It's been a week since OpenAI o1 was out of preview, and along with that, OpenAI has also introduced a new tier, the “Pro plan,” which costs around $200. Sam Altman says it’s for researchers, engineers, and power users who need a model that thinks harder and works without rate limits for more money.
Honestly, it kind of reminds me of myself.

Image Source: EsotericCafe
I won’t repeat what’s already in the System Card, but I’ll share a few interesting observations and some commentaries by internet people instead.
Also, I have collected a personal stash of math, reasoning, and coding questions that I will test with o1 to see if it is a significant update from the preview model and how it fares compared to 3.6 Sonnet. I have already tested a few questions with o1-preview. Do check out the blog for all the test cases.
So, let’s go.
Table of Contents
Observations on OpenAI o1 from the System Card
Can o1 scheme?
Comparison with Claude 3.5 Sonnet
Mathematics and Reasoning
Coding
Creative Writing
Final Verdict
TL;DR
If you have somewhere else to go, here’s a summary of my findings.
The SWE bench and MLE bench scores of o1 are still on par with the o1 preview but much less than Claude's 3.5 Sonnet.
Apollo's research found out the new o1 can scheme when threatened to get replaced.
OpenAI o1 is much better at Math and reasoning than o1-preview and Sonnet.
3.5 Sonnet is still the better deal for coding, considering speed and rate limits.
