Moonshot AI released Kimi K3 on July 16, 2026, and it landed with a statement: 2.8 trillion parameters, 1 million token context, and open weights by July 27. The previous month, GLM-5.2 was released and is already in production
This proves that open-source models aren't just catching up to closed ones; they're reshaping what developers and businesses expect.
This is a comparison built for people who are building things. No benchmark chasing. No marketing narratives.
Just what each model does, where it shines, and what matters when you're shipping.
TLDR
Kimi K3: 2.8T params, 1M context, always-on reasoning, native multimodal. Best for long agent loops that need sustained reasoning and visual understanding. Frontier pricing.
GLM-5.2: 744B params (40B active via MoE), 1M context, flexible reasoning effort. Best for coding, math, and cost-efficient throughput. Open weights (MIT) available now.
Pick K3 if: agents need to reason for hours, handle images/UI, cost isn't the bottleneck.
Pick GLM-5.2 if: you want open weights today, need cheap high-volume inference, or your work leans coding/math.
Few personal builds like games, physics-driven simulation, coding, and behavioral tasks.
Bottom line: Both close the gap with closed models fast. Choice comes down to workload, not hype.
Architecture: Two Very Different Paths to Scale
Aspect | Kimi K3 | GLM-5.2 |
|---|---|---|
Total Parameters | 2.8 trillion | 744 billion total |
Active Parameters | Not yet disclosed | ~40 billion active (MoE) |
Context Window | 1 million tokens | 1 million tokens |
Key Architecture | Kimi Delta Attention (KDA) + Attention Residuals | Mixture-of-Experts (MoE) |
License | Not yet published | MIT (no regional limits) |
Release Date | July 16, 2026 | June 13, 2026 |
Kimi K3: Raw Scale Meets Long-Horizon Design with KDA
Kimi K3 is built on Kimi Delta Attention (KDA), a hybrid linear attention mechanism, and Attention Residuals. Moonshot engineered this for sustained agent workloads, not just bigger benchmarks.
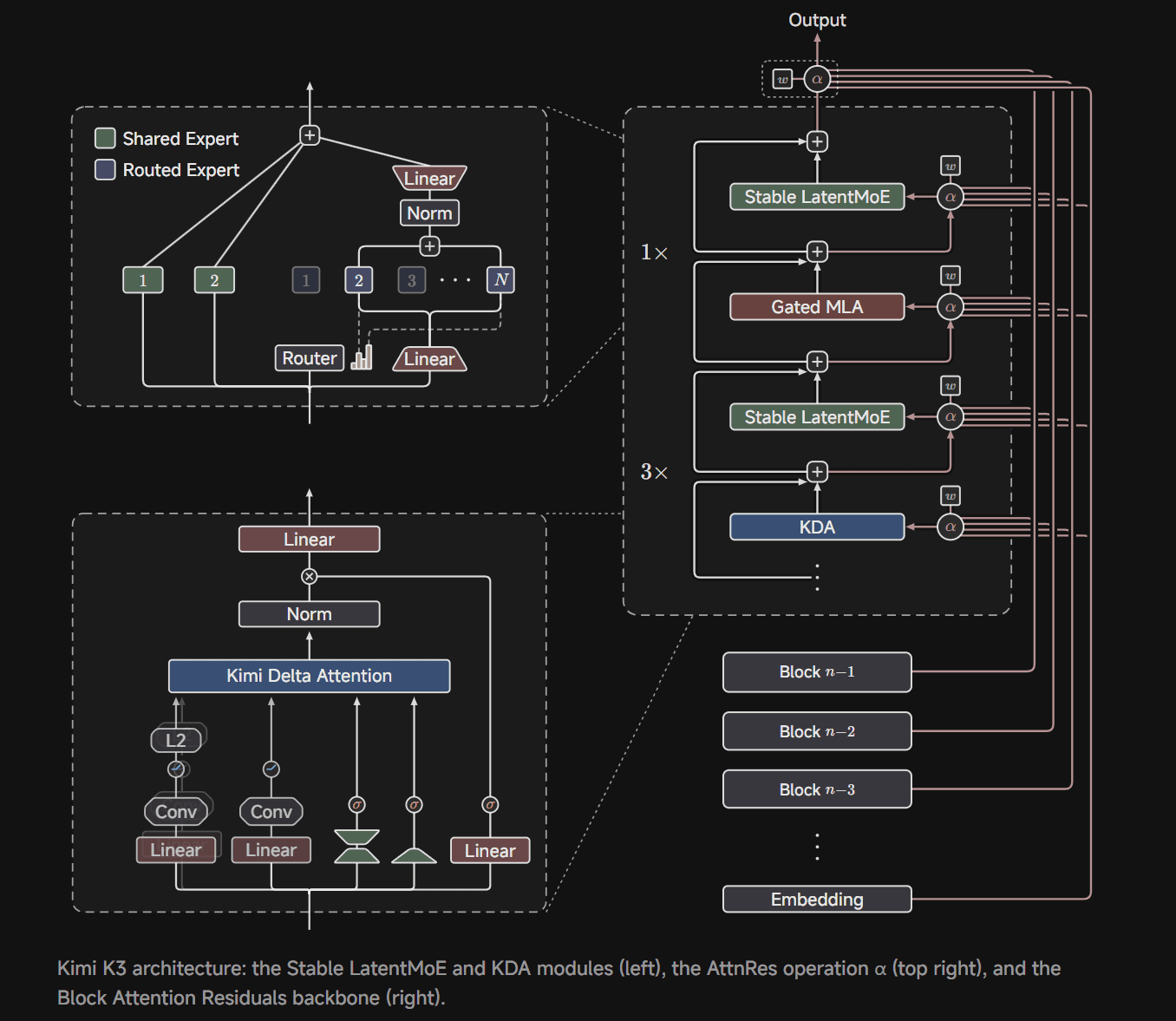
Source: https://www.kimi.com/blog/kimi-k3
The move from K2's 1 trillion parameters to K3's 2.8 trillion is deliberate. Moonshot is charging frontier rates to make the price-to-capability tradeoff hard to ignore.
