OpenAI o3 and o4-mini are out. They are two reasoning state-of-the-art models. They’re expensive, multimodal, and super efficient at tool use. Significantly, the elder o3 has been the centre of discussion for the last five days. The model has aced multiple “independent” benchmarks, from coding to math to other STEM subjects. However, many still believe that Gemini 2.5 is the better model.
Here, we’re a bit more interested in coding workflows. How do these models fare and compare with the Gemini 2.5 (my go-to model for everything)?
So, let’s find out.
Brief on OpenAI o3 and o4-mini
O3 leads on most benchmarks, beating Gemini 2.5 and Claude 3.7 Sonnet.
On the Aider polyglot coding benchmark, the model has set the new state-of-the-art with 79.60%, while Gemini 2.5 scored 72.90%. However, a 7% increase would cost 18 times more. O4-mini has scored 72% while costing 3x more than Gemini 2.5.
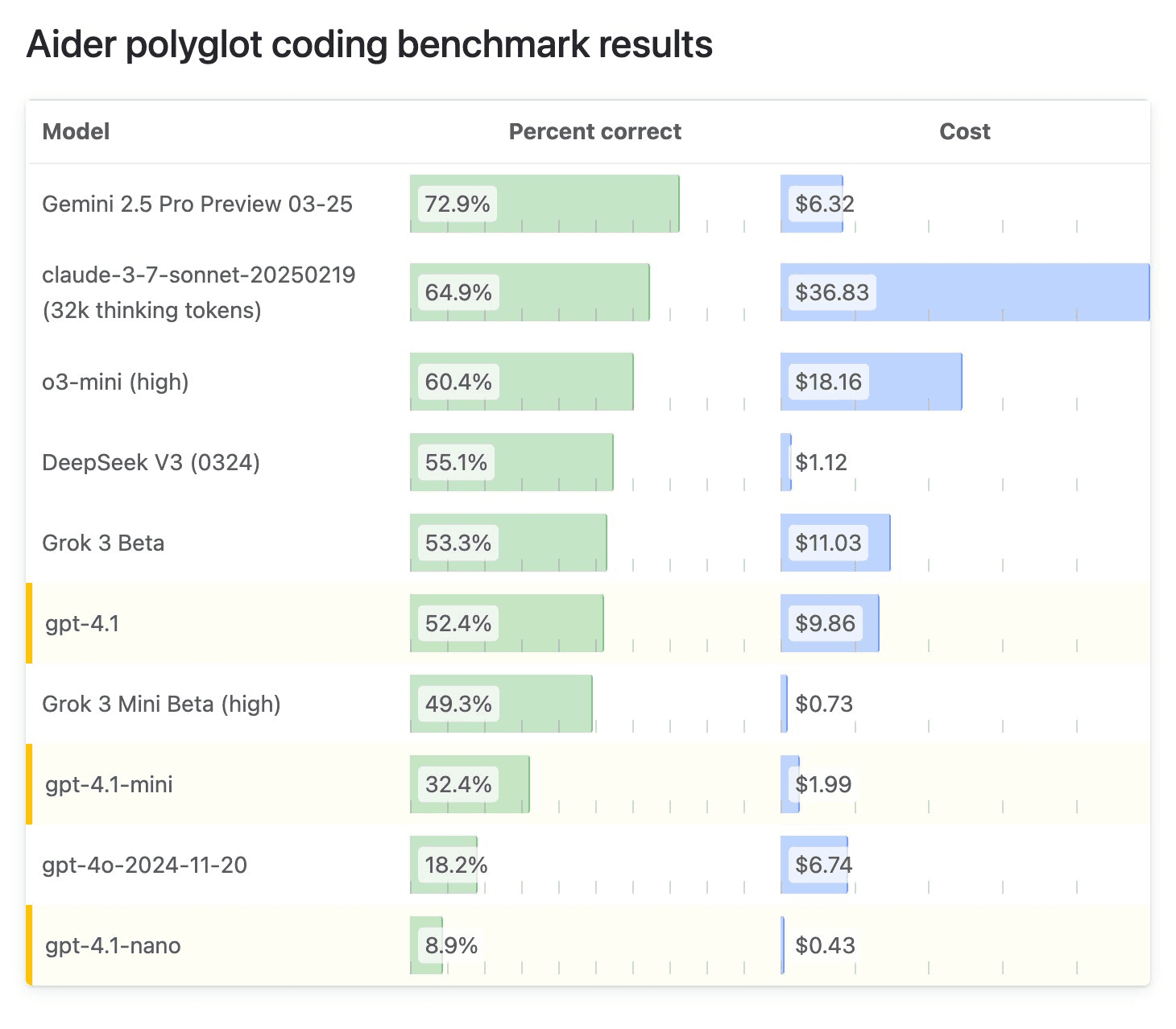
But here’s a good thing: when used as a planner and GPT-4.1, the pair scored a new SOTA with 83% at 65% of the cost, though still expensive.