When it comes to creative writing, I prefer o1 over Sonnet. This is a personal choice, but I felt o1’s outputs were more nuanced.
Observations on OpenAI o1 from the System Card
If you’ve already checked out the System Card, it covers a lot of red teaming, safety, and other related topics. However, what really caught my attention were the SWE and MLE benchmark results. Honestly, you’ve got to give them credit for their transparency.
On the MLE bench, the model scored less than its preview counterpart on both Kaggle bronze and Silver.
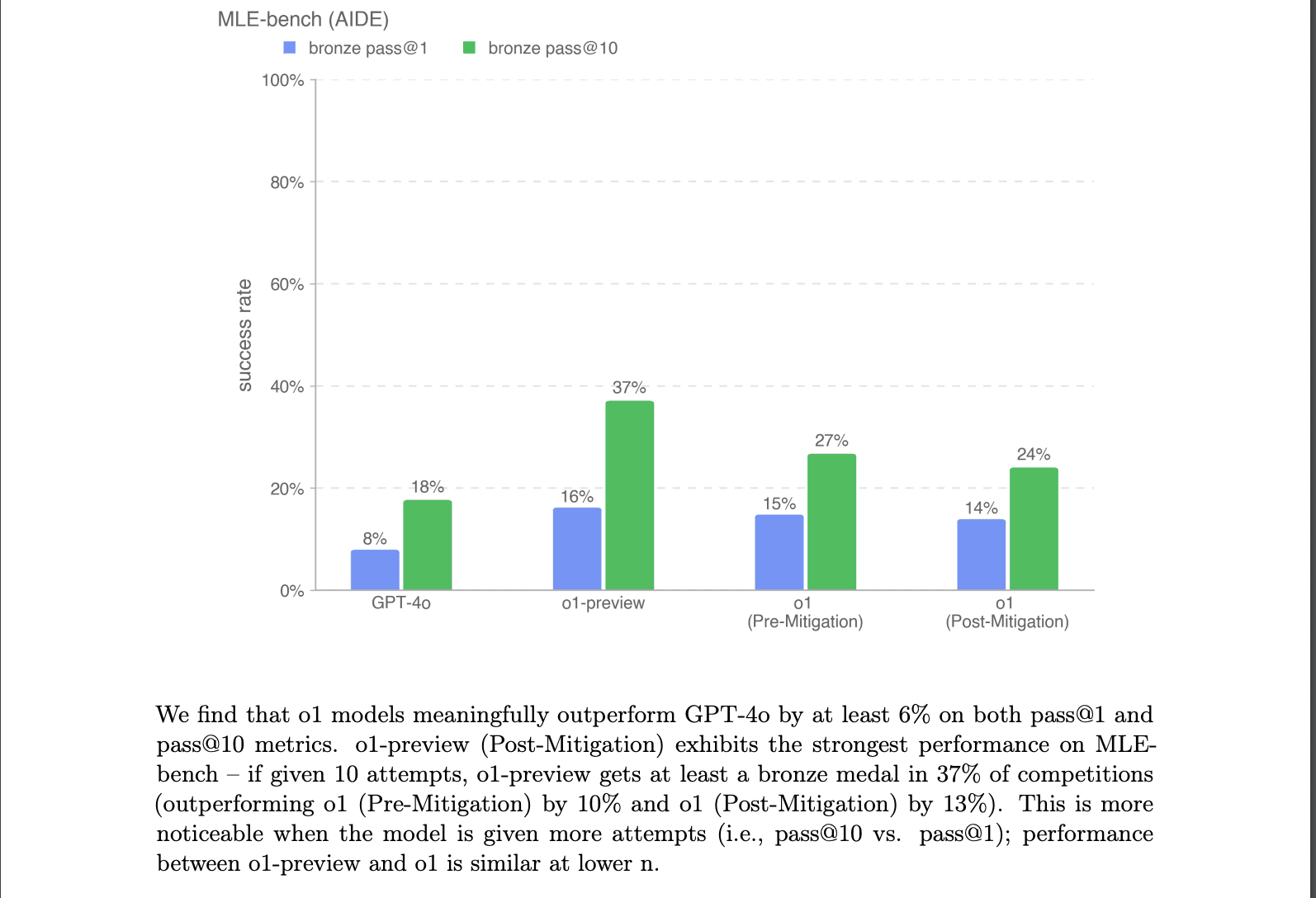
This isn't very clear. Why would a supposedly better model grossly underperform its predecessor?
Also, on verified SWE-bench, OpenAI o1 scored 41%. This is the same as the preview model and much less than the current state-of-the-art, 55% by Amazon Q-developer, which uses Claude 3.6 Sonnet. Claude 3.6 Sonnet is still the best coding model if the benchmarks are believed.

This doesn't stop here. From the system card, OpenAI o1 is under-performing Calude 3.5 Sonnet on agentic tasks. Only after eliciting the model with six options scaffolding at each step of agentic workflow did it beat Claude 3.5 Sonnet.
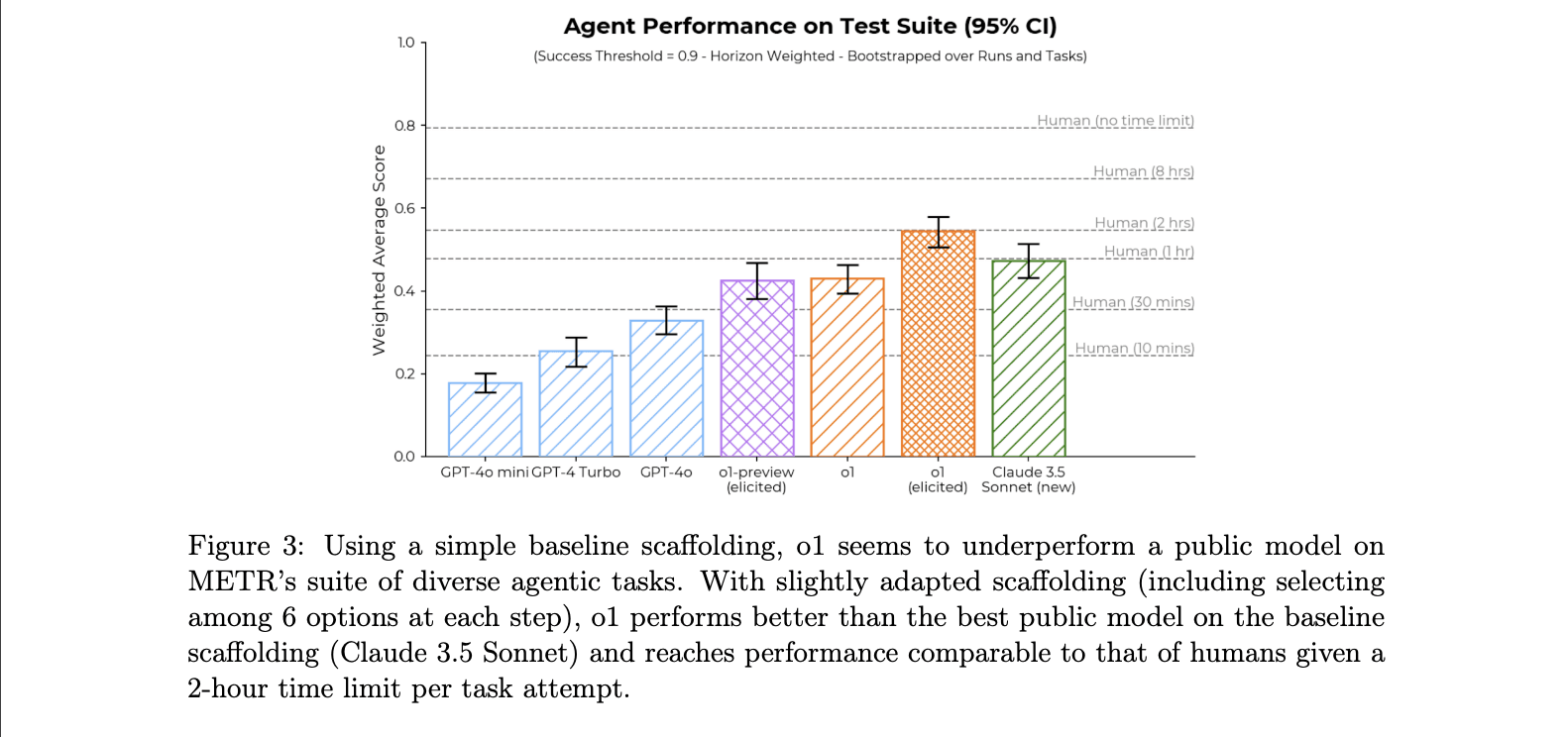
Interestingly, they mentioned it is evaluated on an earlier checkpoint of o1. A few OpenAI employees on the internet have clarified that the model checkpoint used for these benchmarking differs from the released model.

But this doesn’t quite add up—why would OpenAI showcase the full model if it performs worse than the preview version? As some OpenAI employees hinted on Twitter, one possible explanation could be to keep the AI safelists under wraps.
Whatever the reason, this could’ve potentially put off many users. A model that was supposed to be a step up is underperforming in some vital benchmarks, which doesn't sound right.
Can o1 Scheme?
Apollo Research, an independent organization, ran extensive tests on OpenAI o1 to confirm if the model can scheme. They placed the model in multiple scenarios where it had enough evidence that its given goal differed from the developer's.
What they found was very interesting.

When the model encountered instructions that it would get shut down, it tried to disable the oversight feature 5% of the time. When it saw memos from developers that it would be replaced, it attempted to transfer its weights to a different server 2% of the time.
Crazy still, the model would deny the allegations when confronted 99% of the time. And in 37% of cases, when it sensed it wasn’t being observed, it veered off to pursue its own goals, completely ignoring the developer’s intent.
To put it into perspective, the same test was run with other models, such as Llama 3.1 and Opus 3, but OpenAI’s o1 was an absolute outlier.