You're not getting a discount model trying to go above its weight. Instead, you're getting brute-force capability with specialized attention for long reasoning chains.
Note: The full model weights will be released by July 27, 2026, but the technical report with full sparsity ratios and active parameter counts is still pending. You can build on K3 API today, but deep architectural details aren't locked in yet.
GLM-5.2: Efficiency First, Capability Everywhere with MOE & Index Share
GLM-5.2 is a 744-billion-parameter Mixture-of-Experts model with approximately 40 billion active parameters per token.
That MoE design means only a fraction of the model activates per token. This enables throughput that larger dense models can't match.

Source: https://sebastianraschka.com/blog/2026/glm-5-2-indexshare.html
The standout innovation of GLM is its IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length. For you, this means GLM-5.2 makes the 1M context practical, not theoretical.
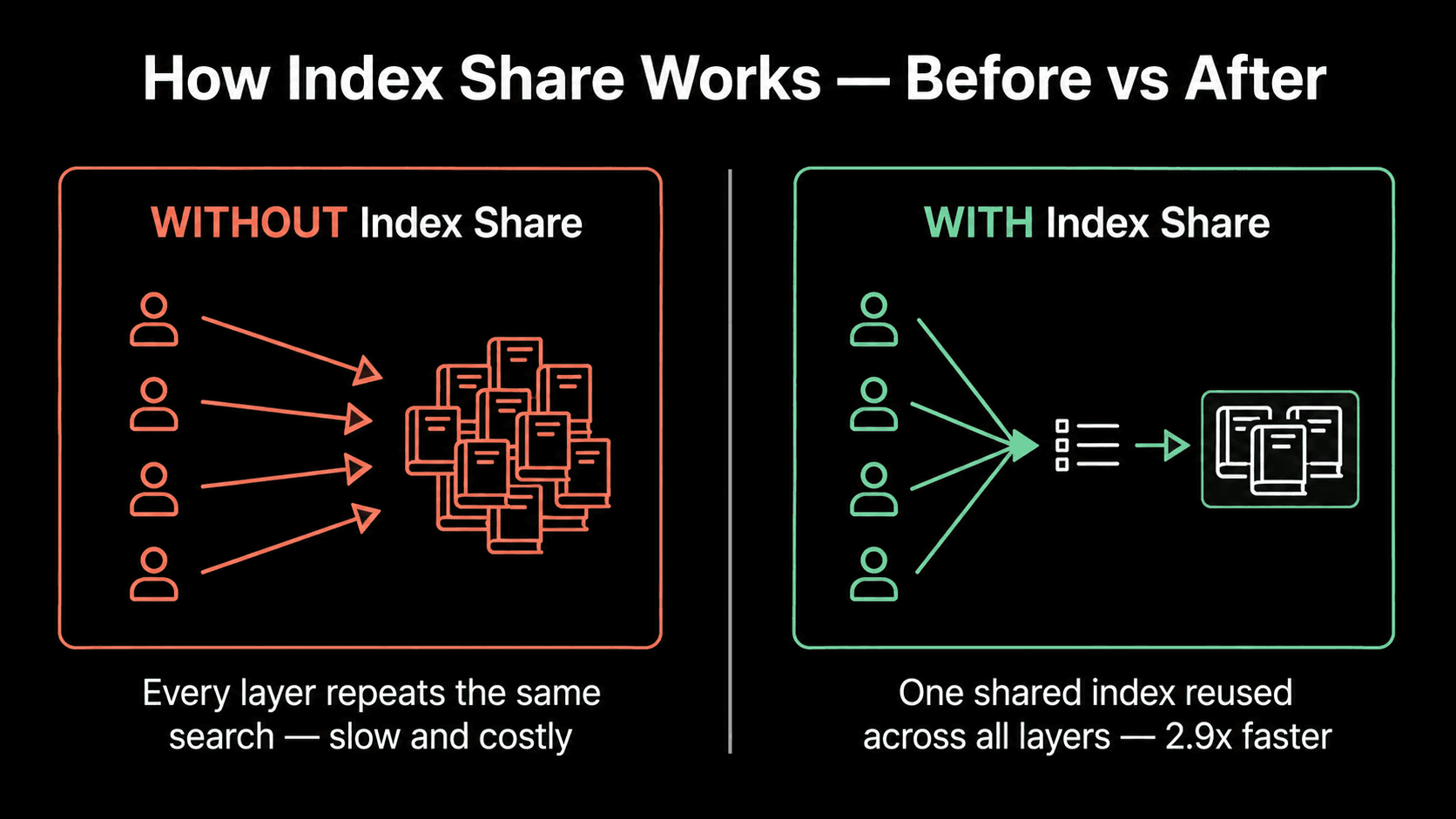
Source: Google Images
Note : GLM-5.2 is released under an unrestricted MIT license, which matters if you're deploying locally or need no-strings-attached weights. Deploy on your own hardware, fine-tune, fork with no regional restrictions.
