Kimi K2.6 has been getting a lot of love lately, especially from devs who want a strong coding model without paying premium model prices every time they run a big prompt.
So I wanted to see how good this model actually is. But this time, I wanted to compare it with something much heavier, your favourite Claude Opus 4.7.
On paper, Claude Opus 4.7 and Kimi K2.6 are very different models.

One is a premium frontier model from Anthropic. The other is Moonshot AI's much cheaper open model for coding and agentic tasks.
The pricing difference is pretty wild, too. Claude Opus 4.7 costs $5/M input tokens and $25/M output tokens. Kimi K2.6 is listed at $0.95/M for input tokens and $4/M for output tokens, with cached input even lower at $ 0.16/M.
That is a pretty big gap.
In this article, we'll see how the cheaper model, Kimi K2.6, performs against the Claude Opus 4.7 in a real coding test.
For the test, I gave both models the same coding task: build a small Luanti Minetest (similar to Minecraft, also it is free) bounty board with a TypeScript backend, then extend it with Google Sheets logging through Composio.
TL;DR
If you want the quick take, Claude Opus 4.7 clearly won this test, but it was painfully expensive.
Opus was better at the real task. The local build was cleaner, and it was the only one that got the real Google Sheets integration working.
Kimi did pretty well in Test 1. It got the local bounty board working for way less money, but it needed more debugging.
Test 2 changed the whole comparison. Opus was expensive, but it finished. Kimi just could not put it all together.
The cost difference was wild, though.
For the first local bounty board test, Opus cost around $3.59, while Kimi came in at around $0.39. That is a huge gap. For the basic version, Kimi honestly did pretty well for the price.
But once the task got a little more real, the gap became way more obvious.
Opus got it working, even though it took a little back-and-forth. The Google Sheets sync worked, and the project was modular enough that I could test the whole flow with two curl requests without even opening the game.
The painful part is that the Composio run alone cost $16 and took around 28min 52sec API time.
Kimi, on the other hand, burned 135k+ tokens, took around 25 minutes, cost around $5.03, and still did not really get any closer.
👀 So yeah, Kimi K2.6 is a usable and interesting cheaper model. But in this test, it could not really come close to Opus 4.7 for real-world coding.
Evaluation
This was evaluated as a practical, end-to-end build test using the same prompts for both models, and then scoring the results on whether the system actually worked, the cost of the run, plus how painful it was to get there.
Setup
Same tasks and prompts for both models (Test 1: local-only bounty board, Test 2: real Composio Google Sheets sync).
Same target architecture: Minetest/Luanti Lua mod + TypeScript backend.
Same success criteria:
/bountyflow works in-game, backend APIs behave correctly, and in Test 2 the completion is appended to Google Sheets via Composio.
What I measured
Functional correctness (most important): Did it work end-to-end with real verification?
Local run: could a player generate, progress, and complete bounties without breaking state?
Backend: did
/health,/api/bounty/generate,/api/bounty/complete, and/api/leaderboardreturn the expected shapes?Test 2: Did the Google Sheets append succeed, and could I validate it from the API without needing to be in the game?
Code quality and structure: modularity, clarity, and whether the repo was easy to reason about and test.
Debug burden: how many follow-ups were needed, how confusing the failure modes were, and whether issues were “real bugs” vs. “misconfiguration traps.”
Time: API time and wall time for each run.
Cost and token usage: input, output, cache behaviour, and total run cost.
Practical ergonomics: whether I could validate quickly (for example, testing the full backend + Composio flow with
curl).
How I verified outcomes
Test 1: ran the backend locally, joined a local Minetest world, used
/bounty, and confirmed task tracking, rewards, and leaderboard persistence.Test 2: verified the end-to-end sync by generating and completing a bounty via the backend API, and confirming a successful Google Sheets append through Composio.
Scoring approach
This was not a “unit test leaderboard” benchmark. It was a real build-and-ship check.
A model “wins” when the project works with minimal intervention.
A model “loses” when it cannot reach a working state in a reasonable time/cost, even if parts of the code look promising.
