After using Claude Code for serious coding work, the biggest lesson is simple: token consumption is not mainly a pricing issue. It is a workflow problem.
When my Claude Code session gets messy, performance drops. It starts rereading irrelevant files, remembering failed attempts, carrying old logs, and wasting context on things that no longer matter.
So my workflow is built around one principle:
Keep Claude's active context small, clean, and useful.
These are the 8 best ways to reduce token consumption in Claude Code that I use every day and can probably help you too.
tldr;
Don't send raw logs or full test results. Use filters and simple command wrappers to show only what matters: the error, the stack trace, the key details.
Sonnet handles most coding work fine and costs less. Use Opus for the really hard problems. For helper tasks and exploration, use Haiku.
Don't run expensive models on simple edits, and turn off extended thinking when you don't need deep reasoning.
Use
/compactduring a cleanup task while keeping what's important.Use
/clearwith ahandofffile when switching to something completely different. This doesn’t let old failed attempts pile up in context memory.Only put instructions that Claude needs most of the time (how to run tests, build commands, folder structure, main rules). Keep everything else in separate skill files and only load them when you actually need them, saving your tokens.
Use Composio MCP to manage 1000+ tools as a single system instead of juggling 30+ active servers. When tasks are simple enough to use shell commands, use the composio CLI.
1. Filter the tool output before Claude sees it
Raw logs are garbage for context. Claude does not need a 10,000-line test output. Instead, it needs the failing test, the stack trace, the expected vs. received values, and maybe the changed files.
So I avoid this:
npm testAnd use filtered commands:
npm test2>&1 |grep-A5-E"FAIL|ERROR|Error|Expected|Received" | head-100In my ideal setup, I create small wrappers like below and use them when needed:
cc-test
cc-lint
cc-typecheck
cc-log
cc-ciBottom line here is, I let Claude consume summaries, not terminal noise.
This one change saves the most tokens because it prevents context pollution before it even starts.
2. Match the model to the task
Not every task needs the same horsepower, and running Opus on everything is one of the most expensive habits in Claude Code. Most coding work does not need Opus. Sonnet handles it at a fraction of the cost.
My setup:
/model sonnet → default for most coding work
/model opus → complex architecture, deep reasoning, tricky bugs
/model haiku → repetitive tasks, boilerplate, quick lookupsI switch to Opus when I genuinely need deeper reasoning, and switch back as soon as the hard part is done.
For subagents specifically, I set:
CLAUDE_CODE_SUBAGENT_MODEL=haikuThis means exploration agents, log inspectors, and doc-lookup agents all run on Haiku. The main thread stays on Sonnet.
Extended thinking is another hidden cost - it burns output tokens for internal reasoning. For simple edits, I disable it:
MAX_THINKING_TOKENS=0 → trivial tasks
MAX_THINKING_TOKENS=10000 → architectural reasoningIn fact, this approach is so effective that it rarely lets my context memory fill up before it resets the 5-hour limit. Basically unlimited usage!
Bottom line: Using Opus for everything is like running every database query on your most expensive production server. Match the model to the work.
3. Don't let one session run forever with /clear + /compact + handoffs
After enough turns, the context fills with old attempts, wrong theories, stale file reads, and outdated decisions. Even if Claude still remembers everything, much of that memory is now toxic.
So I use /clear, but with a different workflow. I create a handoff.md file, include all the relevant details required, like goal, changed file, decisions made, and so on
Here is how you can do it too.
Before clearing:
Ask Claude to write .claude/session-handoff.md
Include:
- current goal
- changed files
- decisions made
- failing tests
- root cause
- next stepThen I run:
/clearAnd restart with:
Read .claude/session-handoff.md and continue.This gives me the best of both worlds: fresh context without lost progress.
For mid-task cleanup without a full reset, I use /compact instead. But I never run it blindly. Before compacting, I tell Claude exactly what to preserve:
/compact Preserve: optimistic locking for user updates, no schema changes this session.Then:
/compactThis shapes what the summary will capture. In short, critical decisions get added to the context, while removing the noise.
The difference (a must-know):
/compact: summarize and continue, for tasks that require a lighter context./clear: full reset with handoff file, for tasks that require switching or starting fresh.
Bottom line: Don't treat /clear it as a reset button. Treat it as context garbage collection. Use /compact for garbage collection mid-flight with instructions.
4. Keep CLAUDE.md minimal
Most people overload CLAUDE.md. They add architecture notes, deployment steps, PR rules, debugging checklists, style guides, testing philosophy, and random project history.
That feels organized, but it silently burns context every session.
My rule:
If Claude does not need it in 80% of sessions, it does not belong in
CLAUDE.md.
My CLAUDE.md only includes:
- package manager
- test command
- build command
- repo layout
- core architecture constraints
- forbidden patterns
- naming conventionsEverything else goes into skills or separate docs folder.
