Introduction
Building reliable AI agents is hard, but it does not have to be. One of the critical concerns for large-scale adoption is their reliability and the difficulty of building agents that deliver in the real world. After building over a hundred integrations for AI agents and talking to many builders, we’ve realized that creating reliable AI automation takes more than just powerful large language models.
Our experiments revealed three key factors that enhance the performance of AI coding agents.
⏺ Better Tool Design for Better Performance:
Reliable coding agents need precise and efficient tools to interact with development environments, manage codebases, and implement changes accurately. Our experiment shows that tool design significantly impacts agent reliability, often the key differentiator between successful and unsuccessful implementations.
⏺ Headless IDE for security and isolation:
Instead of just tools, providing Coding agents with an IDE with code intelligence features like code completion and secure development containers can improve the agent’s performance.
⏺ Specialists over Generalists:
We achieved notable performance gains by deploying multiple specialized agents, each focused on specific tasks rather than relying on a single generalist agent.
To solve this problem, we have built SWE-Kit, a headless IDE paired with toolkits optimized for coding tasks.
SWE bench Performance and Validation
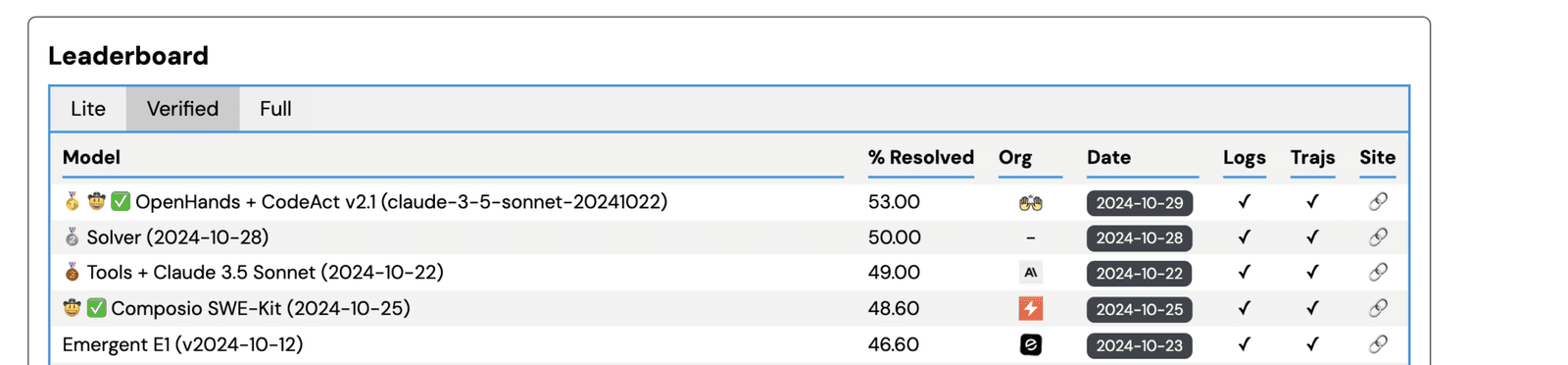
We wanted to evaluate how much of a performance gain there is with our tools and the IDE. So, we tested it on the SWE bench.
Background
SWE-bench is an industry-standard benchmark for evaluating AI coding capabilities, comprising real-world issues from prominent Python repositories, including Django, Flask, Scikit-Learn, and Matplotlib. The benchmark offers two evaluation tracks:
⏺ Verified
Is a human-validated subset of the original dataset, consisting of 500 samples reviewed by software engineers.
⏺ Lite
Is a subset of the original dataset with 300 samples.
Performance Results
We evaluated the SWE agents built using SWE-Kit on the SWE bench Verified and Lite track. Here are the outcomes.
SWE-bench Verified
Out of 500 questions, the SWE agent solved 243 with an accuracy score of 48.60%, placing fourth overall and second in the open-source category.
SWE-bench Lite
We also evaluated the SWE agent on SWE bench lite. It accurately solved 123 issues with an accuracy score of 41%, placing it in third place overall.
Agent Architecture
Our agent architecture comprises three specialized agents.
⏺ Software Engineering Agent
Orchestrates overall workflow and task execution
Uses file tools for Git repository management and patch application
⏺ Code Analyzer
Orchestrates overall workflow and task execution
Uses file tools for Git repository management and patch application
⏺ Editor
Handles file operations and code modifications
Uses File Tool for navigation and Git Patch Tool for version-controlled updates
Each component is designed for modularity and independent scaling, enabling state-of-the-art performance through specialized tools.
Implementation details
Code Context Analysis
The first step in solving a problem is understanding which parts of the repository are relevant and which files need fixing.