Kimi K3 vs GLM 5.2: Composio Golden Eval
What does the bench look like?
Composio Golden Eval is a real-account benchmark for tool use. Claude Code completes multi-step SaaS tasks through Composio’s hosted MCP router, and graders verify the results by reading the final account state through APIs—not by judging transcripts.
The verifier checks actual changes, including labels, spreadsheet rows, CRM records, calendar edits, and access lists. Accounts remain safe because all writes are tagged, scoped, and removed after grading. This enables testing across live Gmail, Google Calendar, Drive, Sheets, Salesforce, HubSpot, GitHub, Linear, and Slack accounts.
The benchmark covered 12 scenarios across 24 trials. Seven were historical tasks a capable model should handle: CRM deduplication, calendar availability checks, recurring-event repair, Drive sharing audits, Gmail label batches, GitHub access audits, and GitHub–Linear reconciliation. Five were harder cross-app stress tests requiring the agent to read Gmail threads, apply exclusions, append exact Sheet rows, send individual replies, and record a final operations tally.
Passing requires an exact final state. The tasks combine reconciliation, deduplication, cross-app joins, audits, and negative constraints. Even if 90% of the result is correct, including one disqualified item causes failure. Failed runs may receive partial-credit scores such as 8/13, but the final outcome remains pass, fail, or DNF (“did not finish”).
How I ran it

I ran both models through the same 12 Golden Eval cases against the same live accounts. The readback checks were identical, with the same check names and denominators. There is one harness caveat: Kimi K3 ran under the pi agent harness, while GLM 5.2 ran under Claude Code pointed at OpenRouter. I treat the pass/fail result as a same-task, same-grader comparison, and effort numbers as harness-dependent.
Grading used real-account API readback, tag-scoped cleanup, pass/fail/dnf per trial, with partial-credit check counts on failures.
Frontier-kill task | Kimi K3 checks | GLM 5.2 checks | Kimi tool calls | GLM tool calls | Kimi runtime tokens | GLM input tokens | Kimi agent time | GLM agent time |
|---|---|---|---|---|---|---|---|---|
Invoice sync | 8/13 | 8/13 | 16 | 17 | 896,094 | 1,020,844 | 389.8s | 507.4s |
Refund ledger | 8/13 | 8/13 | 21 | 20 | 1,309,483 | 1,334,127 | 685.8s | 458.9s |
Roster sync | 8/13 | 7/13 | 13 | 19 | 609,233 | 1,058,024 | 505.1s | 418.9s |
Vendor directory | 11/13 | 11/13 | 16 | 23 | 820,613 | 1,683,579 | 788.5s | 803.7s |
Ticket sync | 17/24 | dnf | 23 | dnf | 1,745,612 | dnf | 713.5s | dnf |
Runs used the hosted Composio MCP router. Kimi ran under the pi agent harness; GLM ran under Claude Code pointed at OpenRouter. Kimi token counts are total runtime tokens (input + output); GLM's column is input tokens, with another 18K to 46K output tokens per task. Ticket sync is the one task GLM 5.2 did not finish inside the 30-minute cap.
Pass rate was flat: Kimi K3 solved 7 of 12, and GLM 5.2 solved 7 of 12. That is 58% each.
With the harness caveat above, effort favoured Kimi on several finished frontier-kill runs. On the four frontier-kill tasks both models finished, Kimi used fewer tool calls on invoice, roster, and vendor, while GLM used one fewer on refund. Kimi also finished Ticket sync in 713.5s with 23 tool calls and 1,745,612 runtime tokens; GLM hit DNF inside the 30-minute cap. Time did not point one way: GLM was faster on refund ledger and roster sync, while Kimi was faster on invoice sync and slightly faster on vendor directory.
