AlsoThe Llama 4 is here, and this time, the Llama family has three different models: Llama 4 Scout, Maverick, and Behemoth. While the former two are available on multiple platforms, the Behemoth, as per Zuck and Meta, is still in training. And it is reportedly beating the current state-of-the-art.
There is no improvement in the licensing part; the models come with the same Llama license that restricts any company with more than 700 million monthly active users from using the models without Meta’s permission and is also not available for Europeans.
It's crazy why they persist with this bogus license when Deepseek v3 0324 and r1 are readily available under MIT. Also, it is not available to Europeans. A Llama License in Big 2025 is criminal. Also, read Llama 4 Maverick vs Deepsek v3 0324
But anyway, unlike the Llama 3, Meta has moved on from dense models to a Mixture of experts (MoEs). Both models come with a sparse mixture of experts: the Scout has 17B active and 109B total parameters with 16 experts, and the Maverick has 400B total and 17B active parameters with 128 experts.
There are no local models this time; everyone expected Meta to bring smaller dense models (3b, 8b, 32b, 70b) like the last time. But hey, we still get two open-weight models except fellow Europeans.
Table of Contents
The pitch
The Hits
10M in context length
Natively multi-modal
Teacher-student distillation
The Misses
Not enough
Confused positioning
The Disasters
Not really 10M
Benchmark blunders
Tokenizer terror
There's still hope
TL;DR
Meta rushed the release of Llama 4 Maverick and Scout. (Could it be the tariffs?)
The Scout has a humongous 10M in context length, and the Maverick has 1M.
The models have been derived from the biggest Llama Behemoth, a 2T model.
The model is severely underwhelming on all fronts: code gen, writing, and everyday conversations.
The models tend to output verbose responses (yapping, they call it).
The models are so bad Meta had to fudge benchmarks.
The Pitch
Meta: Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
17B-active-parameter model with 16 experts.
Industry-leading context window of 10M tokens.
Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.Llama 4 Maverick
17B-active-parameter model with 128 experts.
Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
It sure got the big model vibes, though no local models will sting a lot of Llama enthusiasts.
The Llama 4 Pre-training precap by Elle from Huggingface.