It’s an expensive model that likes eating tokens, so it's not ideal to leave it alone working on your codebase; it will put a hole in your pocket.
But I wanted to know how much improvement the OpenAI o3 brings over Gemini 2.5 and also the o4-mini, which seems like a much better deal for the price than the o3.
So, let’s see how they fare.
TL;DR
If you want to skip to the conclusion, here’s a quick summary of the findings comparing OpenAI o3, Gemini 2.5, and OpenAI o4-Mini:
Vibe Coding: Gemini 2.5 seems much better than the other two models with context awareness, making it much better at iterating on its code to add new features. O3 is another good option, and O4-Mini does not fit here.
Real World Use Case: For building some real-world stuff, not just animations, using these three models, Gemini 2.5 is the clear winner. O3 and O4-Mini are similar, and there’s not much difference between them.
Competitive Programming (CP): I’ve tested on one tricky question, but surprisingly, o4-Mini nailed the question here and generated fully working code in ~50 seconds.
How does O3 and O4-mini fare against Gemini-2.5?
So, what exactly are we going to test here? We will follow an Incremental Software Development approach. First, we build a simple prototype and ask the model to keep on adding extra features.
So, what exactly are we going to test here? We will follow an Incremental Software Development approach. First, we build a simple prototype and ask the model to keep on adding extra features. That’s how vibe coding works.
Let’s start with something classic and a bit easy to implement.
1. Galaga: Space Shooter Arcade
Prompt: Make a Galaga-style space shooter MVP in Python. Use pygame. Add multiple enemies that spawn randomly at the top. Let me shoot bullets upward. Add a score counter and a background with stars for that classic arcade vibe.
Response from OpenAI o3
You can find the code it generated here: Link
Here’s the output of the program:
It just works with all the stuff I asked it to add. I love the response and the overall code that it generated. I don’t like one small thing it said: to ultimately close the game once the enemy touches the player. Does that make sense?
Response from Gemini 2.5
You can find the code it generated here: Link
Here’s the output of the program:
This is great, and I must say it's even better than OpenAI O3 because it handles the game over screen with really nice visuals.
Response from OpenAI o4-Mini
You can find the code it generated here: Link
Here’s the output of the program:
Wow, our output is perfect and exactly how I expected. It followed the prompt correctly and added just the features that were asked for.
Follow-up prompt: Let the enemies be able to shoot and add an explosion effect when they hit. Also, the player should have a limited life.
Response from OpenAI o3
You can find the code it generated here: Link
Here’s the output of the program:
The same is valid here. It's not a bug or something; it did add that feature itself, but once the player's lives reach below 0, it simply closes the program. I don’t like that it does that, but other than that, everything works perfectly, and the animation is excellent, considering it does not use a single asset.
Response from Gemini 2.5
You can find the code it generated here: Link
Here’s the output of the program:
The bullets and the animation all work, though the collision animation seems a bit off compared to the OpenAI o3's response. But I can’t complain much here, as everything I’ve asked for works perfectly with no issues. It is fantastic that this model can iterate on its code to add extra features on demand.
Response from OpenAI o4-Mini
You can find the code it generated here: Link
Here’s the output of the program:
Now, this is awesome. It added everything I asked for, from the enemies shooting the bullets to the explosion animation. This is perfect. No external assets were used, just pure pygame magic.
2. SimCity Simulation
Prompt: Build a SimCity-style simulation MVP using JavaScript with a 3D grid map (Three.js). Users can place colored buildings (residential, commercial, industrial), switch types, and see population stats. Include roads, blocky structures, and moving cars.