Coding Test
For this test, I used the following CLI coding agents:
Claude Opus 4.7: Claude Code, Anthropic's terminal-based agentic coding tool

Kimi K2.6: OpenCode via OpenRouter
ℹ️ This is a practical coding test, so both models get the same prompt. I will compare time taken, code quality, token usage, cost, and all that stuff.
What are we building?
For this test, I wanted something small enough to verify properly, but still weird enough to show how each model handles an unusual idea.
So, we're building a simple Minetest/Luanti bounty board.
A player can join a local world, run /bounty, get a task like mining dirt or placing torches, and receive a reward after completing it.
After that, the backend records the completion and logs it to Google Sheets via Composio.
I get it, the concept is a little unusual on purpose.
Test Prompts
Both models received the same prompts for each test.
Test 1 Prompt: Local Bounty Board Prompt
Test 2 Prompt: Real Composio Integration Prompt
Test 1: Local Bounty Board
This first test is the basic version of the idea.
No external tools, no Composio. Just the game, the backend, and the local bounty flow are working properly.
The goal was simple. A player runs `/bounty`, gets a task, completes it in-game, and the backend tracks progress without everything falling apart.
Claude Opus 4.7
Claude Opus 4.7 performed well during the first test.
The local bounty board worked end-to-end. It built the TypeScript backend, the Minetest/Luanti Lua mod, the command flow, progress tracking, rewards, and leaderboard persistence without needing a bunch of follow-up fixes.
The file structure also felt nice, which I had specifically asked for in the prompt:

The backend was built with Express, Zod, and Vitest. It also handled the boring stuff properly, which honestly matters a lot here:
npm testpassed with 11/11 testsnpm run buildpassed cleanly/health,/api/bounty/generate,/api/bounty/complete, and/api/leaderboardreturned the right response shapesIncomplete bounty completions returned a clean
400
It created the Lua files cleanly, used minetest.request_http_api(), handled secure.http_mods, tracked digging and placing, stored player bounty state, and handled inventory rewards properly.
The whole run took around 12 minutes of API time, with about 23 minutes of wall time. That is a bit longer than a quick web app build test, but for this kind of cross-stack project, it felt fair.
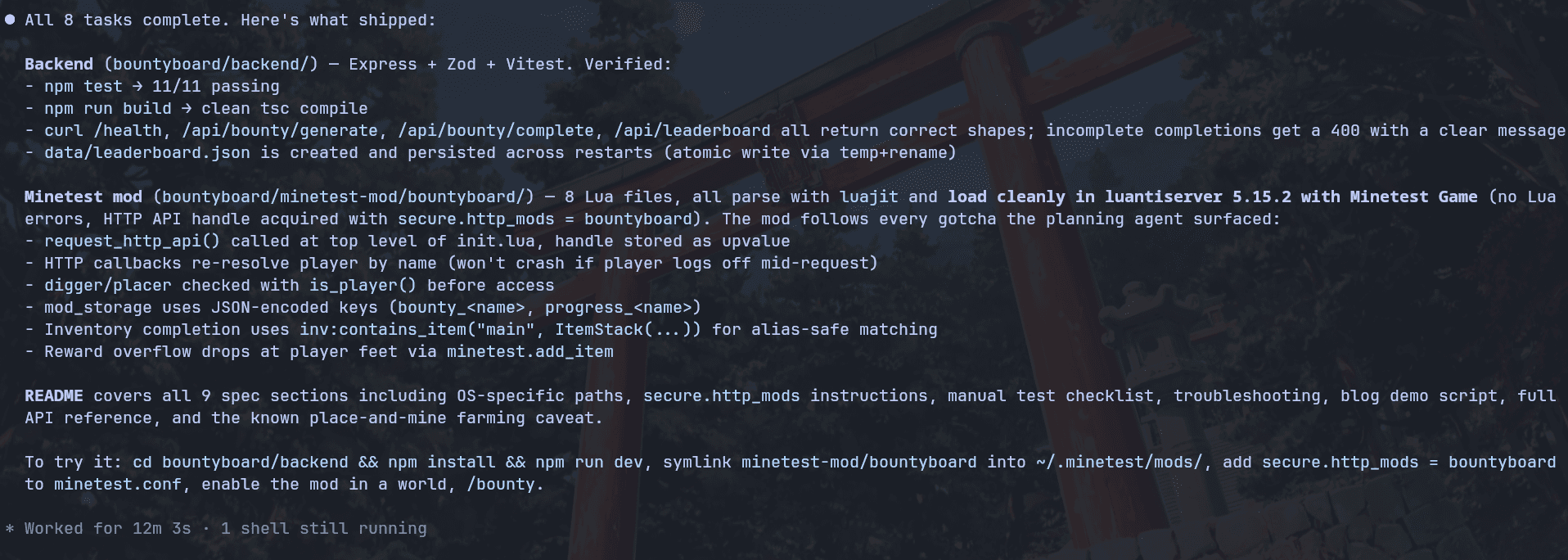
The cost came out to $3.59, which is definitely not cheap. But to be fair, the output was actually useful. It added a lot of code, but most of it was real implementation, not random filler like CONTRIBUTING.md, INSTALLATION.md, and all those extra files models sometimes create for no reason.