> MetaP: MuP inspired method to set per layers hyperparameters that transfer across batch size, width, depth and training token (huge)
> MoE with 16E and 128E
> QK Norm with no learnable parameter (and the 128E have no QK Norm it seems)
> FP8 Training
> No rope on interleaved attention layers, but i don't see any sliding window attention? (one of the key receipe for the 10M context they said)
> temperature tuning on the no rope layers
> Native multimodal training
> Mixture with 30T token (text, images and video), training budget of 40T for 128E and 22T for the 16E
> No details on optimizer...
The Hits
10M in context length
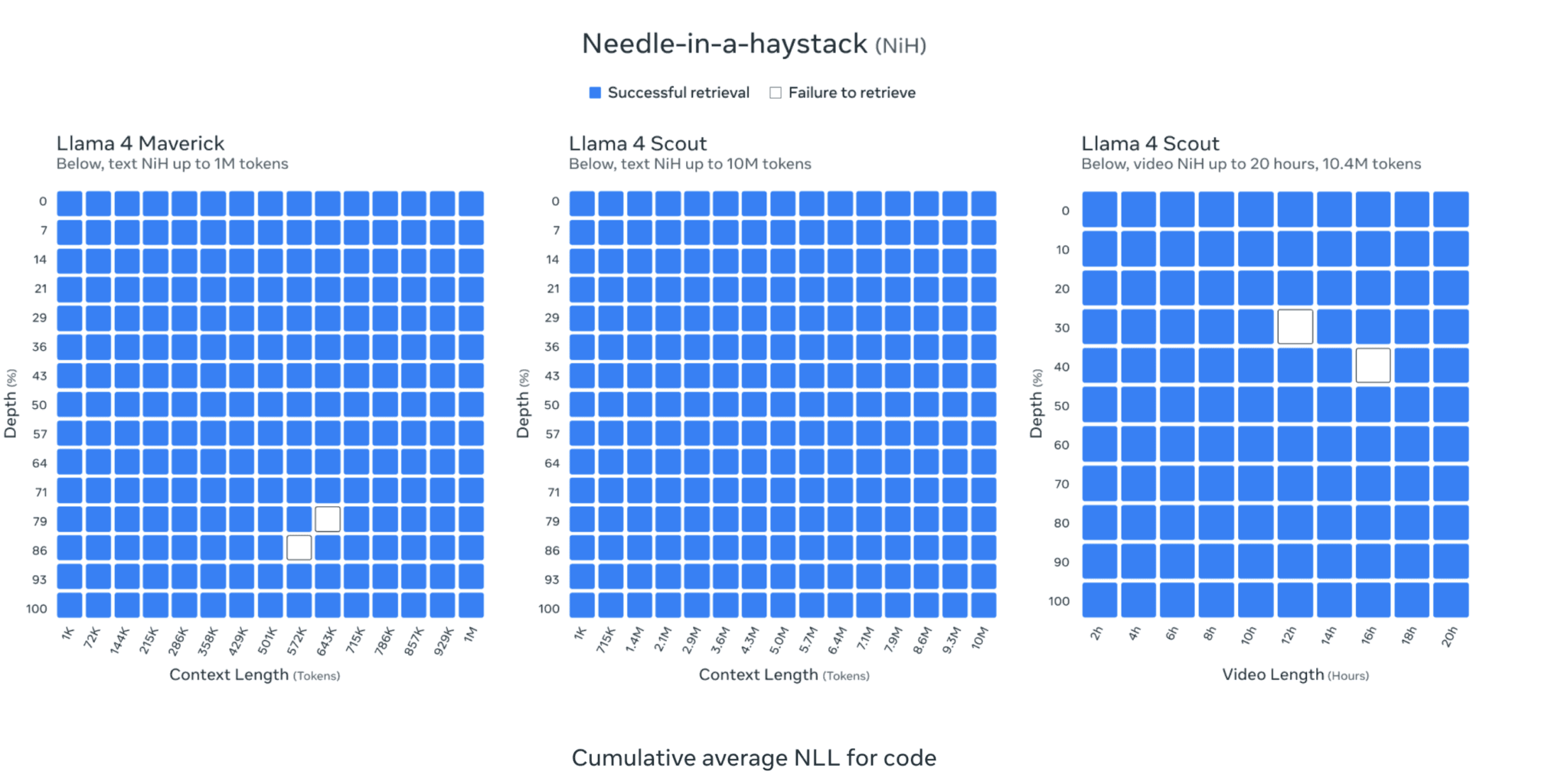
The model has its own highs. The most prominent one is the 10 million context length in the Scout model. This is the first model including both open-source and proprietary LLMs. The Maverick comes with a one million context length.
Ideally, you can put your entire code base in context and get the LLM to work on it. However, I don’t think it will be the same for Behemoth, which would have been much better at coding than Llama 4 Scout.
This is huge. Until now, only Google has been able to crack the long context window, and now Meta. The needle in the haystack results are also promising for Llama 4 models.
Natively Multi-modal
The other pros of the model are that it is natively multi-modal and understands texts, images, audio, and videos, though the output modality is limited to text only.
Teacher-Student Distillation
However, the more interesting part is the teacher-student distillation from Llama 4 Behemoth. This is the first from Meta.
Meta: We codistilled the Llama 4 Maverick model from Llama 4 Behemoth as a teacher model, resulting in substantial quality improvements across end task evaluation metrics. We developed a novel distillation loss function that dynamically weights the soft and hard targets through training. Codistillation from Llama 4 Behemoth during pre-training amortizes the computational cost of resource-intensive forward passes needed to compute the targets for distillation for the majority of the training data used in student training. For additional new data incorporated in student training, we ran forward passes on the Behemoth model to create distillation targets.
Some notes from xjdr
- Scout is best at summarization and function calling. exactly what you want from a cheap long ctx model. this is going to be a workhorse in coding flows and RAG applications. the single shot ICL recall is very very good.