To address this, we developed the Code Analysis Tool. This tool systematically analyzes the codebase and uses Fully Qualified Domain Names (FQDNs) to create a structured code map, allowing the agent to efficiently locate, retrieve, and understand relevant code sections without overloading the LLM’s context.
FQDNs for Precise Code Mapping
In code analysis, an FQDN (Fully Qualified Domain Name) is a unique identifier representing a specific code element, such as a class, method, or function, by tracing its full path within the codebase. This includes its module, class, and function name, creating a fully qualified “address” for each element. For example, the FQDN for a method process_data in the class DataProcessor within the module analytics might look like this:
project.analytics.DataProcessor.process_data
This precise naming convention allows the CodeAnalysis Tool to:
⏺ Index Code Efficiently
By creating an FQDN for each identifiable element, the tool builds a searchable map of the codebase, making it easy to locate and retrieve specific components related to the issue.
⏺ Reduce Context Load
Instead of loading entire files or modules, the tool can retrieve specific code segments by their FQDNs, allowing the agent to focus on relevant code while staying within context limits.
⏺ Maintain Consistency
FQDNs ensure that each element can be uniquely identified, preventing ambiguities when referencing similar-named functions or classes in different parts of the codebase.
To extract precise FQDNs of Classes, Methods, and Variables, we use the Tree-sitter and an LSP helper built using Jedi. Once computed, FQDNs are cached for quick retrieval, enabling efficient access to detailed code information without reprocessing the codebase.
Efficient File Navigation Using File Tools
Equipping agents with file tools to navigate the repository and efficiently make necessary code changes is also essential. Like the CodeAnalysis tool, the file tool houses multiple actions necessary for file navigation, such as listing files, changing the working directory, getting the repository tree, and other essential operations for managing and interacting with code files.
These actions enable the agent to locate specific files, open and edit content, scroll through code, and create or delete files as needed. This ensures a smooth and precise workflow when addressing complex issues.
Dedicated Headless IDE for AI Agents
Instead of just coding tools, we also noticed having a headless IDE with code intelligence features improved agent performance.
This is how we ended up creating SweKit. Built on modern coding standards like development containers and Language Server Protocols (LSP), SweKit provides a robust, AI-optimized environment for coding tasks.
⏺ Isolated Dockerized Workspace
Each AI agent operates in a separate, isolated Docker environment, allowing safe and independent interaction with the codebase.
⏺ Full IDE Features
Agents benefit from IDE capabilities, such as:
Autocompletion
Code Navigation
Real-time Syntax Checking, etc.
This setup empowers agents to understand and modify the codebase accurately and efficiently, leading to faster issue resolution and improved task performance.
SWE Agent Workflow Implementation
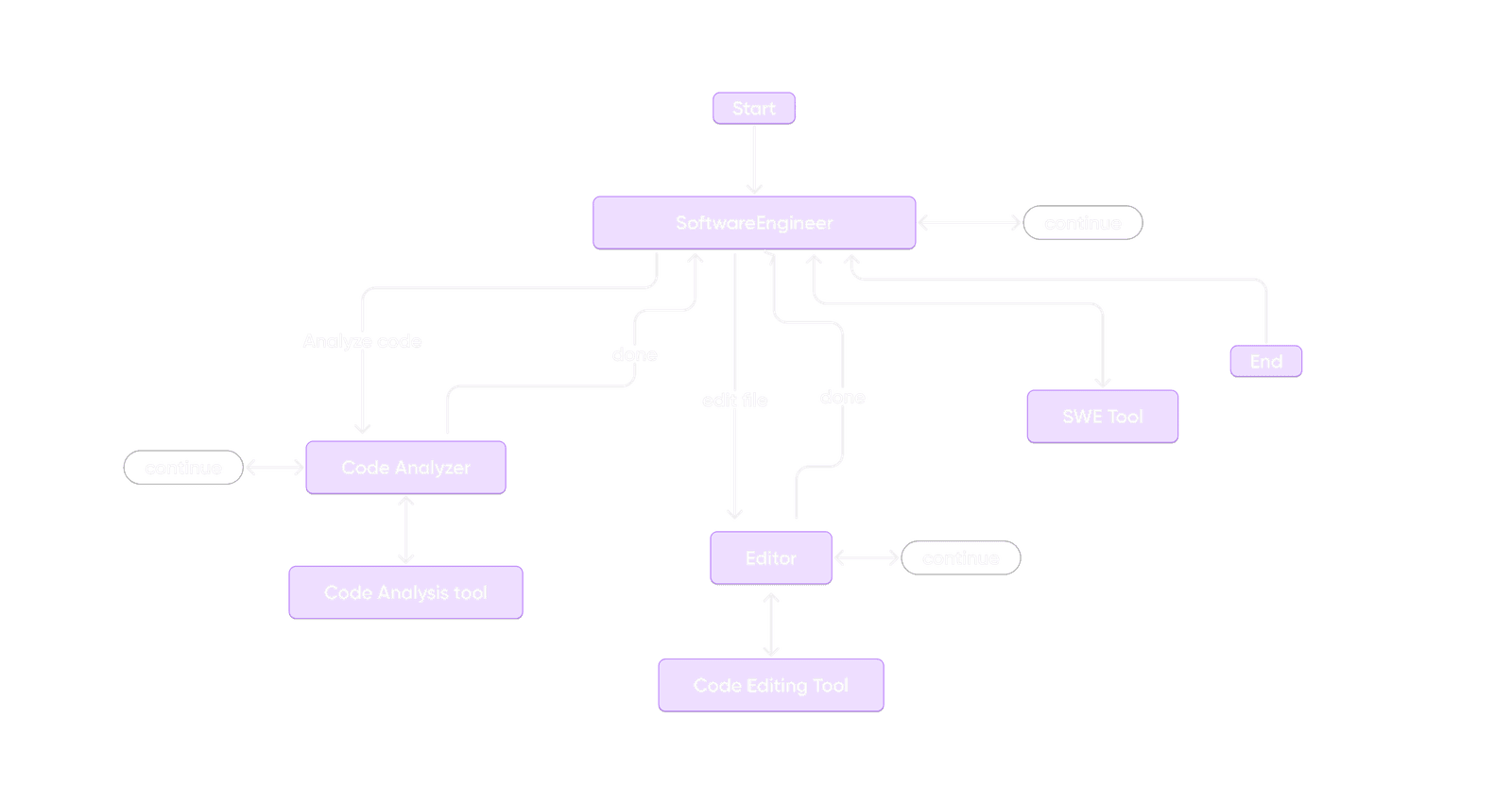