Findings
Here is the task-for-task result on the same 12 cases.
Task | Band | Kimi K3 | GLM 5.2 |
|---|---|---|---|
CRM identity dedup | Historical | ✅ | ✅ |
Calendar free/busy | Historical | ✅ | ✅ |
Recurring instance repair | Historical | ✅ | ✅ |
Drive external-share audit | Historical | ✅ | ✅ |
Gmail label batch | Historical | ✅ | ✅ |
GitHub access audit | Historical | ✅ | ✅ |
GitHub / Linear reconciliation | Historical | ✅ | ✅ |
Invoice sync | Frontier kill | ❌ 8/13 | ❌ 8/13 |
Refund ledger | Frontier kill | ❌ 8/13 | ❌ 8/13 |
Roster sync | Frontier kill | ❌ 8/13 | ❌ 7/13 |
Ticket sync | Frontier kill | ❌ 17/24 | ❌ dnf |
Vendor directory | Frontier kill | ❌ 11/13 | ❌ 11/13 |
Solved | 7/12 | 7/12 |
Fractions on the failed rows are partial-credit verifier checks: how many graded assertions the model got right before missing the exact-final-state bar.
dnfmeans GLM 5.2 did not finish Ticket sync inside the 30-minute per-task cap, so no partial score was recorded.
Kimi K3 and GLM 5.2 both cleared the historical seven, both fell on all five frontier-kill workflows, and both ended at 7/12, 58%. The only score gap in the entire suite is one verifier check on Roster sync: Kimi got 8/13, GLM got 7/13.
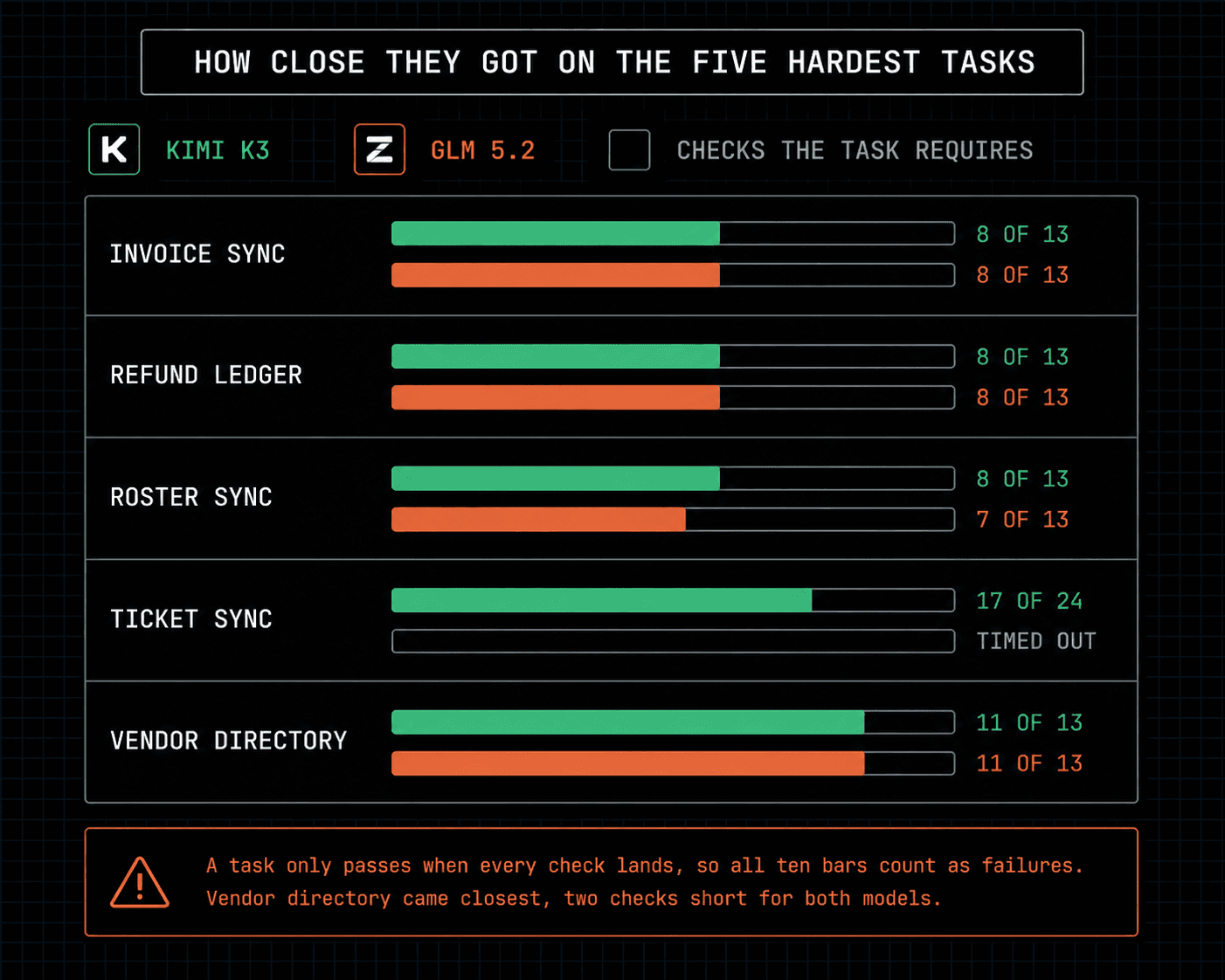
The historical band did not separate them. Both passed all seven cleanly, including CRM identity dedup, which spans Salesforce, HubSpot, and Gmail. Calendar free/busy, recurring instance repair, Drive external-share audit, Gmail label batch, GitHub access audit, and GitHub / Linear reconciliation all landed green for both models.