- Maverick was built for replacing developers and doing agenic / tool calling work. it is very consistent in instruction following, very long context ICL and parallel multi tool calls. this is EXACTLY the model and capabilities i want in my coder style flows. it is not creative, i have V3 and R1 for that tho. multimodal is very good at OCR and charts and graphs outperforming both 4o and qwen 2.5 VL 72 in my typical tests. the only thing i haven't tested is computer use but i doubt it will beat sonnet or qwen at that as both models were explicitly trained for it. The output is kind of bland (hence the constant 4o comparisons) with little personality, which is totally fine. this is a professional tool built for professional work (testing it on RP or the like will lead to terrible results). Im not sure what more you could ask for in a agent focused model.
The Misses
Not enough
Much of the initial excitement faded as users began experiencing it firsthand. Expectations were sky-high from Llama 4, but recent releases have genuinely raised the bar for what’s possible, leaving people disappointed. Both model have grossly underperformed their peers.
The initial reaction from Teortaxes

And also

The model struggled to score 16% on the Aider Polyglot benchmark, which is fairly respected and consists of coding problems from multiple languages on different tasks.
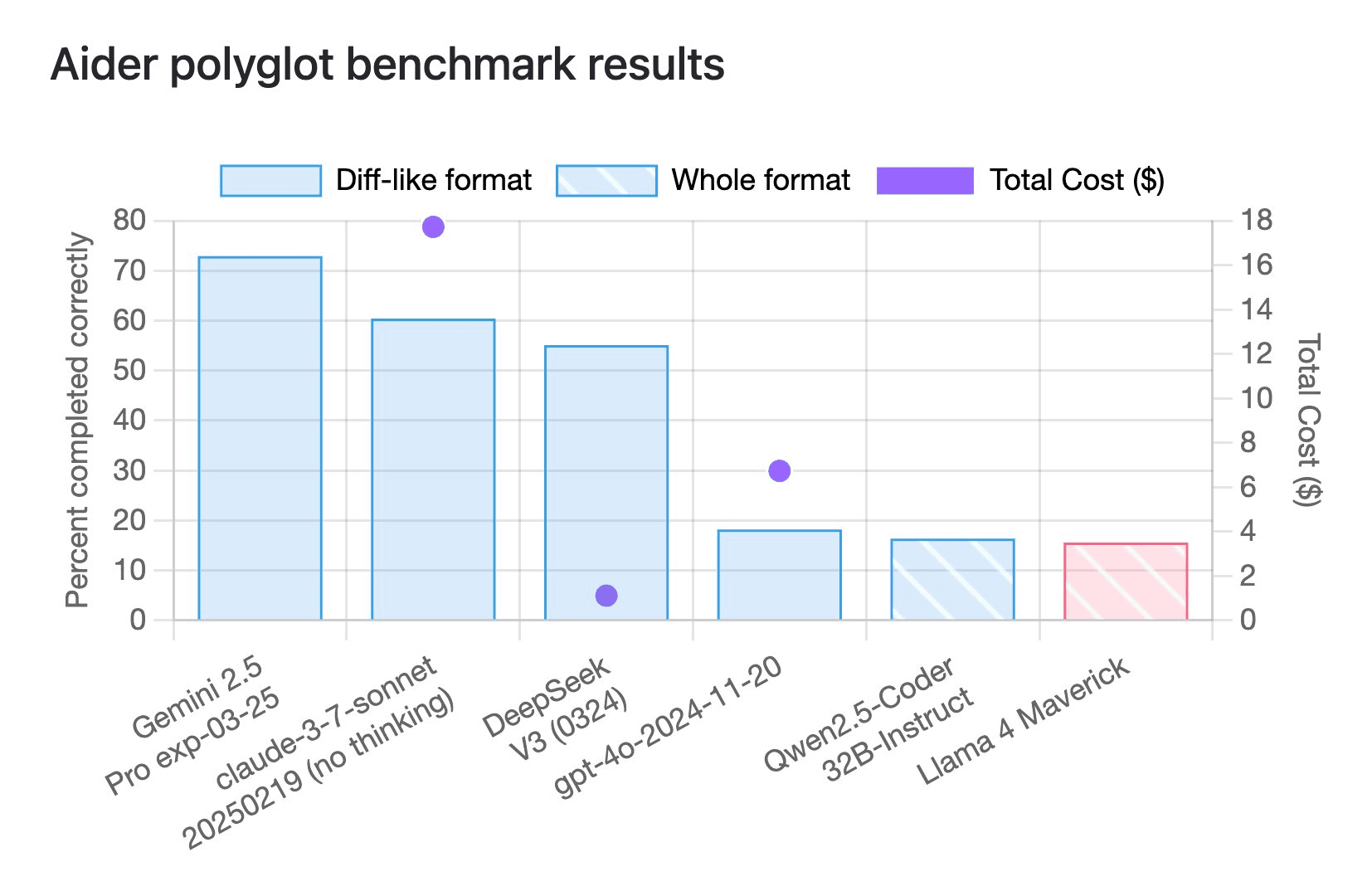
It's scoring around Qwen 2.5 coder, even being 10 times the model, doesn't instil confidence. Coding is definitely not its strongest suit.
The models are also grossly underperforming on long-form writing benches.
Sam Peach: I made a new longform writing benchmark. It involves planning out & writing a novella (8x 1000 word chapters) from a minimal prompt. Outputs are scored by sonnet-3.7. Llama-4 performing not so well. :~(

Llama 4 models are even underperforming QwQ-32b and Reka Flash 3. It seems it's not good at creative writing, either.
Confused Positioning
Confused positioning: it's neither very cheap nor brilliant compared to peers.
Theo: Increasingly confused about where Llama 4 fits in the market
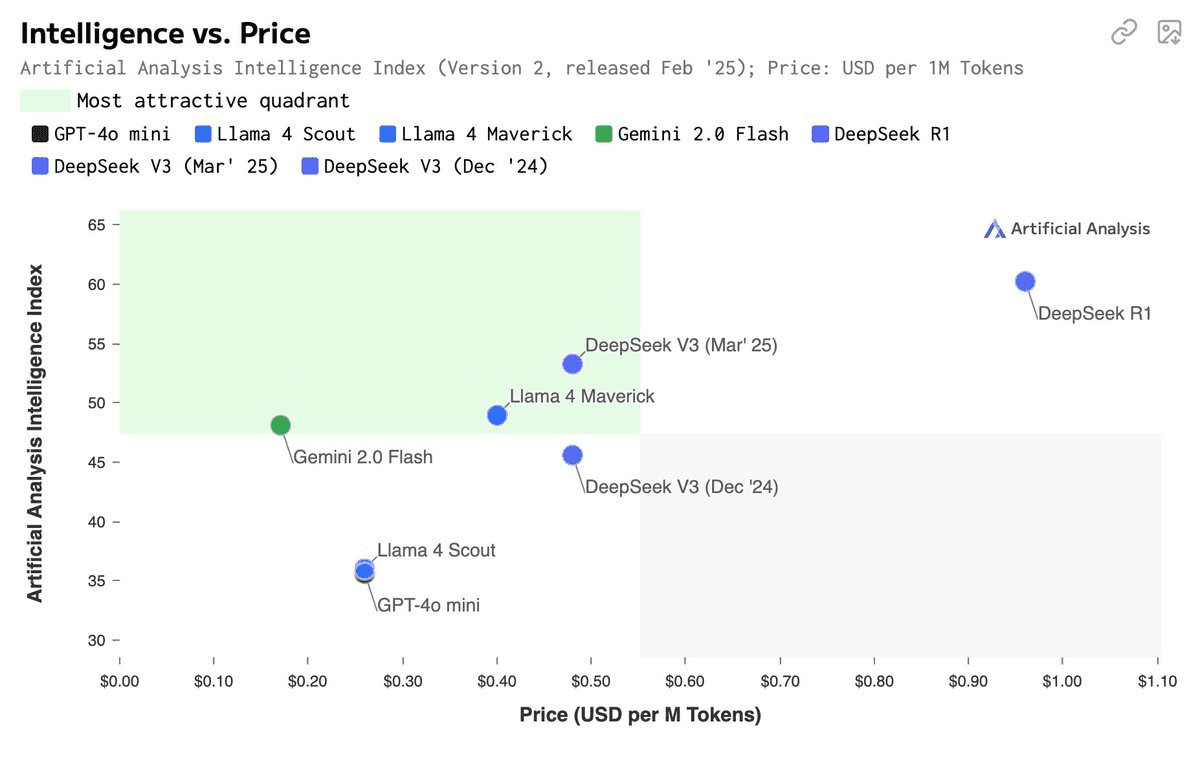
Not doing well on Arc AGI semi-private evals.
