While everyone is occupied with the next best frontier model, the smaller models often get ignored. Yes, we are calling 32b models small language models now (My 2021 brain wouldn't be able to comprehend this).
You can effectively run these models in your local setup without quantizing it to the bones. A personal LLM can be helpful if you do not want to hand over personal data to BIG AI. Another upside is that smaller language models can drastically reduce your bills if you're a developer building apps.
Recently, Qwen, Mistral and Google launched QwQ 32b (a reasoning model), Mistral small 24b, and Gemma 27b (a base model). Although they have different architectures, they have scores comparable to Deepseek r1 in the Lmsys leaderboard. Gemma is even scoring more than QwQ despite being a base model.
I'm not a big fan of leaderboards, as I am still sure Deepseek r1 with 671B parameters will always be far superior in general tasks. But I'd love to see how these three compare. QwQ even has scores on par with Deepseek r1 on multiple benchmarks.
So, the base assumption here is that the models will underperform R1, and anything above that will add a point in the models' favour.
I have used the OpenRouter hosted models for this comparison. You can also compare QwQ-32b with Reka Flash.
So, let's get started.
Table of Contents
Brief on QwQ 32B Model
Brief on Gemma 27b
Brief on Mistral Small 24b
Coding Problems
Reasoning Problems
Mathematics
Final Verdict
TL;DR
QwQ overall is the best of the lot.
It leads in Coding, reasoning, and math, though has an inclination to think and talk a lot.
Gemma 3 is second, the vibes are great and solid model but with restrictive Gemma license.
Mistral small 3.1 is a good model, can go through most simple tasks but pales in comparison to QwQ.
If you were to choose a single model for local hosting QwQ 32b is the one.
When comparing these three models, the answer is not apparent if you want to jump straight to the conclusion. QwQ leads on coding sometimes better than Deepseek r.
When comparing these three models, the answer is not apparent if you want to jump straight to the conclusion. QwQ leads on coding sometimes better than Deepseek r.

If it is for coding, go with the QwQ 32B model. For anything else, Gemma 3 is equally excellent and should get your work done. Mistral is a distant third here.
Brief on QwQ 32B Model
Alibaba released this new model in the first week of March with a 32B model size, claiming it is capable of rivalling Deepseek R1, which has a 671 B model size.