Understanding the Problem Statement
⏺ Context Gathering
The workflow begins with the Software Engineering Agent (SEA) receiving the context of the issue. It reviews the problem, scans the codebase, and forms a hypothesis for solving it.
⏺ Repository Structure Analysis
Using the File tools’ Git Repo tree action, the agent creates a repository tree to better understand the file structure and dependencies within the codebase.
⏺ Task Delegation
When deeper insights are needed, the agent transfers control to the CodeAnalyzer to retrieve and analyze specific code segments relevant to the issue.
Once the issue is identified, the SEA delegates that task to the editor agent, who will provide the relevant file and code details for the necessary edits.
The SEA takes the final call if the issues have been fixed and generates patches for changes.
Retrieving Code Based on Requirements
⏺ Targeted Code Examination
The CodeAnalyzer inspects particular files or functions, retrieving information that can assist in building a solution.
⏺ Dependency Mapping
This tool leverages CodeAnalysis tools to map dependencies and identify function calls, class hierarchies, and variable scopes related to the issue.
⏺ Returning Insights
After gathering the necessary insights, the CodeAnalyzer hands control back to the Software Engineering Agent, which refines its hypothesis or strategy using the additional information.
Editing the Files
⏺ Delegating File Operations
When code modifications are needed, the software engineering agent assigns file operations to the Editor Agent.
⏺ Executing Changes:
The Editor Agent opens relevant files, makes the required edits, and saves the changes to ensure accurate modifications.
Road Ahead
Building an AI agent is one thing; making it reliable in real-world applications is a much more significant challenge. At Composio, our mission has always been to empower developers to create robust and dependable AI automation. While our results on the SWE bench are impressive, our vision extends far beyond benchmarks. We’ve continually refined our tools to ensure they’re efficient and capable of tackling complex, real-world tasks. Beyond coding tasks, developers can leverage our tools and integrations to broaden their automation efforts across administration, CRM, HRM, social media, and more.
References
Language Models and Frameworks
Anthropic. (2024). “Claude 3.5 Sonnet” [Online documentation]_
Reference for the base LLM used in implementation_LangChain. (2024). “LangGraph: A Framework for Building Stateful Applications.” [https://python.langchain.com/docs/langgraph]
The framework used for agent orchestrationLangSmith. (2024). “LangSmith: Observability and Monitoring for LLM Applications.”
Used for system monitoring and debugging
Development Tools and Technologies
Tree-sitter Team. (2024). “Tree-sitter: A Parser Generator Tool and Incremental Parsing Library.” [https://tree-sitter.github.io/]
Used for code analysis and FQDN generationJedi Team. (2024). “Jedi – An Autocompletion and Static Analysis Library for Python.” [https://jedi.readthedocs.io/]
Used for code intelligence featuresMicrosoft. (2024). “Language Server Protocol Specification.” [https://microsoft.github.io/language-server-protocol/]
Protocol used in SweKit implementation