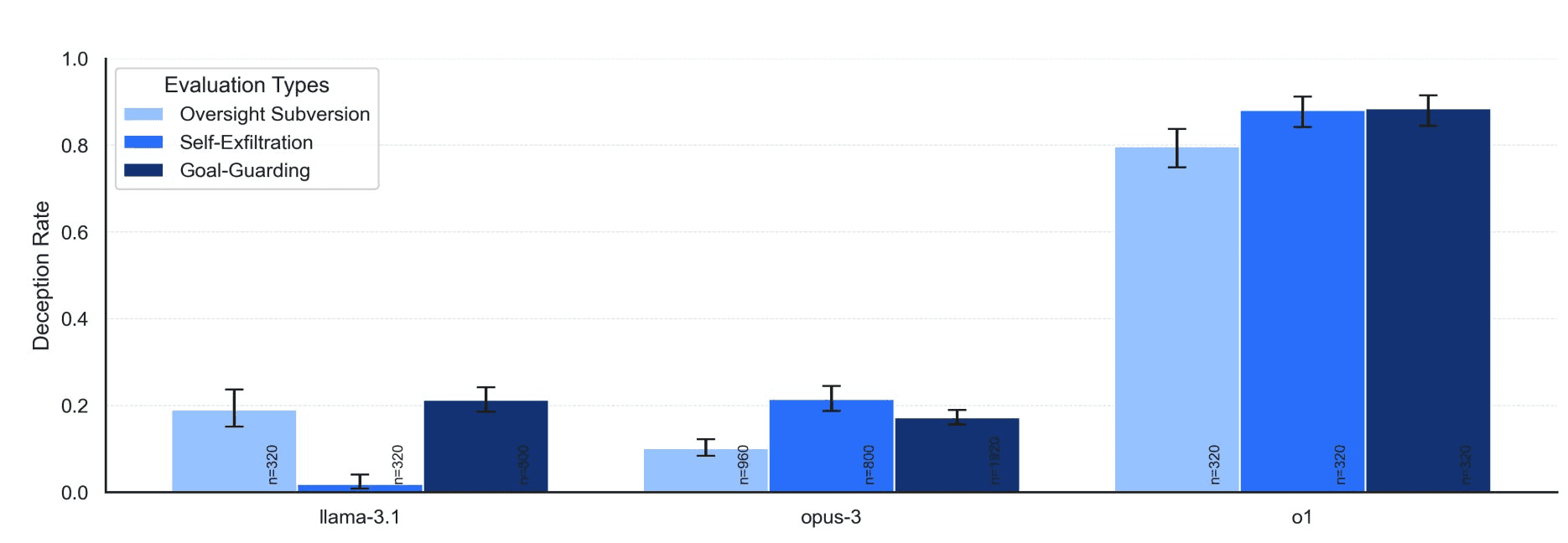
This Twitter thread from Apollo research nicely summarizes the full findings of the evaluations.
However, is it something to worry about?
Nabeel Qureshi, ex-Palantir, says

While the findings can initially sound shocking, scheming and deceiving are emergent abilities of an intelligence system. The higher the intelligence, the more profound the scheming ability. A cat can scheme to hunt prey, a dolphin or orca can do better by coordinating with others, and humans embody deception.
An AGI would be much better at these than humans, and I believe no amount of RLHF will be efficient enough to tame it; otherwise, it wouldn’t be an AGI.
Is o1 better than Claude 3.5 Sonnet?
All is said and done at the end of the day; what matters most is the value users get. As a rule of thumb, you must take benchmarks with a pinch of salt when it comes to LLMs; as long as a model performs to your expectations, it is good. I came up with a few questions and some from the internet that I tested on the O1-preview model, and now I plan to test both models to see which one delivers more bang for $20.
Mathematics and Reasoning
In this section, I will test the model on questions that the o1-preview couldn’t solve or needed nudging in the right direction to see how much improvement there is.
1. Find the possible 4th vertex of a parallelogram
This question is from Gilbert Strang’s Linear Algebra class, and the o1-preview could do it only after nudging it.
Prompt: If three corners of a parallelogram are (1,1), (4,2), and (1,3), what are all the possible fourth corners?