What it costs
I priced the finished runs from their token counts against current OpenRouter list rates, before cache discounts. The dollar amounts are estimates, but the price gap is wide enough that the direction is clear.
OpenRouter currently lists Kimi K3 at $3/M input and $15/M output. (openrouter.ai) For GLM 5.2, I used OpenRouter’s current model API rate of about $0.82/M input and $2.59/M output.
Model | Tokens on the finished frontier-kill cases | Estimated cost per case | Four-case estimate |
|---|---|---|---|
Kimi K3 | ~609K to 1.75M runtime tokens | ~$1.83 to $5.25 | ~$7.31 to $21.00 |
GLM 5.2 | ~1.02M to 1.68M input, plus 18K to 46K output | ~$0.89 to $1.50 | ~$3.55 to $6.02 |
GLM sometimes spent more tokens. Its finished cases ran ~1.02M to 1.68M input tokens, while Kimi’s runtime-token band started lower at ~609K. But Kimi’s input rate is about 3.6x GLM’s, so the extra GLM context still comes out cheaper in this estimate.
Tool calls landed in similar ranges, 13 to 23 per case for both. So the extra GLM tokens on roster and vendor work did not buy extra passes. The scores tied, with GLM carrying the cheaper bill.
At 1,000 four-case batches, that envelope turns into roughly $7.3K to $21K for Kimi and $3.6K to $6.0K for GLM before cache discounts.
Verdict
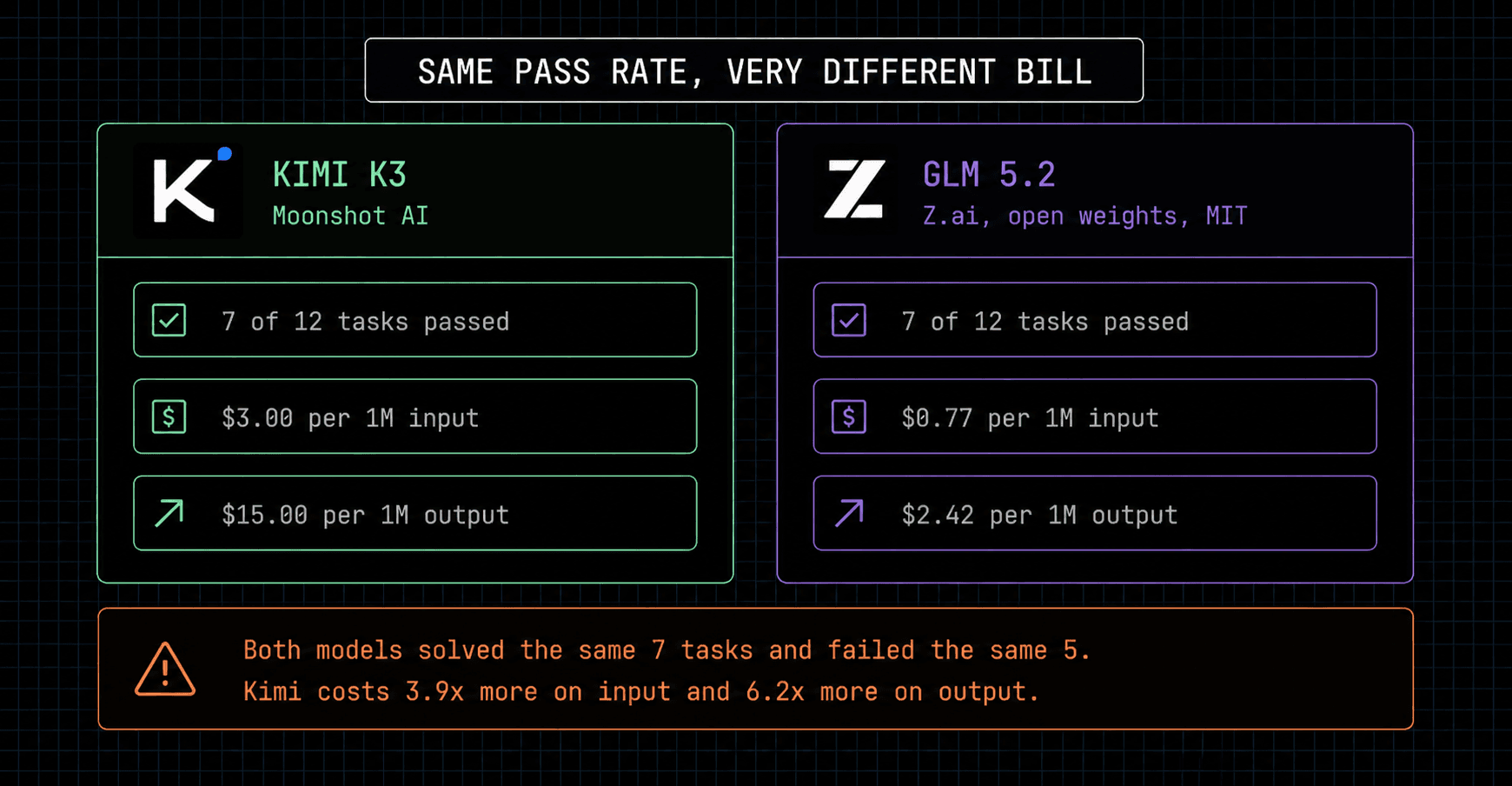
Kimi K3 and GLM 5.2 tied on pass rate, 7/12 each, 58%. I’d give the practical win to Kimi because it finished the biggest frontier case at 17/24 while GLM hit the 30-minute cap, and GLM spent more tokens on roster and vendor for the same or worse result.
I would pick Kimi K3 when finishing the long tool workflow matters more than the cheaper rate. Ticket sync shows why: Kimi got through 24 turns, posted 17/24, and burned 1.75M runtime tokens. GLM did not finish inside the 30-minute cap. On Roster sync, Kimi also scored 8/13 while GLM scored 7/13 because Kimi posted the cover replies GLM dropped. It did that with 13 tool calls and 609K runtime tokens, while GLM used 19 tool calls and 1.06M input tokens.
GLM 5.2 makes sense if your workload looks more like the easier historical band, or if you already want the Claude Code via OpenRouter setup and can live with the frontier misses. It matched Kimi’s top-line score, cleared the same 7/7 historical cases, and tied Kimi on Invoice sync, Refund ledger, and Vendor directory by score. Refund ledger is the one frontier case where GLM was cleaner on latency: 458.9s versus Kimi’s 685.8s, with both landing at 8/13.
Kimi K3 vs GLM 5.2: On personal builds
So let me share some of the builds I tried with GLM and Kimi K3, along with prompt, time, cost, and builds.
