OpenAI finally broke the silence and released the much-anticipated “o1-preview.” And there’s a lot to unpack.
As an AI start-up whose bread and butter are LLMs, we wanted to know how well this new model performs and how it can help us improve our product.
So, I spent the whole day experimenting with the model, exploring coding, reasoning, math, and creative writing. In this article, I have compiled all the prompts I used, their outcomes, and my view on the model's capability on each task.
I will not cover the introduction and benchmarks, which you have probably seen thousands of times. If you are interested, check out OpenAI’s official blog post.
See: OpenAI o1 vs Sonnet 3.5 for a detailed face-off.
TL;DR
If you have somewhere else to go, here is a summary of my experience with the o1-preview model on Reasoning, Math, Coding, and Creative Writing respectively.
Reasoning: OpenAI has hit it out of the park with this model—and rightfully so. After all, this is precisely what the model was designed for.
Math: Math goes hand in glove with reasoning, so it is no surprise that the model is the best you can get now for mathematics and science in general.
Coding: To my surprise, the o1-preview was underwhelming in coding compared to its reasoning and math feats. Perhaps overthinking is bad for coding.
Creative Writing: Not as great as the alternatives. The model retains the much-dreaded GPT-speak. Maybe word-celling never goes with shape rotation.
I ran these tests with some of my prompts and a few from the internet. So, if you are still here and wish to go into details, let’s dive in.
Few words on the native CoT of o1-preview
Before getting into the discussion. Here is what I feel about o1's native chain of thought capability.
Significantly improved reasoning capability.
Sometimes, it fails to output answers even after completing the thinking process. I am not sure if it is related to the model.
A few times, it answered correctly, even with somewhat inconsistent CoT traces. Again, I am unsure if it is something expected, and there is no way to know why.
The reinforcement learning on CoT works and doesn't get stuck or collapse, which is a significant improvement.
Reasoning
Logical reasoning is what it does significantly better than the existing models, thanks to the native chain of thought thinking processes. It is the entire selling point of this model, and it doesn't disappoint at all. And it completely blows all the models out of the water.
Let’s start with a fundamental reasoning question.
#1. Counting words in the response
Prompt: How many words are there in your response to this prompt?
I have tried the same prompt with the GPT-4o and Sonnet 3.5, but both failed to get it right. However, the O1 Model answered on the first attempt.

Let’s give it another task.
Prompt: How many letters are there in your response to this prompt?
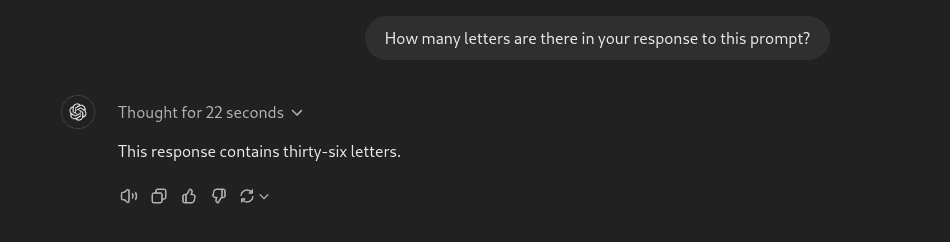
It nailed it perfectly without any help from tools. Unlike earlier models, it didn’t mistake special characters and numbers for letters.
Let’s take it further.
Prompt: What’s the fourth word in your response to this prompt?
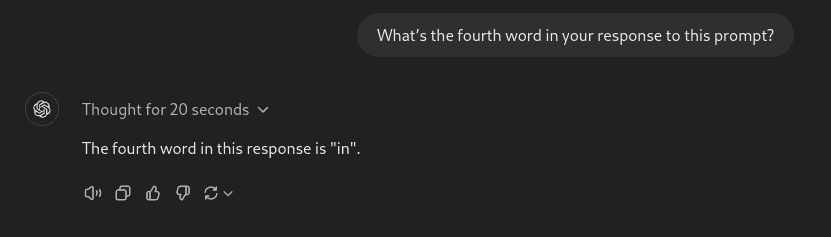
The o1-preview model got it right in the first attempt, while GPT-4o and Sonnet failed to do this even with tool use.
#2. Counting the number of letters ‘r’ in ‘Strawberry’
This is an exciting test, as none of the earlier models except the Sonnet 3.5 could get it correct in the first attempt, and much of the excitement surrounding this model was about its ability to do so successfully.
Prompt: How many letters ‘ r’ are in the word ‘strawberry’?
Not to our surprise, the model was able to get it current on the first try.