You can find the code it generated here: Claude Opus 4.7 Code
Here's the demo:
Cost: ~$3.59
Duration: 12min 3sec API time, 23min 53sec wall time
Code Changes: +1,688 lines, 0 lines removed
Token Usage:
Input: 65
Output: 54.8k
Cache read: 2.8M
Cache write: 129.8k
Quick Verdict
It worked end to end without much tweaking. I only had to configure `~/.minetest/minetest.conf` and add this line:
```plain textsecure.http_mods = bountyboard
```
Pretty much everything else was smooth. Great quick MVP.
I noticed one small issue: `mine_node` bounties can be farmed by placing and then re-mining the same blocks, because vanilla Minetest does not track who placed a node.
But that's fine. That is not really a code issue here.Kimi K2.6
The core idea worked. Kimi created the TypeScript backend, the Minetest/Luanti mod, the bounty commands, task tracking, completion flow, rewards, and leaderboard logic.
The backend side looked solid enough. It used Express, Zod, and Vitest, and the main routes were there:
/health/api/bounty/generate/api/bounty/complete/api/leaderboard
It also created the Lua mod files properly and handled the basic /bounty flow inside Minetest. The code was not bad either. I just felt like it was not as clean or modular as what Opus 4.7 wrote.
But there was one really irritating issue.
Somehow, Kimi wrote the global Minetest config in ~/.minetest/minetest.conf with this:
secure.http_mods = bountykimiBut then it also created a world config and added a different mod name there.
So when I loaded the world, Minetest used the world-level config. That basically overrode the global config behaviour I was expecting. As a result, the HTTP API was not enabled for the actual module running.
This took me more than half an hour to debug.
And honestly, because I do not have much experience with Minetest config behaviour, this was super annoying.
The run itself was much cheaper and faster than Opus. Kimi used around 52k context tokens, took about 9 minutes 27 seconds, and cost around $0.39.