Example:
.claude/skills/db-migration/SKILL.md
.claude/skills/pr-review/SKILL.md
.claude/skills/prod-debugging/SKILL.mdBottom Line: Keep the base context light. loads the long workflow only when it's needed, keeping context quality intact.
5. Use plan mode before touching any code
Most context waste happens because Claude jumps straight into implementation without a clear plan.
It reads files speculatively, tries an approach, backtracks, and reads more files. By the time it reaches a working solution, the session is already polluted with failed attempts.
Plan mode separates thinking from doing by restricting access to the write-and-modify tool.
I press Shift+Tab twice before doing anything non-trivial
Shift+Tab → plan mode onIn plan mode, Claude reads files and reasons through the problem without making any changes. I let it map dependencies and surface unknowns.
Then I press Ctrl+G to open and edit the plan directly before Claude writes a single line of code.
Bad prompt (no plan):
Add Google OAuth to the login system.Better workflow:
[plan mode on]
I want to add Google OAuth. What files need to change?
What is the session flow? Create a plan.
[review plan, edit if needed][plan mode off]
Now implement from the plan.Bottom line: Claude solving the right problem the first time is always cheaper than rework. Let it plan, verify, and then execute.
6. Use bounded subagents for noisy exploration
Subagents are useful, but only when tightly controlled, as they tend to wander off.
I don't prompt:
Investigate the repo.I prompt:
Inspect only src/auth and tests/auth.
Return max 15 bullets.
Include exact files.
No implementation.
No broad repo scan.In general, I use Claude subagents for noisy work, such as log analysis, test failure inspection, dependency search, doc lookup, and blast radius analysis.
This multi-agent collaboration yields a cleaner workflow than a single-agent approach.
Bottom Line: The main Claude session should not carry all the exploration. It should only receive the compressed result from each agent.
7. Force surgical repo navigation
I don't ask Claude to "understand the codebase and explain it to me."
That usually causes broad scanning of wrong files, leading to unnecessary context usage, not to mention agents creating docs in the native repo (recent times)
Instead, I create a docs/repo_map.md with:
- main entrypoints
- key modules
- test commands
- auth/data/payment flows
- generated folders to avoid
- files Claude should read firstand then prompt accordingly. Here is an example of what I mean.
Bad prompt:
Understand the auth system and fix the bug.Better prompt:
Find the login entrypoint. Read only the files needed to explain token validation. Do not scan unrelated directories.This saves a lot of tokens because Claude starts from a map instead of wandering through the repo and figuring the repo out.
Bottom line: Repo Maps leads to fewer incorrect file reads, reducing context usage.
8. Lean on skills and plugins for progressive disclosure
Pulling stuff out of CLAUDE.md only helps if the place you move it to isn't also loaded every session. That is exactly what skills are for.
A skill is just a folder with a SKILL.md (a short name + description, then instructions, plus any reference files or scripts). The win is how it loads: at session start, Claude only sees the name and description of each Claude skill, roughly 30 to 100 tokens each.
The full SKILL.md body loads only when Claude decides the skill is relevant, and any bundled reference files or scripts load only if they're actually needed.
So I can keep deep workflows around without paying for them upfront:
.claude/skills/db-migration/SKILL.md
.claude/skills/pr-review/SKILL.md
.claude/skills/prod-debugging/SKILL.mdEight of these, sitting in the project, might cost a few hundred tokens at startup, instead of dumping thousands of lines into context before any work begins.
The description is doing all the heavy lifting here, so I write it specifically. "Helps with documents" never triggers. "Use when filling PDF forms and extracting table data" does.
Plugins are the next layer up. A Claude plugin bundles skills, slash commands, subagents, hooks, and MCP servers into one installable unit, and you enable or disable the whole bundle on demand:
/plugin marketplace add <marketplace>
/plugin add <plugin>The point is the same as everything else in this post: keep dormant capability out of the active context. Install the plugin when a project needs it, disable it when it doesn't, and you never carry tooling you aren't using.
Bad setup:
Everything stuffed into CLAUDE.md so it's "always available."
Better setup:
Tiny CLAUDE.md. Long workflows as skills with sharp descriptions. Capability sets as plugins you toggle per project.
9. Using Composio MCP and CLI
One of the top bottlenecks for me with the introduction of MCP was managing 30+ MCP integrations. Use fewer MCP servers, and the work won't be done. Use more, and it will add to the context memory.
Composio solved this for me by offering a universal MCP server that plugs into any MCP-supported agents and lets them connect to 1000+ services and tools, with on-demand tool loading, a remote workbench for composing tools, and a bash tool for handling edge cases with scripting.