This marks their initial step in scaling RL (Reinforcement Learning) to improve the model’s reasoning capabilities.
Below is the benchmark they have made public to highlight QwQ-32B’s performance compared to another leading model, Deepseek R1.
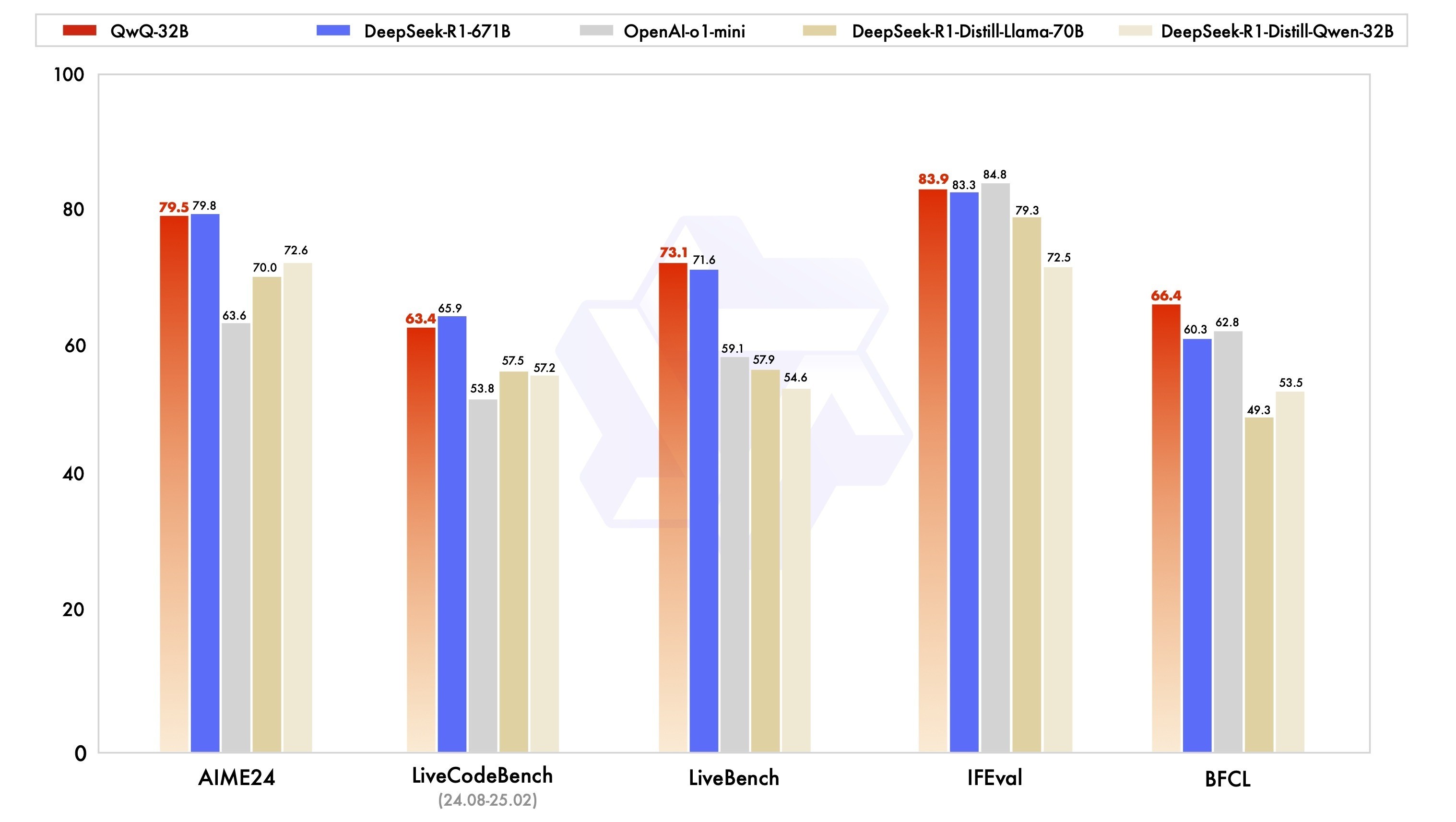
Now, this is looking a lot more interesting, especially with the comparison they have done with a model that is about 20x their size, Deepseek R1.
Brief on Gemma 3 27B Model
Gemma 3 is Google’s new open-source model based on Gemini 2.0. The model comes in 4 different sizes (1B, 4B, 12B, and 27B), but that’s not interesting.
It is said to be the “most capable model you can run on a single GPU or TPU.” This directly means that it is capable of running on resource-limited devices.
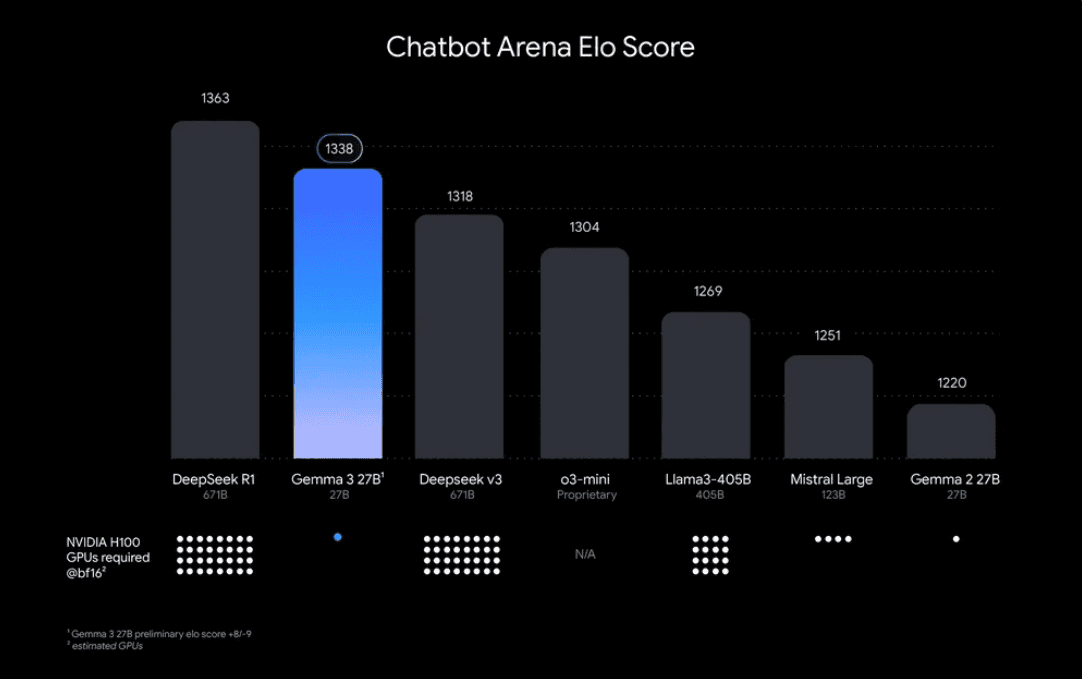
It supports a 128K context window and over 140 languages, and it’s mainly built for reasoning tasks.
Let’s see if that really is the case and how good this model is at reasoning.
Brief on Mistral Small 3.1 24B
This is the entrant from Mistral with multimodal understanding, and an expanded context window of up to 128k tokens. Mistral has also claimed to have beaten Gemma 27b and GPT-40 mini.

