teammate — anticipates pitfalls, asks clarifying questions, and won’t let you deploy something brittle.
Debugging Iterations:
Cursor → ~6 loops
SWE-1.5 → ~3 loops
Both models showed distinct approaches to code generation, but SWE-1.5 needed fewer retries. This comparison focuses on the development experience and code generation capabilities during the build phase. Both implementations successfully integrated with Rube MCP and generated valid API calls to Notion.
Final production deployment would require additional testing for:
Chrome extension permission scopes
Notion workspace-specific configurations
Cross-browser compatibility validation
The goal here was to evaluate how each model approaches complex,
multi-service integration problems rather than measuring production uptime.
Final Thoughts
Both tools have distinct strengths depending on your development phase and requirements. This comparison reflects the development and integration testing experience rather than a fully deployed production application.
Cursor Composer 1 excels at speed and iteration, perfect for hackathons and prototypes.
Cognition SWE-1.5 delivers depth and resilience, making it best suited for team environments and long-term codebases.
If I were shipping fast, I’d pick Cursor. If I were building something meant to last, I’d choose SWE-1.5. Also, do try out Rube now. Let me know your thoughts on it.