Here is a brief breakdown of token savings with Composio MCP and without it for tasks that use tools such as Linear, GitHub, Sentry, Supabase, and Context7.
Without Composio MCP
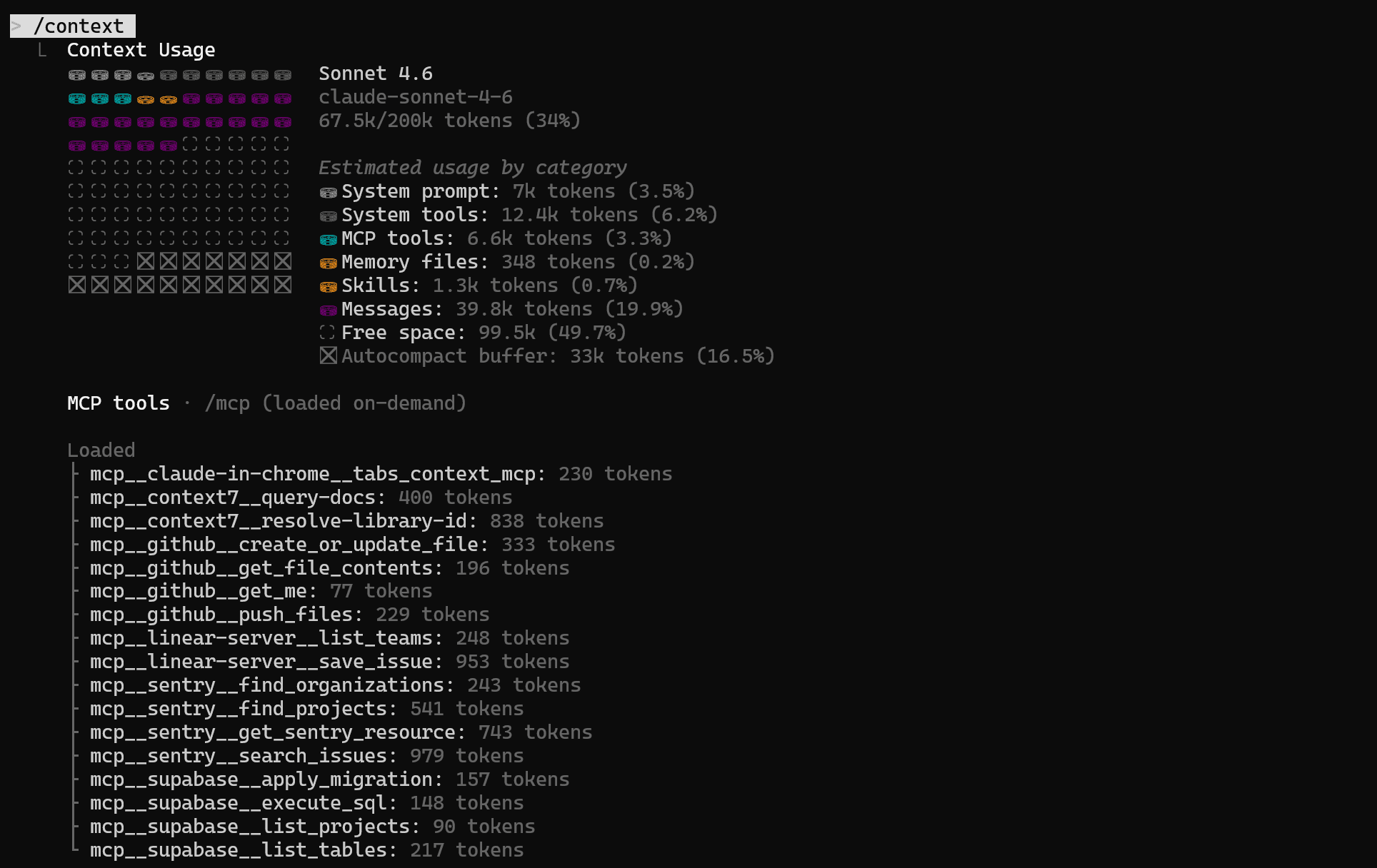
The cost of a workflow without Composio MCP
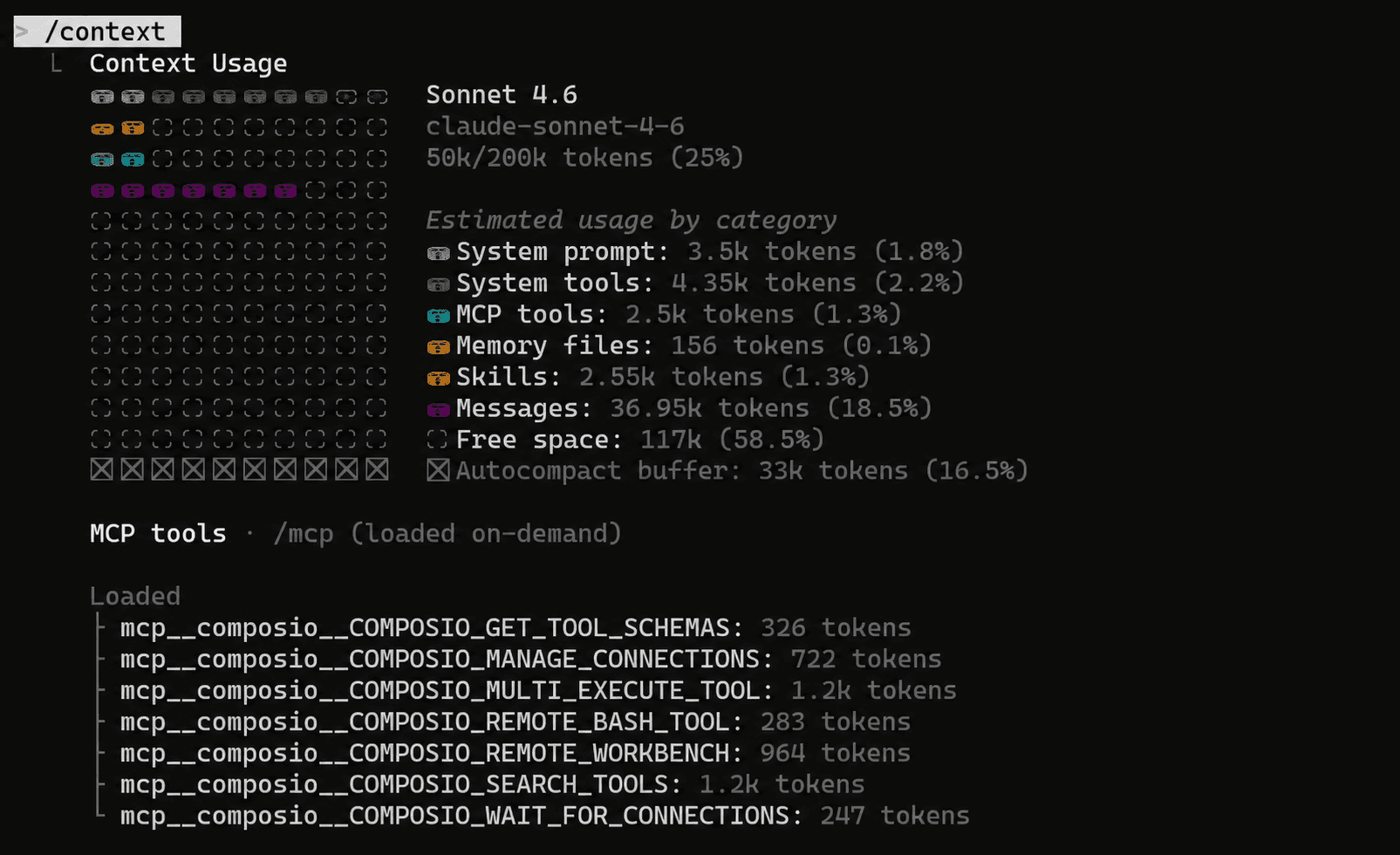
is that Composio uses fewer tokens than the raw approach. It uses only seven meta tools and gets you the best bang for the buck.
When I need even more reduction on top of that, I use the Composio CLI directly.
LLMs understand and parse shell commands better than tool schemas, they can be combined with multiple commands (composable), and has less to and from between servers and the LLM. It’s faster.
Here is an honest comparison.
With MCP
With CLI
My rule: I start with Composio MCP to consolidate integrations, then move to CLI when the task is simple enough for a shell command.
Bottom line: Active MCP is added as a context tax that compounds across every chat. Every active tool adds overhead to the schema, description, and result. So use fewer, smarter integrations, not more.
My actual Claude Code workflow
If I were setting this up for daily development, my stack would look like this (in no particular order):
Start with tiny
CLAUDE.mdKeep long workflows in
skillsUse
repo-map.mdfor navigationUse
cc-test/cc-log/cc-diffwrappersUse Composio MCP to consolidate integrations, and CLI when a shell command will do
Use subagents for exploration, the Haiku model for agents
Write
handoff.mdbefore clearing contextEnter plan mode before any non-trivial implementation
/compact with explicit preservation instructions at task boundaries
/clear aggressively between unrelated tasks
Switch to Opus only for deep reasoning, back to Sonnet after
Keep the main thread clean
The real mindset shift for you is this:
Claude Code works best when you treat it like a powerful engineer with limited working memory.
Don't dump everything on it. Don't make it read garbage. Don't let old context pile up. Give it the right files, the right errors, the right constraints, and a clean session.
That is where token savings actually come from. Perform better harness engineering.