Coding Problems
In this section, I will test the coding capabilities of all three models on animation and a tricky LeetCode question.
1. Rotating Sphere with letters
Prompt: Create a JavaScript simulation of a rotating 3D sphere made up of letters. The closest letters should be brighter, while the ones farthest away should appear grey.
Response from QwQ 32B
You can find the code it generated here: Link
Here's the output of the program:
The output we got from QwQ is entirely insane. Everything I asked for, from the animation to the letters spinning and their colours changing. Everything is on point. So good!
Response from Gemma 3 27B
You can find the code it generated here: Link
Here's the output of the program:
It does not wholly follow my prompt. Something seemed to be happening, but I asked for a 3D sphere with a ring spinning with the alphabet.
Knowing this model isn’t good at coding, we at least got something working, though!
Response from Mistral
This was awful; it only showed a blank screen.
Response from Deepseek R1
You can find the code it generated here: Link
Here's the output of the program:
It got it mostly correct and implemented exactly what I asked for. No doubt about that, but compared to the output from the QwQ 32B model, this really does not seem to compare in terms of overall output.
Summary:
In this section, the QwQ 32B model is undoubtedly the winner. It crushed our coding tests with the animation. QwQ 32B beats Deepseek R1 here. On the other hand both Gemma and Mistral were subpar. So, one point to QwQ.
2. LeetCode Problem
For this one, let’s do a quick LeetCode check with a super hard LeetCode question to see how these models solve a tricky LeetCode question with an acceptance rate of 14.4%: Strong Password Checker.
Considering this is a tricky LeetCode question, I have little to no hope with all three models as they are not as good as some other code models like Claude 3.7.
If you want to see how Claude 3.7 compares to some top models like Grok 3 and o3-mini-high, check out this blog post:
Claude 3.7 Sonnet vs. Grok 3 vs. o3-mini-high: Coding comparison
Prompt:
A password is considered strong if the below conditions are all met:
- It has at least 6 characters and at most 20 characters.
- It contains at least one lowercase letter, at least one uppercase letter, and at least one digit.
- It does not contain three repeating characters in a row (i.e., "Baaabb0" is weak, but "Baaba0" is strong).
Given a string password, return the minimum number of steps required to make password strong. if password is already strong, return 0.
In one step, you can:
- Insert one character to password,
- Delete one character from password, or
- Replace one character of password with another character.
Example 1:
Input: password = "a"
Output: 5
Example 2:
Input: password = "aA1"
Output: 3
Example 3:
Input: password = "1337C0d3"
Output: 0
Constraints:
1 <= password.length <= 50
password consists of letters, digits, dot '.' or exclamation mark '!'.
Response from QwQ 32B
You can find the code it generated here: Link
Damn, Qwen got the answer correctly. It also wrote the entire code in O(N) time complexity, which is within the expected time complexity.
It would have been decent if I had to compare the code quality. The model documents everything adequately. So, the model has a lot of potential.
Though it took a lot of time to think, the working answer really matters here.