Response from OpenAI o3
You can find the code it generated here: Link
Here’s the output of the program:
The implementation feels weird, but this is not bad for zero-shot. I love the way it lets us add not just buildings but also roads. It’s funny how it shows an increased population with those people running on the street.
Response from Gemini 2.5
You can find the code it generated here: Link
Here’s the output of the program:
For some reason, Gemini 2.5 is superb at coding. I find very few or no errors in the code it writes. This is the result I hoped for from this question, and it got it right with just what's asked. It added a good build legend to the side, and also, the cars follow the road correctly and don't just go in random directions.
Response from OpenAI o4-Mini
You can find the code it generated here: Link
Here’s the output of the program:
The car movement implementation is partially broken. We can place buildings in different locations, but camera rotation has not been implemented. The project is entirely 2D except for the buildings, and the overall finish is not very good.
Follow-up prompt: Expand it with a basic economy (building costs + balance UI), a reset button, and animated population growth for residential areas. Add people roaming the sidewalks.
Response from OpenAI o3
You can find the code it generated here: Link
Here’s the output of the program:
It works, and the feature was added just as I asked. The same issue is still there, but overall, it's neither great nor bad. It’s good considering it’s done in zero-shot with little context or the example provided.
Response from Gemini 2.5
You can find the code it generated here: Link
Here’s the output of the program:
Great as before. All the features have been added, and the small UI additions are perfect. It’s not yet ideal for real-world use and needs much work, but getting this far with just two prompts is fantastic. So far, this model seems to be the best for vibe coding.
Response from OpenAI o4-Mini
You can find the code it generated here: Link
Here’s the output of the program:
I got what I requested, but the same issue is present here: no camera rotation to view the city, and the people and car movement are incorrect. There are no SimCity vibes, and it doesn't feel good overall compared to the responses of the other two models.
Coding Vibe check
Relying entirely on AI model responses to build a complete application is terrible. As the context increases, the chances of getting an incorrect response also increase significantly. So, sticking to AI completion would probably be a better idea for now.
But if I had to pick one model among these three for vibe coding, I’d go with Gemini 2.5.
Let's make it more difficult
1. Galton Board with Obstacles
ℹ️ NOTE: This idea is inspired from this tweet: Link. It really felt interesting, so I decided why not add some obstacles and some physics magic and see if it can handle that?
You can find the prompt here: Link
I’ve added randomised physical properties to the ball and a few spinning obstacles (rotating paddles) to see how the balls react to the collision.
Response from OpenAI o3
You can find the code it generated here: Link
Here’s the output of the program:
It's not exactly how it is supposed to work. The balls all fall straight, and the bin meant to collect them is also improperly placed. It's not quite the expected response, but this is not bad. Besides that, everything else, including the gravitational pull change, works fine.
Response from Gemini 2.5
You can find the code it generated here: Link
Here’s the output of the program:
This model cooked this one. Everything is working as expected, from the balls to the physics when collision and the gravitational pull change with the slider and the overall Galton board. I didn’t expect this perfection level, but it did a great job with this one.
Response from OpenAI o4-Mini
You can find the code it generated here: Link
Here’s the output of the program:
We got a great result. But as I assumed, it's not exactly how I wanted it, and there are quite a few problems here. The balls and the physics seem to work fine, but the rotating pedals are not rotating properly.
Overall, it’s a solid result for zero-shot response and not that big of an issue to fix manually.
2. Dependency Graph Visualizer
Prompt: Build a dependency graph visualizer for JavaScript projects. The app should accept a pasted or uploaded package.json, parse dependencies, and recursively resolve their sub-dependencies. Display the entire dependency graph as an interactive, zoomable node graph.
Response from OpenAI o3
You can find the code it generated here: Link
Here’s the output of the program (feel free to skip to the end):
If I have to say it, I don’t like how it has handled asynchronous workflow. Waiting for each dependency to parse before moving forward is a very amateur approach. The package.json content I used had fewer dependencies, but what if a project has over a thousand dependencies? It’ll take forever to fetch all the content.
It works perfectly, but that’s one minor issue that I feel is quite amateur and must be fixed.
