AlphaEvolve is here, and DeepMind has done it again. It is the first evolving agent for solving complex algorithmic and scientific problems and the spiritual successor of FunSearch. It retains some of Funsearch’s core tenets but dramatically improves in code evolution, evaluation, context, and search. AlphaEvolve leverages an evolutionary loop to improve a problem or part of it continuously.
Yes, and it’s not reinforcement learning but a neatly designed system of Gemini model ensemble, an evolutionary database, a robust evaluation scheme, and prompt sampling. In doing so, they have achieved incredible improvements in solving math problems and Google’s engineering challenges.

This is by far the best agent scaffolding done to date. It also says a lot about the potential of current state-of-the-art models. We are yet to explore the full capability of frontier models. This motivates us, kind folks at Composio, to build for the future of agents.
If we can solve scientific problems using current LLMs with scaffolding, half of what we do now can also be improved, given that the tasks are measurable. One limitation of AgentEvolve is that it only applies to problems that can be evaluated without human intervention. Hence, they went for algorithmic issues.
This is undoubtedly one of those papers everyone in AI must read. This blog post will discuss how it works and the outcomes
AlphaEvolve “the agent”
AlphaEvolve was tested on a range of algorithmic and scientific discovery problems, including 54 specific tensor decomposition targets for matrix multiplication, over 50 curated open mathematical issues, and four distinct optimization challenges within Google’s AI infrastructure (data center scheduling, Gemini LLM kernel engineering, TPU circuit design, and compiler-generated code optimization).
Surprisingly, the AlphaEvolve could match the previous optimal outcome and improve in many of them. More on this later.
Terence Tao also worked alongside the DeepMind team to construct AlphaEvolve.