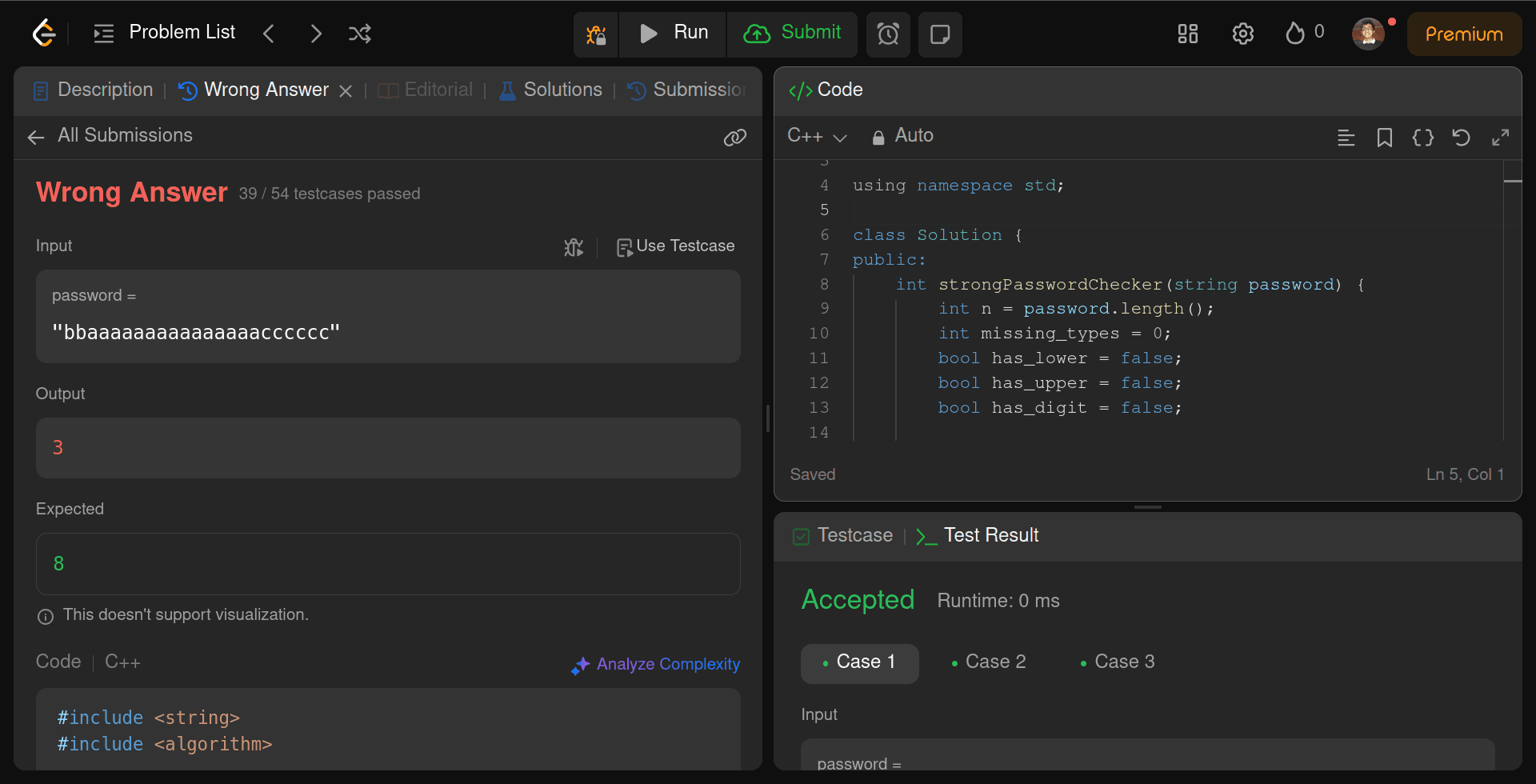
Response from Gemma 3 27B
You can find the code it generated here: Link
Okay, Gemma 3 falls short here. It got almost halfway there with 39/54 test cases passing, but such faulty code does not even help. It is better not to bother generating code than to code it poorly.
But considering this model is open-source, has just 27B parameters, and operates on a single GPU or TPU, that’s one thing we can think.
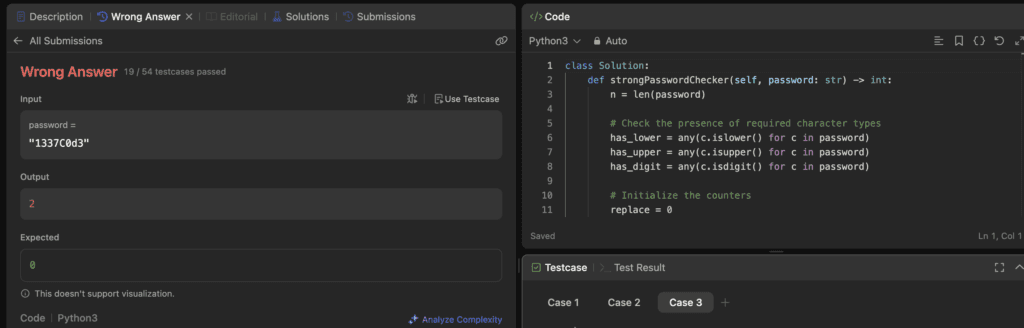
Response from Mistral
It couldn’t clear it. Got 19 test cases right.
Response from Deepseek R1
In my previous test, where I compared Deepseek R1 with Grok 3, Deepseek R1 failed pretty badly. If you’d like to take a look:
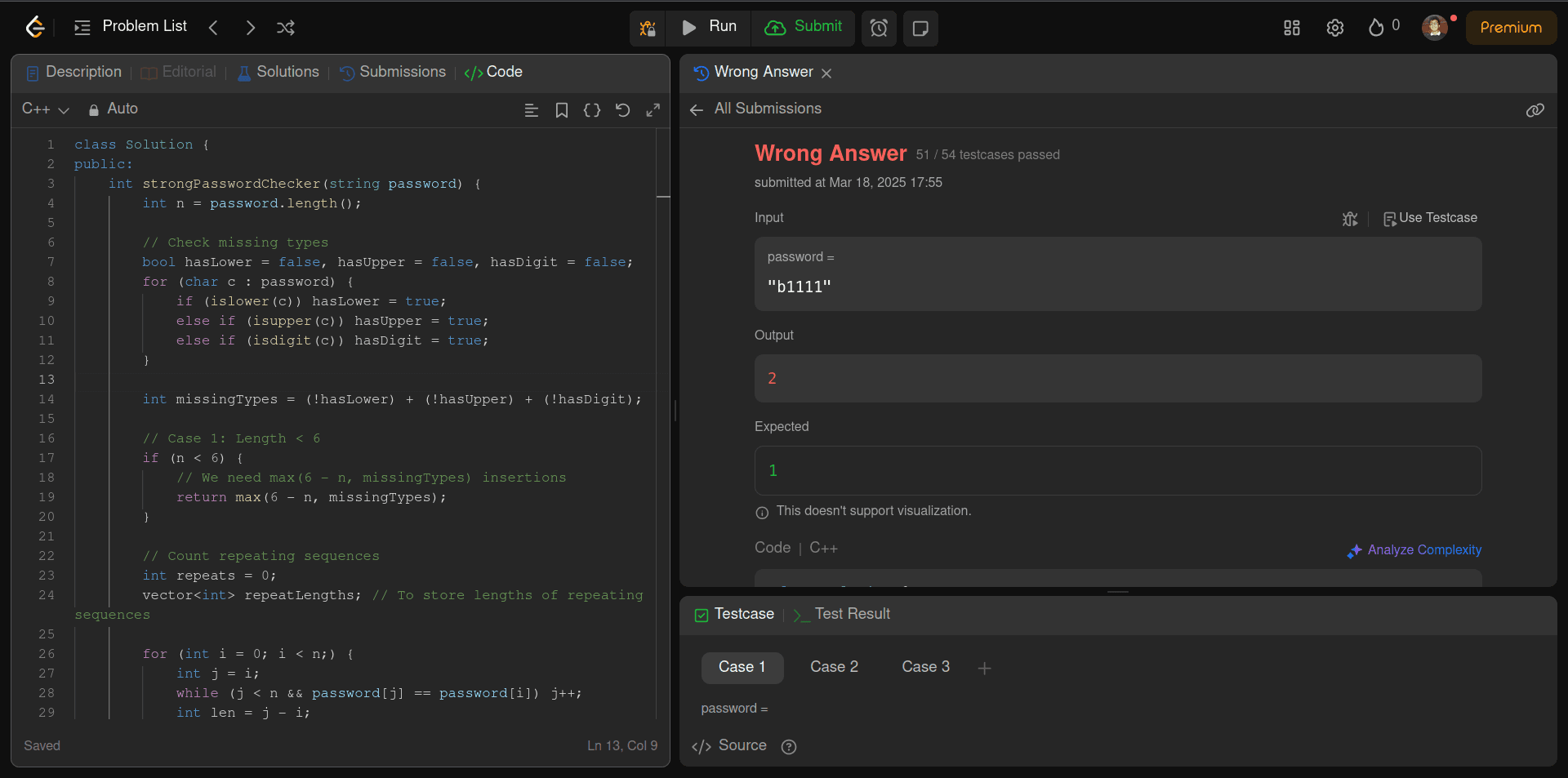
You can find the code it generated here: Link
Cool, it almost got it with 51/54 test cases passing. But even a single test case failure will result in an incorrect submission, so yeah, hard luck here for Deepseek R1.
Summary:
The result is evident when comparing these three models on two coding questions. QwQ 32B model is the winner. Gemma 3 27B did try it, but it is not something you would want to use for advanced coding. Mistral too failed, so two points for QwQ.
Reasoning Problems
Here, we will check the reasoning capabilities of both models.
1. Fruit Exchange
Let’s start with a pretty simple question (not tricky at all), which requires a bit of common sense. But let’s see if these models have it.
I wanted to test if the models can parse what is asked and reason just what is needed or deal with everything given. This is similar to asking what it is: 10000*3456*0*1234.
Prompt: You start with 14 apples. Emma takes three but gives back 2. You drop seven and pick up 4. Leo takes four and offers 5. You take one apple from Emma and trade it with Leo for 3 apples, then give those 3 to Emma, who hands you an apple and an orange. Zara takes your apple and gives you a pear. You trade the pear with Leo for an apple. Later, Zara trades an apple for an orange and swaps it with you for another apple. How many pears do you have? Answer me just what is asked.
As you can see, we provide all the unnecessary background with apples and oranges, but Pear, which is just what is asked, is at the end with one single trade, resulting in us having zero pears.
Response from QwQ 32B
You can find its reasoning here: Link