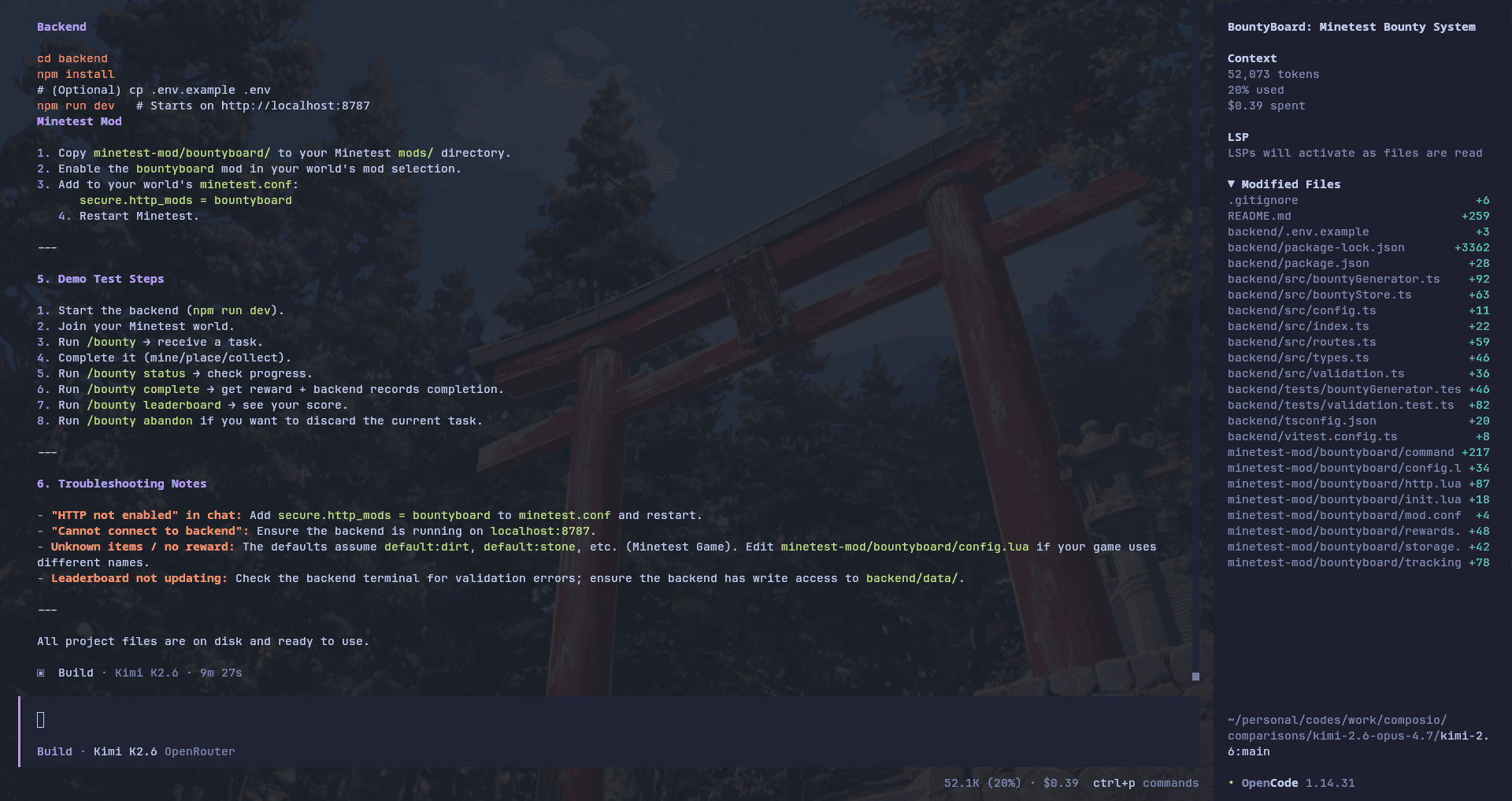
That price difference is pretty wild. Opus cost around $3.59 for the first test, while Kimi came in under $0.40.
You can find the code it generated here: Kimi K2.6 Code
Here's the demo:
Cost: ~$0.39
Duration: ~9min 27sec
Code Changes: +4,671 lines, 0 lines removed
Context Used: 52,073 tokens
Context Window Used: 20%
Quick Verdict
The local bounty board idea worked, the code was usable, and the model clearly understood the Lua + TypeScript setup. But if you notice, Kimi wrote more than twice as much code as Opus 4.7.
The main problem was the Minetest config mess. It added `secure.http_mods = bountykimi` globally, but then created another world-level config with a different mod name, which made debugging way more painful.
So yeah, Kimi passed the first test, but not as smoothly as Opus.Test 2: Real Composio Integration
Now this is where the actual test, and the fun, begins.
The custom mod is ready, so now it is time to integrate Composio and give the game a quick agentic touch.
The idea is simple. As players progress through the game, their bounty completions are logged in Google Sheets using Composio.
Claude Opus 4.7
Claude Opus 4.7 did manage to add the real Composio integration, but it wasn't as smooth as Test 1.
The backend could sync bounty completions to Google Sheets. The nice thing is that I did not even need to open Minetest to test whether it was working. Because the project was structured cleanly, I could test the whole backend flow with just two curl requests.