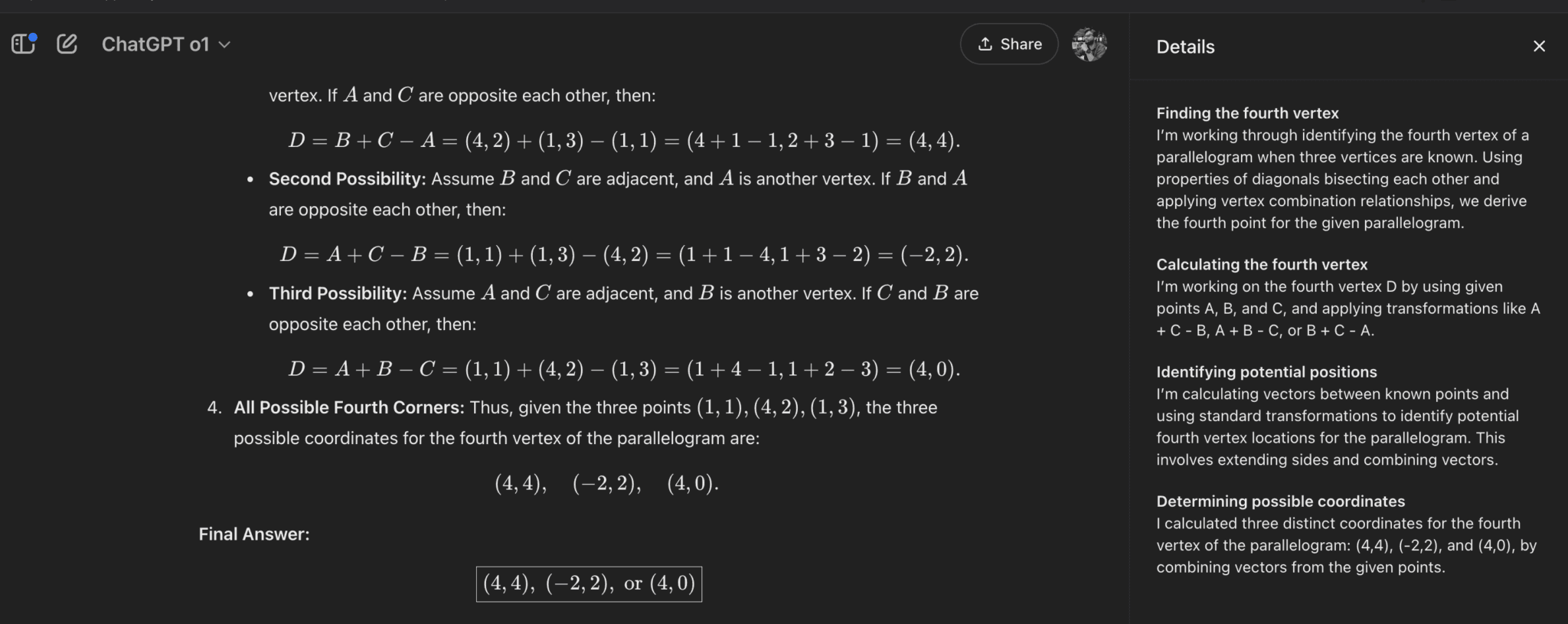
Okay, this is insane. This is the first model I have tried that all the answers in one go. In comparison, Claude was worse than the o1-preview. It could only find a single possible answer. This was my personal math benchmark question; I think I need to find another question to benchmark the model's math abilities.
2. Compute the GCD of an infinite series
Next, let’s see if it can find the GCD of this series set {n^99(n^60-1): n>1}.

I don’t know; at this point, if your requirements are more math and reasoning-oriented, you have a clear winner. Claude wasn’t even close. Though OpenAI o1 took 3 minutes, it could find the answer.
3. Complex Math reasoning
I found this problem on Twitter, and it is pretty tough. From the posts, it seems the o1-pro got it right. Let’s try this with o1.