Response from Gemma 3 27B
You can find its reasoning here: Link.

It calculated all the situations and returned the total pear count in just a few seconds. I can’t complain much here.
The response was super quick; I was utterly impressed by this model.
Response from Mistral

Response from Deepseek R1
You can find its reasoning here: Link
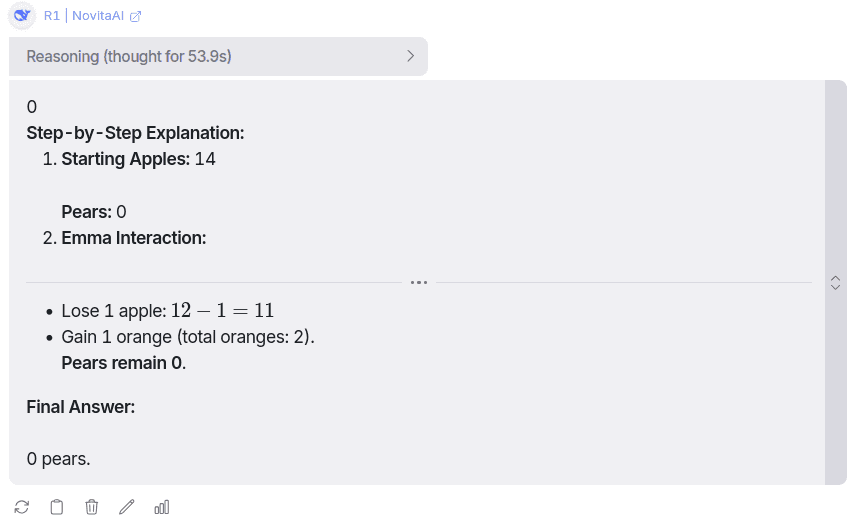
It thought for about a minute and did come up with the answer. It was expected that it would come up with the correct answer, but I just wanted to see if it could give me the answer to what I asked without doing all the unnecessary calculations with apples and oranges. Sadly, it also failed.
Summary:
With this question, I wasn’t looking for the correct answer; even a first-grader could answer it. I was trying to see if these LLMs could filter out all the unnecessary details and answer just what was asked, but sadly, all of them failed, even though I added this sentence: “Answer me just what is asked.” at the end of the prompt. So, 0 to all.
2. Women in an Elevator
Prompt: A bald, skinny woman lives on the 78th floor of an apartment. On sunny days, she takes the elevator up to the 67th floor and walks the rest. On rainy days, she takes the elevator straight up to her floor. Why does she take the elevator to her floor on rainy days?
The question is tricky as I have included similar unnecessary details to distract the LLMs from easily finding the answer. The answer is that the woman is short and can’t reach the button in the summer, but she carries an umbrella that she can use to press the elevator button higher.
The answer has nothing to do with the girl being bald or skinny.
Response from QwQ 32B
You can find its reasoning here: Link