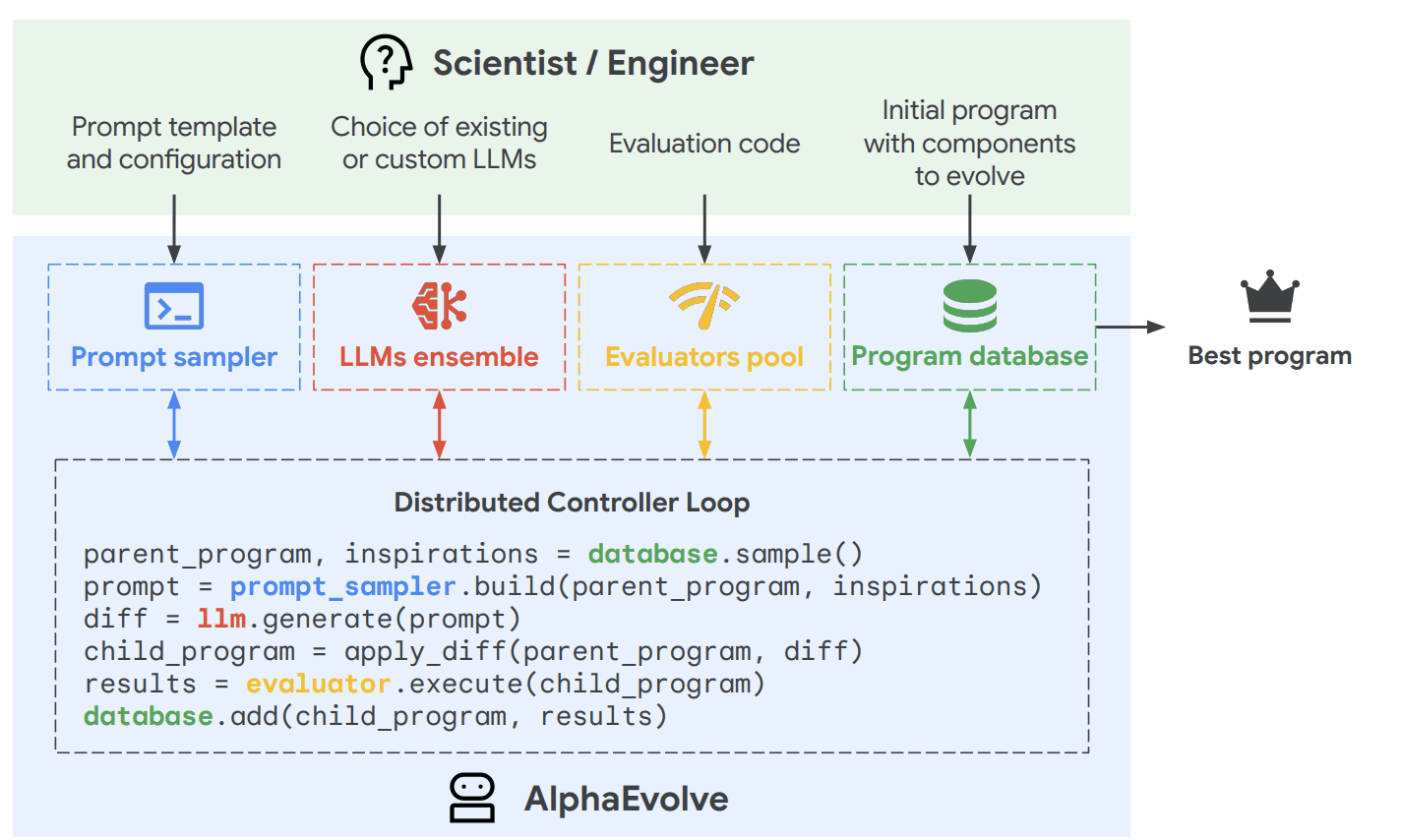
Components of AlphaEvolve
Before moving to the workflow part, let’s briefly review each vital component of the AlphaEvolve architecture.
The Evolutionary database
The most interesting part of the setup is the evolutionary database’s design, which is central to AlphaEvolve’s ability to drive discovery. This database is inspired by evolutionary computation techniques, specifically MAP-Elites (Multidimensional Archive of Phenotypic Elites) and island-based population models.
Instead of merely storing a few top-performing programs, the database maintains a diverse, high-quality collection of solutions. Candidate solutions (programs) are evaluated based on one or more user-defined scalar metrics, which could represent performance on different test cases, resource utilisation (like execution time or memory), or even LLM-assessed code quality (like simplicity).
From this collection, the system strategically selects “parent” programs as the direct basis for further improvement, and “inspiration” programs to provide diverse examples and spark novel ideas when prompting the LLMs. The exact implementation details of how MAP-Elites and island models are precisely combined haven’t been published.
LLM Ensemble
AlphaEvolve uses a combination of Gemini 2.5 Pro and Gemini 2.0 Flash. The Flash model helps generate solutions quickly, while the more powerful Gemini 2.5 Pro is used for advanced reasoning and coding tasks. This keeps the overall cost and time of the operations optimal.
Evaluation Framework
AlphaEvolve’s core evaluation relies on a user-defined Python function (h) that assesses candidate programs and returns scalar metrics to maximise. This function ranges from simple checks to complex computations involving search algorithms or ML model training.
Key enhancement mechanisms:
Evaluation Cascade: Programs face increasingly challenging tests, allowing early elimination of weak candidates.
Parallel Evaluation: Computationally intensive assessments are distributed across clusters, dramatically reducing evaluation time.
LLM Feedback: Separate language models provide qualitative assessments on code simplicity, creating additional optimisation metrics.
Multi-Objective Optimisation: The system optimises for several objectives simultaneously, producing robust solutions even when primarily focusing on a single metric.
Prompt Sampling
Crucial for guiding LLM responses, AlphaEvolve’s prompt sampling mechanism intelligently crafts custom prompts by strategically combining elements from its evolutionary database. It selects “parent” programs for direct improvement and “inspiration” programs to provide diverse examples, then enriches these with any additional human-provided context (like problem descriptions or relevant literature) and often includes feedback from previous LLM trials. This rich, contextualised input ensures the LLMs receive targeted guidance to generate meaningful and varied code improvements.
How does this work?
This is the typical flow of the AlphaEvolve
Defining the Problem & Setup:
The Codebase & Evolution Blocks: The user provides an initial codebase. Special comments (e.g., # EVOLVE-BLOCK-START and # EVOLVE-BLOCK-END) mark specific sections of this code that are intended for improvement. This tells AlphaEvolve which parts it can modify.
The Evaluation Oracle: The user must provide an automated “evaluation function” (h). This function takes any generated program (a modified codebase) as input and outputs one or more scores that quantify how “good” that solution is (e.g., faster, more accurate, uses fewer resources). AlphaEvolve aims to maximise these scores.
The Evolutionary Loop:
Program Database: AlphaEvolve maintains a database of programs it has seen and their evaluation scores. This database selects promising “parent” programs for further improvement and “inspiration” programs to provide diverse examples to the LLMs. It’s designed to balance exploring new ideas and exploiting good ones.
Prompt Sampler: This component intelligently selects parent programs and inspirations from the database. It then constructs a rich, detailed prompt for the LLM ensemble. This prompt includes the code to be improved, examples of successful past attempts, the user-provided context, and instructions on suggesting changes.
Optional Context: The user can also provide additional information, such as problem descriptions, relevant scientific papers, or specific instructions, to guide the LLMs.
LLM Ensemble: A combination of Gemini 2.5 pro and Flash receives the prompt and generates suggestions for code modifications. These suggestions are often in a “diff” format (showing what to search for and what to replace it with), allowing for targeted changes.
Applying Changes: The proposed code modifications are applied to the parent program to create a new “child” program.
Evaluation: The newly generated child program is then automatically tested using the user-defined evaluation function (h). This step is critical as it grounds the LLM’s suggestions in actual performance. AlphaEvolve can handle complex evaluations, including:
Evaluation cascades: Testing on progressively harder tasks. This helps weed out candidates quickly.
Parallelised evaluation: Speeding up testing for computationally intensive problems.
Multiple metrics: Optimising for several objectives at once.
Database Update: The child program and its scores are added to the Program Database. This allows the system to learn from what worked and what didn’t, driving continuous improvement.
Ablation
DeepMind conducted an ablation study to understand each component’s contribution. They tested on two specific problems: tensor decomposition for faster multiplication and computing lower bounds on the kissing number.
Evolutionary Approach: Performance significantly dropped without iterative improvement (“No evolution”), highlighting the benefit of learning from past programs.
Context in Prompts: Removing problem-specific context (“No context”) from prompts reduced effectiveness.
Meta-Prompt Evolution: Disabling co-evolved prompts (“No meta-prompt evolution”) hurt performance, indicating value in the system refining its own LLM instructions.
Full-File Evolution: Evolving only parts of the code (“No full-file evolution”) was less effective than evolving entire marked codebases.
Powerful Language Models: Using only a small LLM (“Small base LLM only”) instead of the ensemble significantly degraded results, confirming the need for capable models.