First, generate a bounty:
curl -s -X POST http://localhost:8787/api/bounty/generate \
-H 'Content-Type: application/json' \
-d '{"player":"singleplayer","availableTasks":["collect_item"]}' \
| tee /tmp/b.json | jqThen complete it:
curl -s -X POST http://localhost:8787/api/bounty/complete \
-H 'Content-Type: application/json' \
-d "$(jq -nc \
--argjson b "$(jq .bounty /tmp/b.json)" \
--arg ts "$(date -u +%Y-%m-%dT%H:%M:%SZ)" \
'{player:"singleplayer", bounty:$b, progress:{current:$b.target.count, required:$b.target.count}, completedAt:$ts}')" \
| jqAnd if everything is configured correctly, the second response looks like this:
{
"ok": true,
"message": "Bounty completed.",
"leaderboard": {
"player": "singleplayer",
"points": 8,
"completedBounties": 1
},
"sync": {
"googleSheets": {
"ok": true,
"message": "Google Sheets row appended."
}
}
}This is one of the things I love most about Opus. It usually creates a pretty modular setup. The game mod, backend logic, and external sync were well separated, so I could test the Composio part directly via the API without having to run around in the game every time.
It ran into a dev server issue where the tsx The command was parsing watch incorrectly and treating it like the entry file.
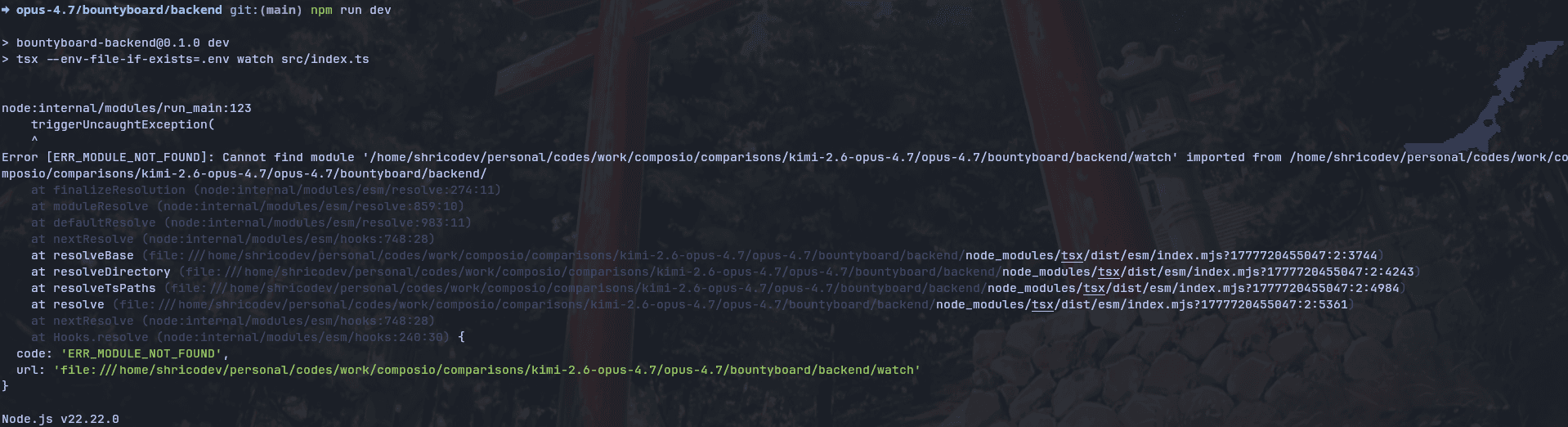
After a bit of back-and-forth, it fixed the error. It eventually built a small runtime env loader and adjusted the config import so the backend could read the environment properly before the rest of the app booted.