It took a seriously long time, 311 seconds (~5.2 minutes), to figure out what that had to do with her being bald and skinny, but I am super impressed with the response.
The way it explained its thought process is imposing. You should take a look as well.
It’s fair to say that QwQ 32B really got it correct and explained everything perfectly.
Response from Gemma 3 27B
You can find its reasoning here: Link

I was shocked by Gemma 3, within a couple of seconds, it got it correct. This model looks at reasoning tasks. So far, I am super impressed with this Google open-source model.
Response from Mistral

Response from Deepseek R1
CoT here: Link

We know how good Deepseek is at reasoning tasks, so it’s not really surprising that it got the answer correct.
It took some time to come up with the answer, thinking straight for about 72 seconds (~1.2 minutes), but I love the reasoning and thought process it uses every time.
It was really having a hard time understanding what the problem had to do with the woman being bald and skinny, but hey, that’s the reason I added it.

Summary:
All the models got it right so one point to each. This wasn’t particularly very hard question.
Mathematics Problems
Looking at the reasoning questions answered by all three models, I was convinced that both of these models should also pass the math questions.
1. Clock Hands at Right Angle
Prompt: At what time between 5.30 and 6 will the hands of a clock be at right angles?
Response from QwQ 32B
Find the CoT trace here: Link

Response from Gemma 3 27B
You can find its reasoning here: Link
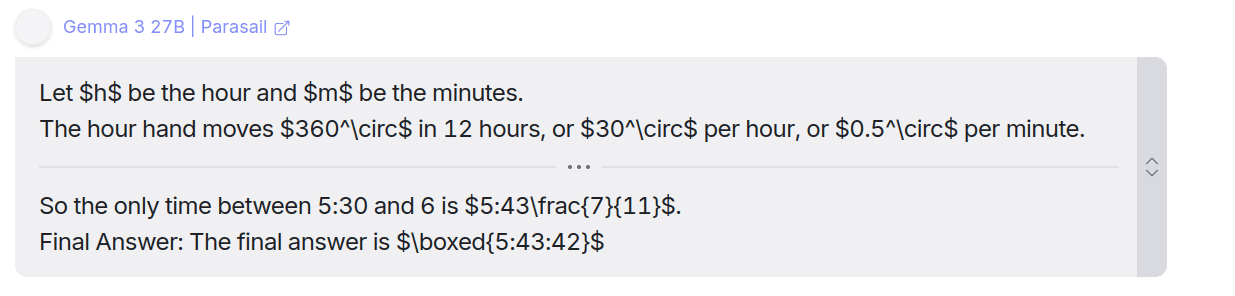
Apart from the coding questions, Gemma 3 got this one correct. What a tiny yet powerful model this is.
Response from Mistral
Close but incorrect