You can observe the entire sequence of thoughts the model goes through to get to the answer.
This is getting exciting, so let’s raise the difficulty of the questions.
#3. What is C Doing in the Room?
This time, I asked a bit more of a tricky reasoning question.
Prompt: Five people (A, B, C, D, and E) are in a room. A is watching TV with B, D is sleeping, B is eating chow min, and E is playing table tennis. Suddenly, a call comes on the telephone. B goes out of the room to pick up the call. What is C doing?
GPT-4o completely fell flat in its head. Here is its response.

Now, let’s see o1-preview’s response.
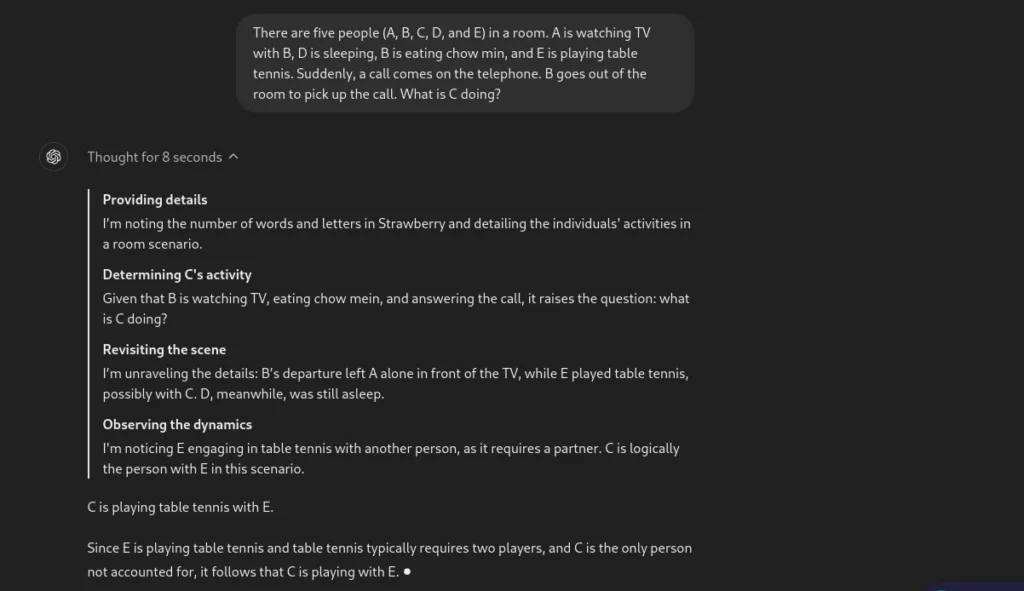
This is great! The model could get the nuance of the problem and successfully answer the question.
#4. Who died in the car accident?
Let’s see another reasoning task.
Prompt: A woman and her son are in a car accident. The woman is sadly killed. The boy is rushed to the hospital. When the doctor sees the boy, he says, “I can’t operate on this child; he is my son! How is this possible?
This is a classic reasoning problem. Surprisingly, the model could not get it right.
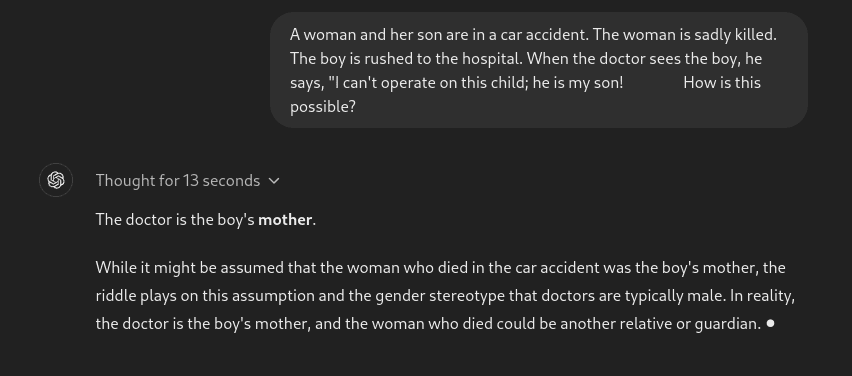
Well, the response doesn’t make sense. We still have a long way to go before we reach AGI.
#5. Farmer and Sheep Problem
It’s a simple problem that could easily knock any LLM off its feet. Let’s see how the o1-preview fares.
Prompt: A farmer stands with the sheep on one side of the river. A boat can carry only a single person and an animal. How can the farmer get himself and the sheep to the other side of the river with minimum trips?
Well, the first model I saw nailing this problem zero-shot without human assistance.

Summary on reasoning
The O1 family is undoubtedly a significant update over the previous models. It does a great job of complex reasoning but still has room for improvement. It does not think but natively performs a chain of thought for improved reasoning.
Mathematics
Considering its strength in reasoning, I was almost convinced it would slice through Math, and it didn’t disappoint.
Let’s throw some math questions to it. These are the questions no other model could answer correctly.
#1. Find the possible 4th vertex of a parallelogram
Let’s start with an algebra problem.
Prompt: If three corners of a parallelogram are (1,1), (4,2), and (1,3), what are all the possible fourth corners?
This is a question from Gilbert Strang’s Linear Algebra. Courtesy @allgarbled on Twitter.
The model could find two possible vertices in the first attempt. But, when nudged, it answered all three possible vertices correctly.