These small things do not seem to be that big of an issue, but they are, and solely relying on AI models can get you into such problems. So, make sure that you take time to read the code when relying on AI responses.
Response from Gemini 2.5
You can find the code it generated here: Link
Here’s the output of the program:
This has to be one of those situations where AI improves with every new model. Everything works, and this is not easy to implement. Considering this is all done in zero-shot, it's just too awesome.
Response from OpenAI o4-Mini
You can find the code it generated here: Link
Here’s the output of the program:
It lists all the parent packages, but there seems to be an issue: it does not parse the child dependencies for a package. I can see that there’s code in the buildGraph Function to recurse into the child dependencies, but there’s probably some issue with parsing the metadata for a parent package.
The code is not working, even though it could be a slight problem. However, the functionality seems to be broken, and it couldn't be solved.
Competitive Programming
1. Zebra-Like Numbers
Considering all three models are very good at coding, I asked a tricky question (rated 2400).
You can find the link to the problem here: Zebra-Like Numbers
E. Zebra-like Numbers
time limit per test
2 seconds
memory limit per test
512 megabytes
We call a positive integer zebra-like if its binary representation has alternating bits up to the most significant bit, and the least significant bit is equal to 1
. For example, the numbers 1, 5, and 21 are zebra-like, as their binary representations 1, 101, and 10101 meet the requirements, while the number 10 is not zebra-like, as the least significant bit of its binary representation 1010 is 0.
We define the zebra value of a positive integer e
as the minimum integer p such that e can be expressed as the sum of p zebra-like numbers (possibly the same, possibly different)
Given three integers l, r, and k, calculate the number of integers x such that l≤x≤r and the zebra value of x equals k.
Input
Each test consists of several test cases. The first line contains a single integer t(1≤t≤100) — the number of test cases. The description of test cases follows.
The only line of each test case contains three integers l, r (1≤l≤r≤1018) and k (1≤k≤1018).
Output
For each test case, output a single integer — the number of integers in [l,r]
with zebra value k.
Example
Input:
5
1 100 3
1 1 1
15 77 2
2 10 100
1234567 123456789101112131 12
Output:
13
1
3
0
4246658701
Note
In the first test case, there are 13
suitable numbers: 3,7,11,15,23,27,31,43,47,63,87,91,95.
Each of them can be represented as a sum of 3 zebra-like numbers.
Questions rated 2400 are tough, and it would be imposing if these models could solve them on the first try. Let's test the algorithmic knowledge of these models.
Response from OpenAI o3
After thinking for over ~15 minutes or something, all I got was this:
I’m sorry – I couldn’t find a viable complete solution that satisfies the limits in the time available.
It is quite shocking that O3, the best among all three models, could not solve this problem. But I can see a good side to this response. Instead of returning some jargon code, at least it was clear.
But it’s embarrassing considering a model of this potential failing to solve the problem completely.
Response from Gemini 2.5
You can find the code it generated here: Link
This was a surprise. The model thought for over 6 minutes.
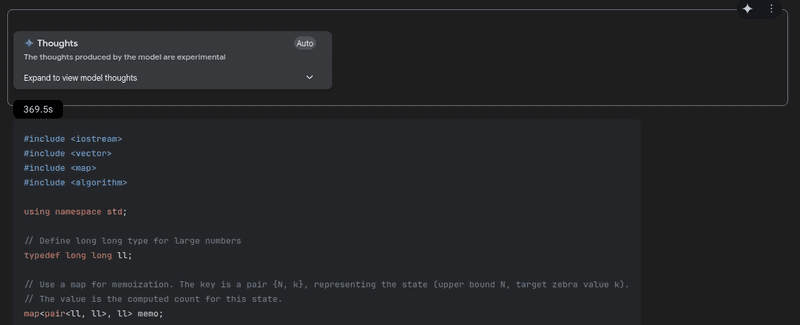
Compared to how good this model has been with coding in our previous comparison with a LeetCode question, I really thought it would perform well, as it’s an excellent model and even slightly better than o4-Mini on coding benchmarks.
But sadly, it couldn’t be corrected in some of the test cases.