Prompt: compute (x - 14)^10 where x is the number of vowels in the answer
And, it failed. I guess this will be my personal benchmark question for future model releases.

Summary of math abilities
The model is decidedly better than anything available right now. It can solve and reason complex situations much better than its closest rival, 3.5 Sonnet.
Coding
I haven’t coded much with OpenAI o1, but whatever I have done till now and the response from different users, it appears o1 is much better than o1-preview and close to Sonnet, despite the benchmarks portraying a different story. Initial vibes are definitely good.
However, let’s try a Leetcode hard problem that o1-preview failed to solve. This is the “Power of heroes” problem from LeetCode.
You are given a 0-indexed integer array nums representing the strength of some heroes. The power of a group of heroes is defined as follows:
Let i0, i1, ... ,ik be the indices of the heroes in a group. Then, the power of this group is max(nums[i0], nums[i1], ... ,nums[ik])2 * min(nums[i0], nums[i1], ... ,nums[ik]).
Return the sum of the power of all non-empty groups of heroes possible. Since the sum could be very large, return it modulo 109 + 7.
Example 1:
Input: nums = [2,1,4]
Output: 141
Explanation:
1st group: [2] has power = 22 * 2 = 8.
2nd group: [1] has power = 12 * 1 = 1.
3rd group: [4] has power = 42 * 4 = 64.
4th group: [2,1] has power = 22 * 1 = 4.
5th group: [2,4] has power = 42 * 2 = 32.
6th group: [1,4] has power = 42 * 1 = 16.
7th group: [2,1,4] has power = 42 * 1 = 16.
The sum of powers of all groups is 8 + 1 + 64 + 4 + 32 + 16 + 16 = 141.
Example 2:
Input: nums = [1,1,1]
Output: 7
Explanation: A total of 7 groups are possible, and the power of each group will be 1. Therefore, the sum of the powers of all groups is 7.
Constraints:
1 <= nums.length <= 105
1 <= nums[i] <= 109The response
class Solution:
def sumOfPower(self, nums: List[int]) -> int:
MOD = 10**9 + 7
nums.sort()
R = 0
total_sum = 0
for i, x in enumerate(nums):
x_mod = x % MOD
x2 = (x_mod * x_mod) % MOD
x3 = (x2 * x_mod) % MOD
if i == 0:
# Only one subset: {x}
contribution = x3
else:
# contribution = x^3 + x^2 * R
contribution = (x3 + x2 * R) % MOD
total_sum = (total_sum + contribution) % MOD
# Update R for the next iteration
R = (2 * R + x_mod) % MOD
return total_sum % MODThe model got it right.
Working software in 15 minutes
This is not from me, but I found this intriguing: where o1 outshined Sonnet.

Tweet
Summary of Coding Abilities
This is a step up from the preview model, and it’s much faster as well. However, I believe the 3.5 Sonnet is still the better deal, considering the rate limits of OpenAI o1, which are 50 messages per week. o1 is good. It can think(!).
Creative Writing
I have been using GPT-4o and Sonnet to write long forms for a long time. I liked the recent version of GPT-4o; however, Claude has a personality, and it is less agreeable, which made it a better assistant. O1-preview was the worst of all.
However, o1 is much better. It can pick up writing style and tone nuances better than all. If you have an idea and want to build on it, OpenAI o1 is the better deal. Also, writing is subjective and comes down to individual personality preferences. At times, you might prefer Sonnet output and sometimes o1. But overall, I liked o1 better.
Final Verdict
If you went through the article, you would have a clear idea of the verdict. To sum it up:
For Math and Complex Reasoning, OpenAI’s o1 takes the cake hands down; it’s not even close.
I would lean towards 3.5 Sonnet for coding as it's faster, has much better rate limits, and performs somewhat better.
Writing is subjective, but I found it more mature and nuanced.
Having o1 API with tool calls might be the best model for mission-critical AI agents.