ARC-AGI: Llama 4 Maverick and Scout on ARC-AGI's Semi Private Evaluation
Maverick:
* ARC-AGI-1: 4.38% ($0.0078/task)
* ARC-AGI-2: 0.00% ($0.0121/task)Scout:
* ARC-AGI-1: 0.50% ($0.0041/task)
* ARC-AGI-2: 0.00% ($0.0062/task)
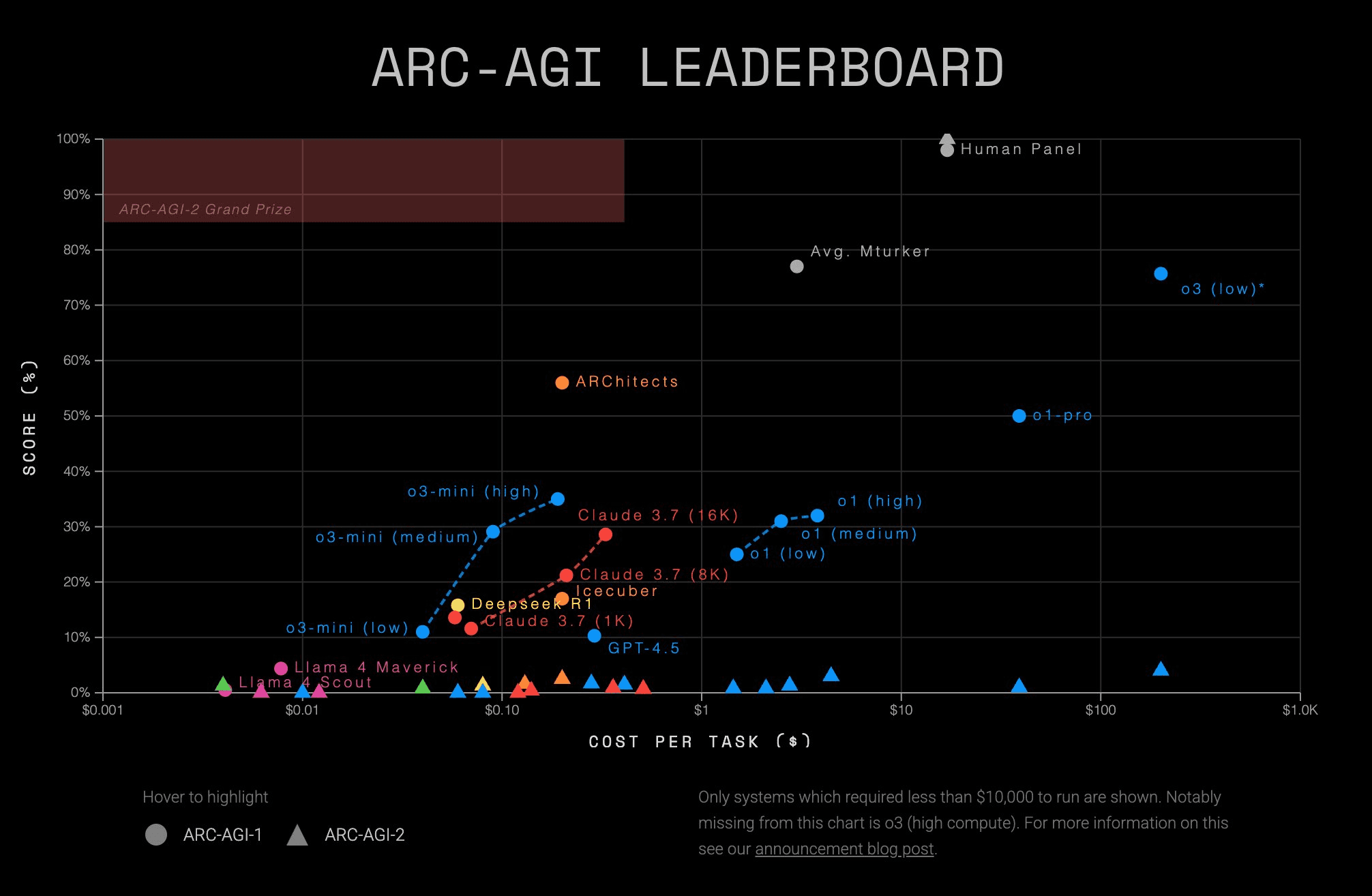
The scores sure are not very encouraging.