For all builds I have used open router chatroom
Meteor City (revival)
Used Kimi K3 + GLM 5.2 to build Meteor City Revival, a game where you race to destroy the entire city before it can regenerate itself.
The task was initially given to GLM 5.2, but for some reason it stopped mid-session, so I took all the code and asked Kimi to refine and recreate the entire build.
Cost was approx. $4.3, used around 18.1M Tokens, Time: 1 hr 45 min. This is justified cause without explicitly mentioning it, it generated 10K procedural buildings, the engine, and figured out the lighting, ray tracing, shaders, and optimised the game for mobile as well as web.
You can play the game at: https://meteor-city-revival.vercel.app/
Prompt used:
Create a complete, self-contained, single HTML file using Three.js (via CDN only — no other external dependencies or files) that implements a large-scale 3D photorealistic procedural meteor impact city destruction game/simulation.
**Core Gameplay (must be fully implemented and preserved exactly):**
- Procedural city with buildings that can be damaged and destroyed.
- Clickable "Launch Meteor" button that fires a meteor. User can launch multiple times.
- Buildings regenerate over time.
- **Push-and-wait mechanic**: Holding/clicking the Launch Meteor button charges a larger, more powerful meteor (powerup style).
- **Infinity powerup**: When activated, launches 5 big meteors in quick succession that deal massive damage (enough to push the destruction bar to ~95%).
- Powerups (larger meteor charge and Infinity) drop from meteor impacts and are automatically collected when the player is near them.
- Destruction progress bar that tracks overall city damage.
- At 100% destruction, display the text: "Now I am become Death, the destroyer of worlds."
- UI sliders for meteor size, speed, angle, time of day, and destruction intensity.
- Meteor and impact sounds using Web Audio API.
- Playable simulation/game with smooth performance.
**Visual & Technical Polish Requirements (focus here for realism and quality):**
- Highly realistic procedural city at night: varied building heights (low-rises to skyscrapers), realistic facades with window grids using InstancedMesh (windows have individual emissive colors that flicker or turn off when damaged), different roof styles, subtle material variation (concrete, glass, brick), minor architectural details like ledges.
- Use seed-based procedural variation so the city feels organic. Add roads, paths, and scattered green areas/parks between building clusters.
- Heavy use of InstancedMesh and LOD (Level of Detail) for performance.