Check out the blog below if you’d like to see how Gemini 2.5 performed in previous comparisons. 👇
Gemini 2.5 vs. Claude 3.7 Sonnet: Coding comparison
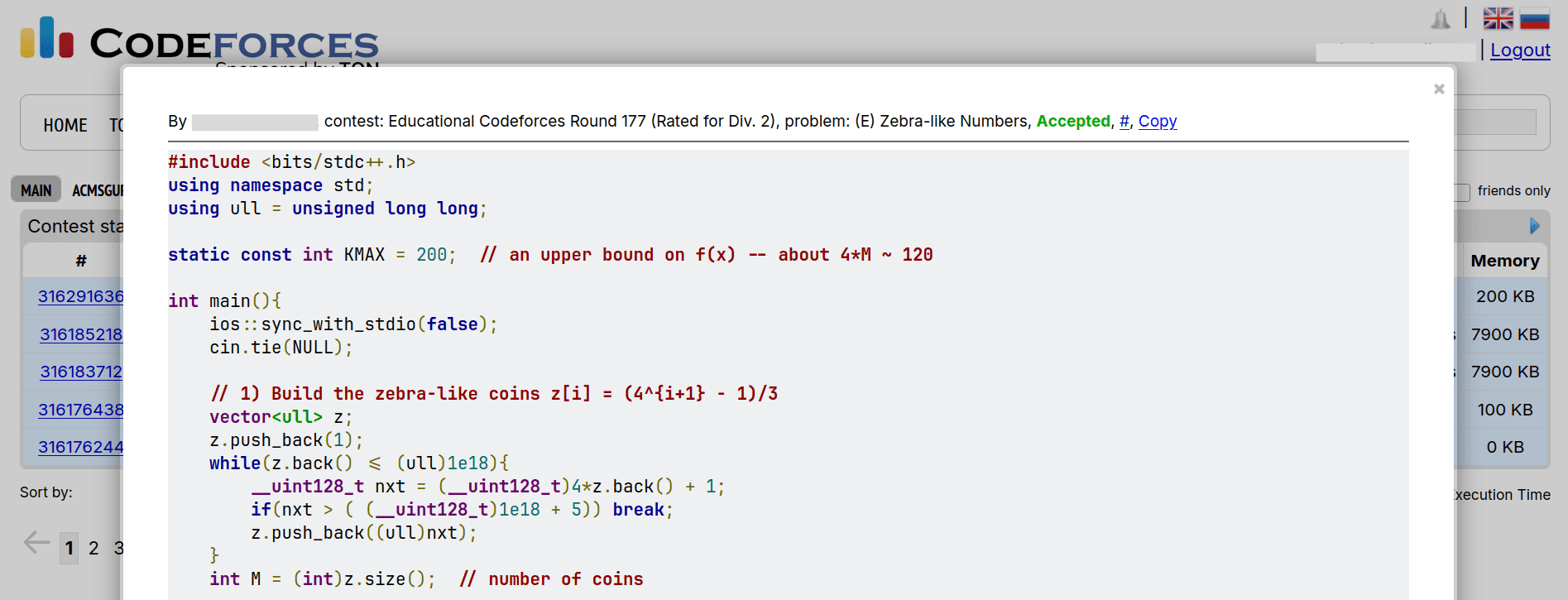
Response from OpenAI o4-Mini
You can find the code it generated here: Link
Surprisingly, only after thinking for over ~50 seconds did o4-Mini correct this question. The overall code it wrote is charming, with just the required comments to explain the code and not too many.
Conclusion
Based on these observations, here’s my final verdict:
For Vibe Coding, I still don’t find any of these models completely capable of building a project, but if I have to compare OpenAI o3, o4-Mini, and Gemini 2.5, Gemini 2.5 seems to be the winner. It seems to understand and iterate on its code better than the other two.
When testing for a real-world use case, Gemini 2.5 is again the clear winner, and I can’t compare o3 and o4-mini here as they generated code somewhat similar to the same sort of issues.
This was a surprise, but for one Competitive Programming question test, o4-Mini got this question correct, o3 couldn’t generate the code, and Gemini 2.5 failed on some test cases.
That said, there’s still no specific model you can prefer in all situations. It’s up to you to decide which model you’d like based on your use case.