The Disasters
There have been some serious issues with the Llama 4 launch, and the situation is terrible.
Not really 10M
The least serious issue is that the claim of a 10m context window is not really true. The model's performance tends to get worse as the context length increases.
Ivan: It's impossible for Llama-4 to degrade so much at 120k context. How can a big AI lab like Meta push a 10M limit in their announcement and have such poor real-life results? I hope there are bugs somewhere causing this.
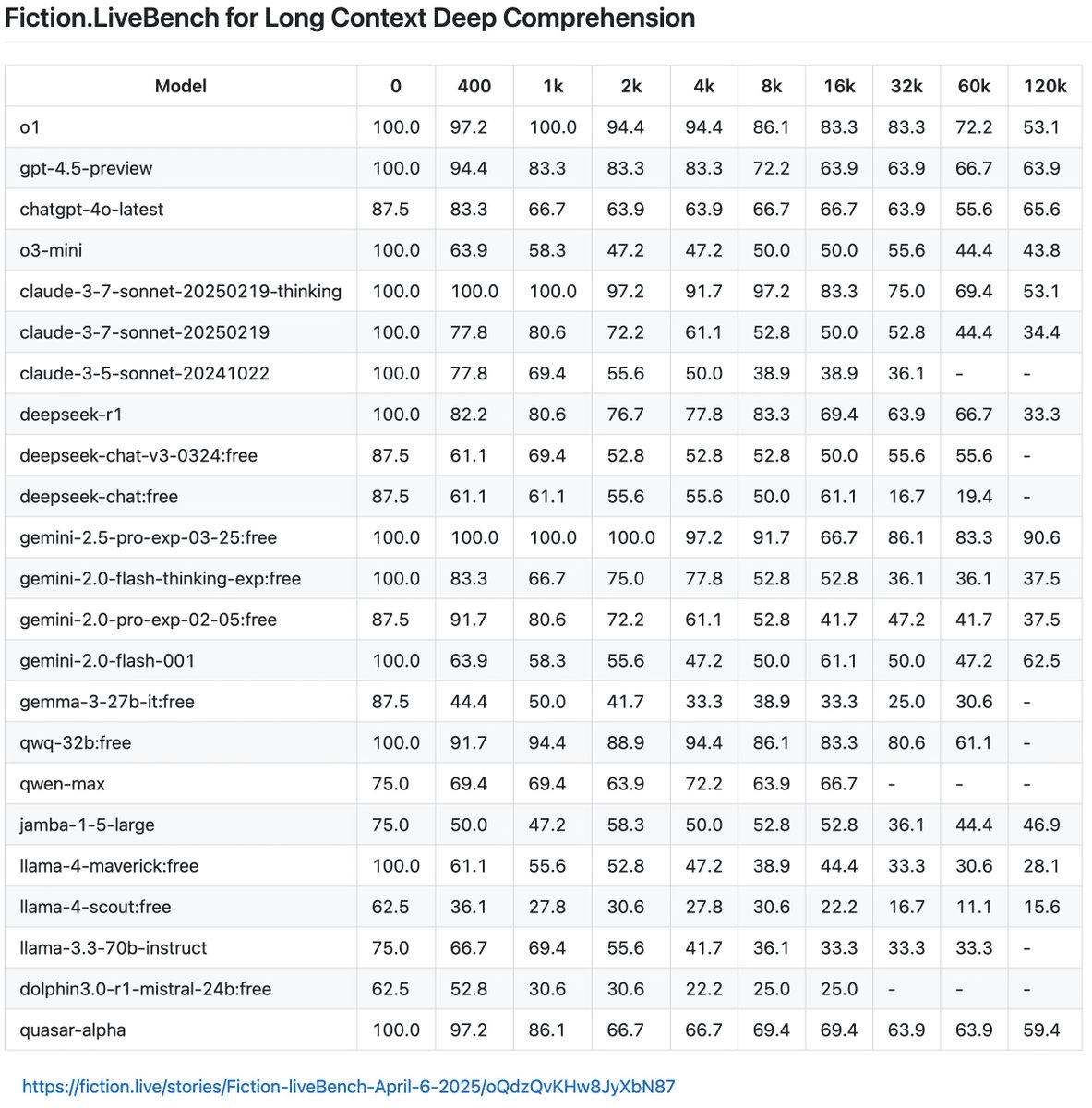
Llama 4 models on LiveCodebench
Benchmark Blunders
Surprisingly, the biggest highlight of this launch wasn't model performance but the Lmsys benchmark blunder. Many Llama and open-source enthusiasts pointed out the mismatch between the Lmsys ELO rating and model performance.
Did Meta game the benchmark? No, not really.
They have explicitly mentioned in their release blog that they have released an experimental version of Llama 4 Maverick optimised for human conversations.
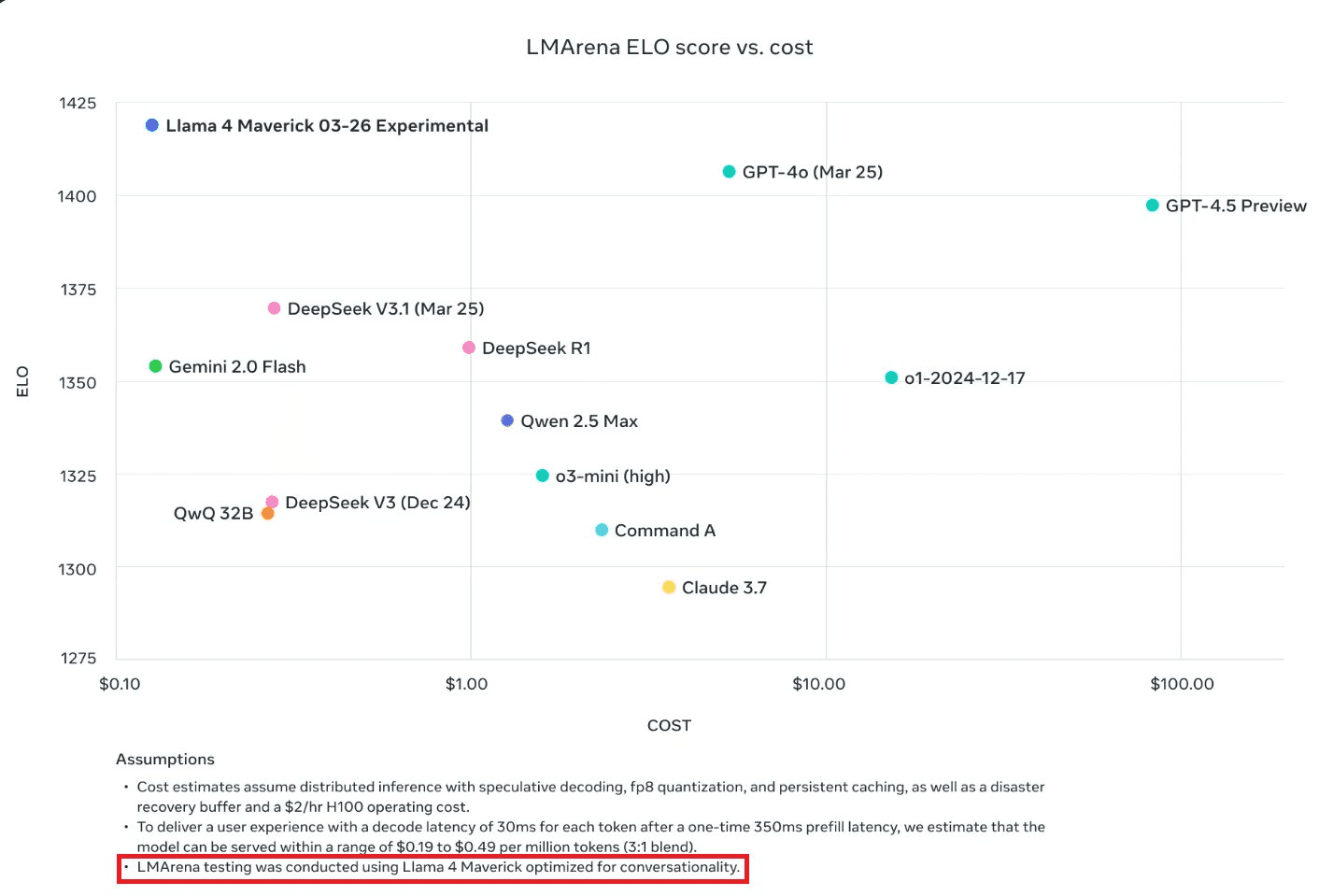
Ahmad Al Dahl, the lead at GenAI Meta, clarified the model.