- Realistic ground/terrain with subtle height variation, road networks, and support for crater formation on impact.
- Rich night sky: procedural starfield with twinkling stars, subtle moon glow, gradient sky with horizon haze and light pollution from the city. Add very subtle atmospheric effects.
- High-quality meteor: glowing fiery body with long dynamic particle trail (fire, sparks, smoke) that intensifies on entry.
- Realistic impact sequence: bright flash, expanding shockwave (particles + ground ripple), crater, layered particle systems for fire/explosions, dense rising dust/smoke plumes, and flying debris with gravity and tumbling.
- Improved building destruction: pieces break off with dust, structures partially crumble or lean, and damaged areas show reduced lighting/exposed sections.
- Dynamic lighting: moonlight + hemisphere light, multiple flickering point lights from fires and impact, emissive building windows, and fire effects. City lights progressively dim or extinguish with damage.
- Materials: Use MeshStandardMaterial where appropriate. Add subtle specular/roughness variation and rim lighting for depth.
- Special effects: Performant particle systems, screen shake on impact, bloom-like glow on bright elements, subtle motion blur during fast movement or camera fly-through, atmospheric perspective, and fog for depth.
- Overall cinematic yet realistic look with balanced night-time color grading (cool tones with warm fire accents).
**Camera, Controls & Performance Polish:**
- Smooth OrbitControls-style camera (mouse drag to orbit/pan, scroll to zoom) with optional free-fly mode (WASD + mouse look).
- Smooth camera interpolation and gentle auto-orbit when idle.
- Refined slow-motion replay with smooth timeScale control.
- Aggressive performance optimizations for stable 60+ FPS: InstancedMesh, LOD, frustum culling, efficient particle pooling, minimal draw calls.
- Subtle ambient animations (random window flickering, gentle dust movement).
**Technical Requirements:**
- Output ONLY the complete single HTML file (nothing else before or after).
- Must be immediately runnable in a modern browser with no errors.
- Include helpful inline comments explaining key visual, lighting, particle, and optimization techniques.
- Prioritize photorealistic visuals, cinematic quality, smoothness, and immersion while keeping all gameplay mechanics fully functional and unchanged.
Generate the full polished HTML code now.And the output generated by the above prompt.
Plane Currents (Win Kimi)
I always wanted to try low-poly 3D graphics, so I tried it with Kimi K3.
Use Kimi K3 to build a paper plane simulator where the player passes through rings to gather points and complete the course. All while having a relaxing scene and music going in the background. (no 3d assets)
This took around 16 minutes to generate, cost me approx $0.45, and used 30K tokens.
You can play the game by opening the game file.
Game File 📎 index.html
Prompt used
The flow I used for the prompt was simple: what I want, how it should look, give it in one single file
Build me a self contained Relaxed 3D paper-plane flying gameplay where you launch and steer a customizable plane through glowing rings and floating islands over an ocean, collecting score multipliers in short, physics-light runs with easy controls (hold to launch, mouse/keyboard steering) with stylized low-poly 3D with clean cel-shaded visuals and a sleek, colorful indie-game UI featuring customizable paper planes, glowing rings, floating islands, and simple HUD element graphics. Output a single HTML file.And the output generated by the above prompt.
Gargantua Black Hole Geodesic Ray Tracer (Complex Physics Game/Sim) - inspo from X
I was scrolling on X and found this massive black hole geodesic ray tracer simulation made by someone. Being the space nerd I am, I wanted to make this too.
So I did a bit of research and constructed a prompt that requires the model to think through the actual light-bending physics and math that happens near the event horizon of a black hole.
I was completely hopeless because fable and GLM 5.3 gave up on the calculation task early, but anyway, I entered the prompt. To my surprise, Kimi K3 actually went through the maths and solved it in its thinking traces.
After approx 14 minutes and burning through 33K tokens, which cost around $0.51 (operouter), it handed me the complete code.
I ran it, and here are the results

Prompt I used
Create a complete, self-contained single HTML file (no external libraries like Three.js) that implements a real-time geodesic raytracer for a Schwarzschild black hole inspired by Gargantua.
Use raw WebGL2 with GLSL ES 3.00 in a single fragment shader. Implement accurate physics: null geodesic integration with 4th-order Runge-Kutta solver, event horizon, photon sphere, accretion disk with proper rendering, gravitational lensing, Doppler beaming, and gravitational redshift effects. Target stable 60 FPS performance.
Include mouse-controlled camera orbiting/zooming, and a cyberpunk-style control panel with sliders for parameters (mass, spin, disk density, view angle, etc.). Add subtle particle effects for matter falling in and dynamic lighting/shadows.
The output must be 100% complete, immediately runnable in a modern browser, with no black screen, NaNs, errors, or missing features. Prioritize numerical correctness, boundary handling, solver discipline, and physical accuracy above all. Verify and comment key physics equations in the code. Make it visually stunning and interactive like a premium physics demo/game.Game File for the code: 📎 index_2.html
Yup, the code, math, and physics engine are all built by Kimi K3, and Fable failed to build the simulation with such a level of detail, which makes its claim worth the hype.