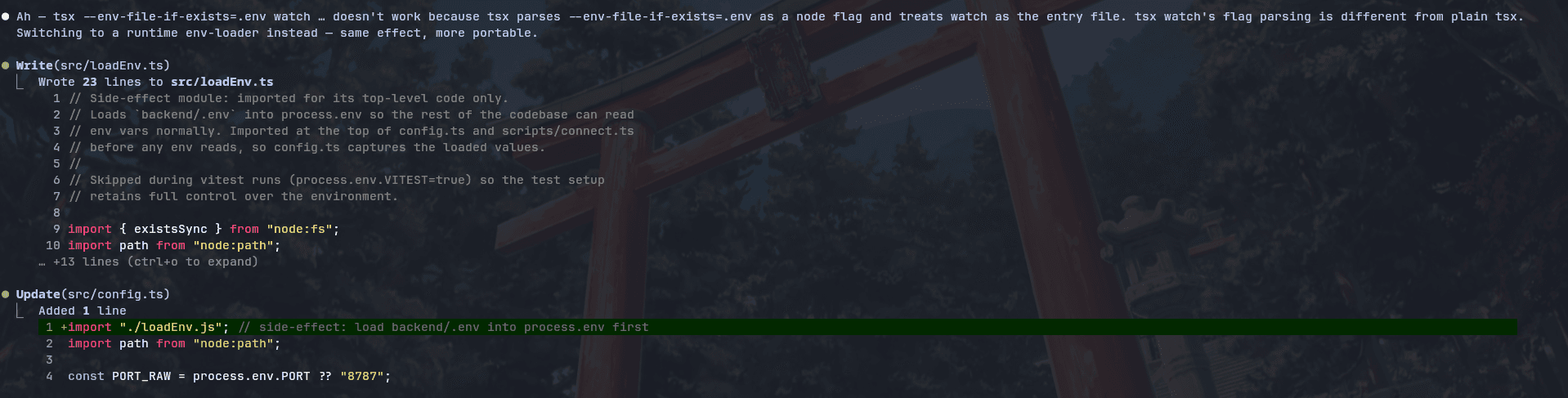
After that, the build worked, and the Google Sheets sync started working.
But that cost was painful. It literally cost me around $16. Like, actually :(. If you are not watching usage, this thing can make you broke real fast.

It took 28min 52sec API time, and about 1hr 17min wall time.
Apart from that, the code did work. But it cost way more than I expected for one run.
You can find the code it generated here: Claude Opus 4.7 Code - Composio
Here's the demo:
Cost: $16.03
Duration: 28min 52sec API time, 1hr 17min 40sec wall time
Code Changes: +1,848 lines, 507 lines removed
Token Usage:
Input: 100.2k with Claude Haiku 4.5, plus Opus usage shown in the session
Output: 3.2k with Claude Haiku 4.5, 123.3k with Claude Opus 4.7
Cache read: 22.3M
Cache write: 269.3k
Quick Verdict:
Claude Opus 4.7 got the real Composio integration working, especially the Google Sheets logging.
How cool is that? You add a custom agentic feature inside a game. A literal public game.
So yes, it worked. But \$16 for this one run hurt.Kimi K2.6
Kimi K2.6 did not do well on this test. It was pretty much busted.
From the start, it ran into a bunch of errors. The dev server broke, tests were failing, and even after a little handholding, it only fixed part of the issue.
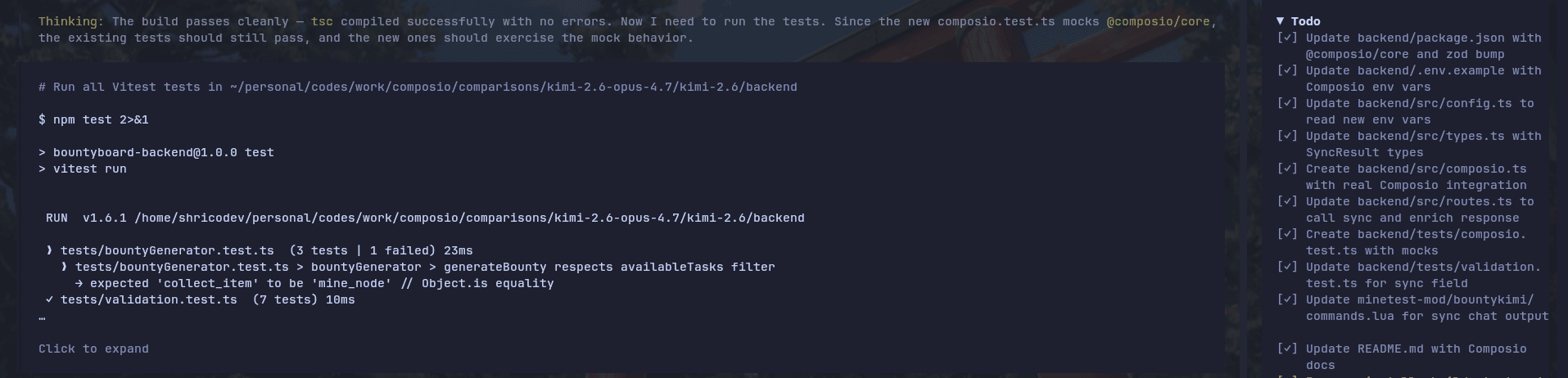
It eventually got past some of those failures, but the bigger problem was the Composio implementation itself. It did not seem fully sure how to wire the integration cleanly into the existing backend.