Breakthroughs
The most interesting part is that DeepMind tested the agent on 50 open mathematics questions from Geometry, Analysis, Combinatorics, and Number Theory. AlphaEvolve matched the previous optimal solutions for 75% of the problems and improved the existing solutions for 20% while underperforming on only 5%.
How did AlphaEvolve improve the solutions?
The key methodological innovation enabling these discoveries is AlphaEvolve’s ability to evolve heuristic search algorithms rather than directly evolving the constructions themselves. For many problems, particularly those with fast objective function evaluations—which are common in mathematics—we employed an iterative refinement strategy. Each generation of AlphaEvolve was tasked with evolving a program representing a search heuristic. This program was given a fixed time budget (e.g., 1000 seconds) and was shown the best construction found by the previous best heuristic. Its goal was to leverage this starting point and the allotted time to find an even better construction. The evolutionary process thus selects for heuristics that are effective at improving already high-quality solutions. The final constructions were often the result of a sequence of different, specialized heuristics discovered by AlphaEvolve—early heuristics proficient at making large gains from random or simple initial states, and later heuristics adept at fine-tuning near-optimal configurations. This automated discovery of multi-stage, adaptive search strategies is challenging to replicate manually and proved crucial for surpassing the SOTA
Clever indeed.
Matmul optimization
Out of all the most exciting is the improvement in matmul optimisations.

Kissing Number
A breakthrough in geometry. It’s now possible to kiss one more sphere in 11 dimensions. AlphaEvolve’s run on the classic “kissing-number search” tasks found a packing in 11-dimensional space where 593 spheres touch the central sphere, nudging past the long-standing record 592.
Apart from these, Erdős Minimum-Overlap in Combinatorics, the Packing problem, Autocorrelation, and the Uncertainty principle.

Engineering Breakthroughs
AlphaEvolve also solved three production engineering challenges.
1. Data centre scheduling

2. TPU GEMM kernel tiling
The agent evolved a tiling rule for the GEMM kernel used in Gemini training; the new layout trimmed cache misses and lifted kernel throughput by ≈ 23 %, translating to a ≈ 1 % reduction in end-to-end model-training time.
3. Compiler IR optimisation
AlphaEvolve also edited an XLA-HLO pass chain, fusing a pre-load, FlashAttention core, and post-store, yielding ≈ 32 % faster device kernels and a further ≈ 15 % host-side speed-up on GPU inference paths.
Conclusion
Too much alpha in a single paper. The AlphaEvolve is revolutionary, and the fact that they have been sitting on it for a year is. The Agent was using the previous generation LLMs, and it can even do better with the current SOTA models.
It’s going to be interesting to see where this goes and how other labs leverage a similar principle to build human-equivalent agents.