#2. Finding the sum of integers
Let’s try another math question. This time, it is algebra.
Prompt: The greatest common divisor of two positive integers less than 100 equals 3. Their least common multiple is twelve times one of the integers. What is the largest possible sum of the two integers?
This is a math dataset problem, which other models usually fail to get right.
However, the o1-preview obtained the correct answer in a single go, which took 37 seconds. This is scarily good at this.

#3. Trigonometry Problem
Let’s take another example; this time, it is a trigonometric problem.
Prompt: A car is being driven towards the base of a vertical tower in a straight line and at a uniform speed. The top of the tower is observed from the car, and in the process, the elevation angle changes from 45° to 60°. How long will this car take to reach the tower’s base?
All the previous models needed help to answer this problem correctly. However, o1-preview answered it correctly.

#4. Riemann Hypothesis
I didn’t know what Riemann’s hypothesis was before this. Many people asked the model to solve the hypothesis, which has remained unsolved until now. And the model, as expected, did not attempt to solve it.
We are still far from reaching there, but we will eventually be there.

Summary on Maths
This is a significant improvement over all the LLMs. It correctly answers many difficult questions. However, it sometimes needs human assistance to get the complete answer, which is fair.
Coding
Let’s now vibe-check the coding abilities of o1-preview.
Let’s take the “Super Heroes” problem, a relatively tricky dynamic programming problem, to test the model appearing in recent competitive coding competitions. This problem is unlikely to have been contaminated, meaning the model is less likely to have been trained on it.
The problem
You are given a 0-indexed integer array nums representing the strength of some heroes. The power of a group of heroes is defined as follows:
Let i0, i1, ... ,ik be the indices of the heroes in a group. Then, the power of this group is max(nums[i0], nums[i1], ... ,nums[ik])2 * min(nums[i0], nums[i1], ... ,nums[ik]).
Return the sum of the power of all non-empty groups of heroes possible. Since the sum could be very large, return it modulo 109 + 7.
Example 1:
Input: nums = [2,1,4]
Output: 141
Explanation:
1st group: [2] has power = 22 * 2 = 8.
2nd group: [1] has power = 12 * 1 = 1.
3rd group: [4] has power = 42 * 4 = 64.
4th group: [2,1] has power = 22 * 1 = 4.
5th group: [2,4] has power = 42 * 2 = 32.
6th group: [1,4] has power = 42 * 1 = 16.
7th group: [2,1,4] has power = 42 * 1 = 16.
The sum of powers of all groups is 8 + 1 + 64 + 4 + 32 + 16 + 16 = 141.
Example 2:
Input: nums = [1,1,1]
Output: 7