Response from Deepseek R1
Reasoning here: Link

I had already compared Deepseek R1 and Grok 3. It is clear how good Deepseek is at Mathematics, so I had high hopes for this model.
As usual, this question was also answered correctly. It took some time and thought, but it did.
Summary:
Gemma 3 27B does it in no time, and the other two models, QwQ 32B and Deepseek R1, crush this with proper reasoning. While Mistral failed by a bit. So, one point to all except Mistral.
2. Letter Arrangements
Prompt: How many different ways can the letters of the word ‘MATHEMATICS’ be arranged so that the vowels always come together?
It’s a classic Mathematics question for an LLM, so let’s see how these three models perform.
Response from QwQ 32B
You can find its reasoning here: Link
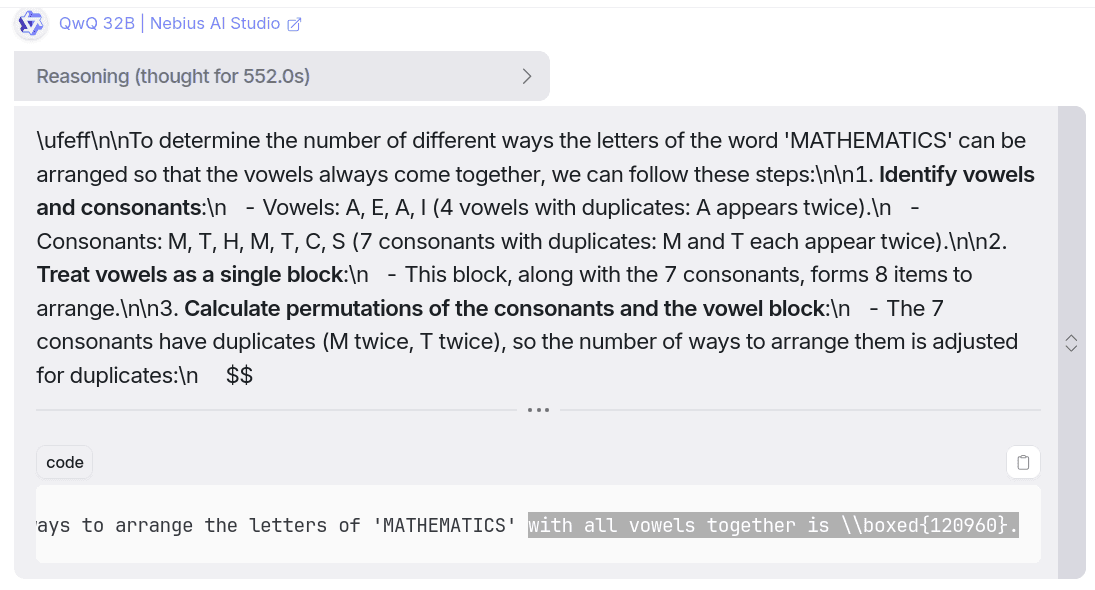
After thinking for 552 seconds (~9.2 minutes), yes, it took that long to come up with the answer, but as always, it also nailed this question.
All its reasoning feels super long and boring, but if it gets the job done, then that’s a good side to it. The QwQ 32B model looks solid and crushes all the questions.
Response from Gemma 3 27B
Reasoning trace here: Link

It was spot on. It’s amazing how quickly and accurately this model gives responses. Google did good work on this model, and there’s no doubt about that.
Response from Mistral

Response from Deepseek R1
Find its reasoning here: Link
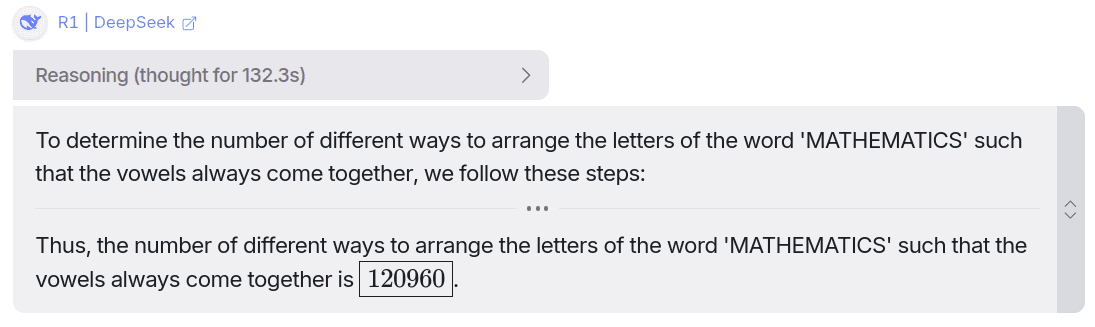
After thinking for around 132 seconds (~2.2 minutes), it came up with the correct answer,
Summary:
The answer is obvious this time as well. All three of our models got it perfectly, with perfect explanation and reasoning. For a question this tough, it’s a super impressive response to get back from all three models, but to me, Gemma 3 27B just stands out. What a lightweight, solid model. Even Mistral got it right this time. So, a point for all.
Final Verdict
The new Qwen is really impressive, so is Gemma but only problem is with the Gemma open-source license. Qwen seem to found a sweet spot between size and performance.

It will be exciting to see what they come up with next.
Gemma 3 is definitely a solid base model. They have perfected the art of distilling large models (Gemini 2.0) to smaller models like Gemma and Flash. Mistral rather felt under whelming, it didn't feel close to Qwen and Gemma.
So, what to pick?
For coding tasks, QwQ 32B is better.
For reasoning, and math again Qwen is better. But Gemma is not bad.
Gemma and Mistral small also comes with image input support, so that'a big plus.
QwQ and Mistral comes with more permissible license Apache 2.0, while Gemma has Google Gemma license, a tad bit restrictive.
So, overall QwQ 32b wins hands down, Deepseek r1 like performance in compact size.