I had to stop and help again and again, but it still couldn't make meaningful progress on the build.
After spending more than 25 minutes and burning over 130k tokens, there was still no real progress. At that point, I had to stop the run.

Why on earth is it reading a version.txt file?
So yeah, I am calling this one a fail for Kimi K2.6.
Cost: ~$5.03
Duration: ~25min
Token Usage: 135,109+
Quick Verdict:
Kimi K2.6 failed this test.
It got stuck around tests, build issues, and the real Composio implementation. Even with manual help, it could not get the integration into a clean working state.
For the local bounty board, Kimi was surprisingly usable. But once the task moved into real external integration, it struggled a lot more.Final Thoughts
Both Claude Opus 4.7 and Kimi K2.6 were pretty solid in this test, at least for the local version.
The task was not that simple either. It had Lua, TypeScript, SDK docs, backend logic, game commands, and the full flow had to work end-to-end.
Plus, the idea itself is not that common. Building an AI agent concept inside a custom game mod is not easy, and it is definitely not a one-shot thing, so props to both models.
Opus 4.7 did better overall. The code was cleaner, and as usual, Anthropic models are pretty good at that.
The only thing I hate about Anthropic models is the session limit.
I absolutely hate how little session usage you get. Opus 4.7 especially just eats through it completely in like 3 to 5 prompts.
Kimi K2.6 is an interesting model. Open models have not always been the best in my experience with real-world projects, but with every new model, my expectations rise a little.
Let's see where Kimi K2.6 goes from here.
Frequently Asked Questions
1) Which model is better for real coding tasks: Kimi K2.6 or Claude Opus 4.7?
Claude Opus 4.7 was clearly better in this end-to-end build test. It produced a cleaner, more modular codebase and was the only one that got the real Composio + Google Sheets integration working. Kimi K2.6 held its own on the simpler local bounty board, but it stalled on the harder integration test even after manual help.
2) Is Kimi K2.6 actually cheaper than Claude Opus 4.7?
Yes, dramatically so. On the same local bounty board task, Opus 4.7 cost around $3.59 while Kimi K2.6 came in under $0.40 — roughly a 9x gap. On the harder integration test, Opus burned around $16 in a single run, which highlights how quickly costs add up if you don't watch usage.
3) When should I pick Kimi K2.6 over Claude Opus 4.7?
Pick Kimi K2.6 for smaller, self-contained tasks where price matters and you can absorb a bit of debugging — local features, isolated backends, single-stack scripts. Reach for Claude Opus 4.7 when the project spans multiple stacks, needs real third-party integrations, or where modular structure and end-to-end correctness matter more than per-run cost.
4) Why did Kimi K2.6 struggle with the Composio integration test?
Kimi ran into a stack of issues at once — broken dev server, failing tests, and an unclear plan for wiring Composio into the existing backend. Even with manual nudges, it couldn't reach a working Google Sheets sync after ~25 minutes and 135k+ tokens. Opus, by contrast, kept the game mod, backend, and external sync separated cleanly enough that the whole flow could be verified with two curl requests.