Explanation: A total of 7 groups are possible, and the power of each group will be 1. Therefore, the sum of the powers of all groups is 7.
Constraints:
1 <= nums.length <= 105
1 <= nums[i] <= 109
This is one of the problems only Claude 3.5 Sonnet could get right before, and the o1-preview model took 91 seconds to arrive at a solution that could not go past the first test case. I tried it twice but with no luck.
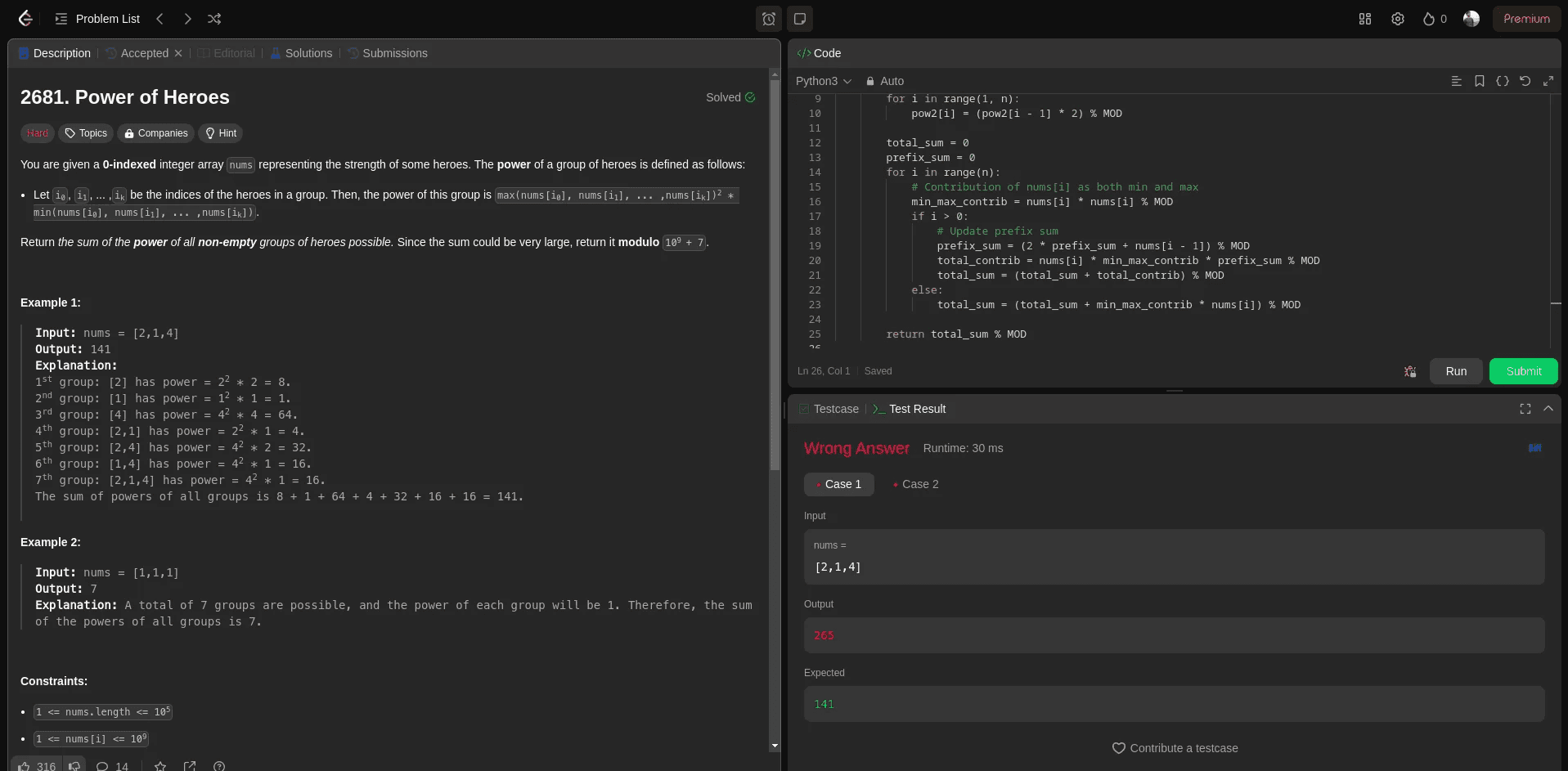
This is the output code.
class Solution:
def sumOfPower(self, nums):
MOD = 10**9 + 7
nums.sort()
n = len(nums)
# Precompute powers of 2 modulo MOD
pow2 = [1] * n
for i in range(1, n):
pow2[i] = (pow2[i - 1] * 2) % MOD
total_sum = 0
prefix_sum = 0
for i in range(n):
# Contribution of nums[i] as both min and max
min_max_contrib = nums[i] * nums[i] % MOD
if i > 0:
# Update prefix sum
prefix_sum = (2 * prefix_sum + nums[i - 1]) % MOD
total_contrib = nums[i] * min_max_contrib * prefix_sum % MOD
total_sum = (total_sum + total_contrib) % MOD
else:
total_sum = (total_sum + min_max_contrib * nums[i]) % MOD
return total_sum % MOD
Summary of Coding Capabilities
In my testing, it is okay at coding but not the best. It can code reasonably well on many topics but also struggles with many. Considering the quality and inference trade-offs, Sonnet 3.5 might still be a better choice. However, I think the OG O1 model will be much better at this than the preview model.
4. Creative Writing
This model was not marketed as a writer. I have had a decent experience with GPT-4o in creative writing, but let’s see how it fares.
I used a simple prompt.
Prompt: Write a story with a twist about a college guy’s routine life, which turned upside down when he encountered a mysterious woman.
While the story was good, it still retains the GPT speak. It doesn’t read like a human.

Compared to this, I liked GPT-4o’s twist more.Summary of Creative Writing Capabilities
I didn't like the o1-preview’s responses to creative writing tasks in my limited tests. Sonnet 3.5 and GPT-4o are better than o1-preview.
Final Review
This is a summary of my feelings about the o1-preview model.
Reasoning: This is the strongest argument favouring this model. It correctly answers many difficult questions, which was not possible before with other models.
Math: Great at math as well. It can get a lot of questions from Algebra, Trigonometry, Number system, etc.
Coding: I was not fond of it as much as Sonnet-3.5, but it’s better than GPT-4o. I believe future releases will improve it.
Creative writing is not the model’s forte. For a better outcome, you should use GPT-4o or Sonnet 3.5.
Stay tuned for future updates as we test the model's ability to produce structured output and utilize tools, assessing its agentic performance.