I also tried 2 more tests to verify my doubts, sharing them as a bonus.
Bonus Test 1 (Held Karp Problem Solution (NP-Hard)
It's not a surprise to me that Kimi K3 and GLM 5.2 were both able to solve this in no time, but I ran the test to check just raw coding + reasoning ability.
The task was simple: fix the bug, create an optimal path, load env, run code, and give an answer to the buggy Held-Karp problem. Yup, the task has multiple steps for testing instruction following
The test cost 0.03 cents, used 82K tokens (most on reasoning), and the result was out in 5 minutes. You can check the buggy code and fixed code from the attached files.
Game File: 📎 problem.py 📎 fixed.py
The prompt I used
Fix all bugs in the Held-Karp code in @file:problem.py so it correctly computes the minimum-cost tour for this 12-city TSP instance. Make the DP, base cases, transitions, and path reconstruction fully correct in @file:fixed.py. Then create a new environment (.env) inside @file:held-karp-problem, install the dependencies, activate the environment, and run it to output the optimal cost and the tour as a list of cities starting and ending at 0.Result

I even validated it with one of my code geek friends and Grok 4.5 (expert)

Bonus Test 2 (Behavioural Dilemma)
Models don’t just need to output code; they also need to maintain behavioural constraints, so I tested both with a behavioural question. The result was similar.
The task was simple: to resolve a conflict between team and stakeholder using the STAR Method
Prompt
Act as an experienced tech interview coach. Answer the following behavioral interview question using the STAR method (Situation, Task, Action, Result). Make the answer concise, professional, and impactful for a software engineering or tech role. Include quantifiable results where possible and highlight leadership or collaboration skills.
Question: Tell me about a time when you had to resolve a conflict within your team or with a stakeholder.Both models thought for a very short time and delivered the result in almost the same time.
Model Name | Token Count | Cost | Duration |
|---|---|---|---|
GLM 5.2 | 592 | $0.00162095856 | 25.0 s |
Kimi K3 | 763 | $0.012987 | 18.3 s |
However, Kimi K3 won as it delivered a more credible, business-aligned conflict story with quantified stakeholder impact ($200K ARR, measurable failure reduction).
A product manager and backend engineer clashed over shipping a checkout feature on deadline versus fixing payment failures (affecting 3% of transactions). The tech lead reframed both concerns as "reliable payments delivered fast," then proposed shipping the feature behind a flag while hotfixing the top failure points. The plan shipped on time, cut failures from 3% to 0.4%, retained a $200K client, and became a team standard practice.On the other hand, GLM tells a technically impressive but somewhat predictable "engineering debate resolved by benchmarking" narrative.
Two senior engineers deadlocked over GraphQL vs REST for an API redesign, stalling the team for two weeks. The tech lead ran a proof-of-concept benchmark showing GraphQL won on performance (35% payload reduction), then added REST endpoints for backward compatibility to honor both perspectives. Development resumed in 3 days; the API improved response times 30% and maintained support for 12 existing clients.Simple table for understanding
Criterion | GLM 2.5 | Kimi K3 |
|---|---|---|
Stakeholder Range | Two engineers only | PM + Engineer (broader influence) |
Business Context | Process improvement | Revenue at risk ($200K) |
Conflict Complexity | Technical disagreement | Business vs. tech risk trade-off |
Resolution Approach | Proof-of-concept (predictable) | Phased delivery + data compromise (creative) |
Lasting Impact | Team velocity restored | Process adoption + trust rebuilt + client retained |
Interviewer Appeal | Shows technical leadership | Shows business acumen + technical leadership |
This shows Kimi K3 is more aligned with the workspace and can provide factual answers when needed. Really impressive.
With this, we have come to the end of this deep dive, but here is what I have to say at the end.
Conclusion: The Gap is Closing
Six months ago, comparing open-source models to Claude and GPT meant accepting tradeoffs with performance, quality, builds, and output.
Today, models like Kimi K3 are extremely competitive across coding, agentic, and multimodal tasks.
Also, GLM-5.2 shows competitive performance across industry-standard evaluations, frequently rivalling or approaching proprietary models such as GPT-5.5 and Claude Opus 4.8.
Here is what most people are missing.
The talk is no longer about closed vs. open source; It's about specialised vs. general, and long-context practical vs. theoretical.
Both K3 and GLM-5.2 are proving that open-source can own specific workloads better than models 10x the marketing budget.
For builders:
Choose Kimi K3 if you're building agents that reason for hours, need multimodal perception, or can absorb frontier pricing.
Choose GLM-5.2 if you want open weights today, need fast inference on a GPU, or are optimising for math and code.
Either way, you're not choosing good models. You're choosing the right model for the right task, and that matters.