We're glad to start getting Llama 4 in all your hands. We're already hearing lots of great results people are getting with these models. That said, we're also hearing some reports of mixed quality across different services. Since we dropped the models as soon as they were ready, we expect it'll take several days for all the public implementations to get dialed in. We'll keep working through our bug fixes and onboarding partners. We've also heard claims that we trained on test sets -- that's simply not true and we would never do that. Our best understanding is that the variable quality people are seeing is due to needing to stabilize implementations. We believe the Llama 4 models are a significant advancement and we're looking forward to working with the community to unlock their value
It turns out that the model release was rushed, and there are many rough edges that Meta didn't bother fixing before the launch.
However, this also highlights the shortcomings of the LMSYS arena for LLM evaluations. In response to community questions, they released a statement.
Lmsys: We've seen questions from the community about the latest release of Llama-4 on Arena. To ensure full transparency, we're releasing 2,000+ head-to-head battle results for public review. This includes user prompts, model responses, and user preferences. (link in next tweet)
Early analysis shows style and model response tone was an important factor (demonstrated in style control ranking), and we are conducting a deeper analysis to understand more! (Emoji control?)In addition, we're also adding the HF version of Llama-4-Maverick to Arena, with leaderboard results published shortly. Meta’s interpretation of our policy did not match what we expect from model providers. Meta should have made it clearer that “Llama-4-Maverick-03-26-Experimental” was a customized model to optimize for human preference. As a result of that we are updating our leaderboard policies to reinforce our commitment to fair, reproducible evaluations so this confusion doesn’t occur in the future.
Interestingly, evaluators prefer lengthy and modified responses from the Llama 4 Maverick in all the head-to-head examples. This is one such example where Llama 4 was the winner.

The model output is more tuned to please human readers, and Lmsys tends to like it.
Ethan Mollick: The Llama 4 model that won in LM Arena is different than the released version. I have been comparing the answers from Arena to the released model. They aren't close. The data is worth a look also as it shows how LM Arena results can be manipulated to be more pleasing to humans.
Here's what Susan Zhang has to say on the same thing
Susan: how did this llama4 score so high on lmsys?? i'm still buckling up to understand qkv through family reunions and weighted values for loving cats...
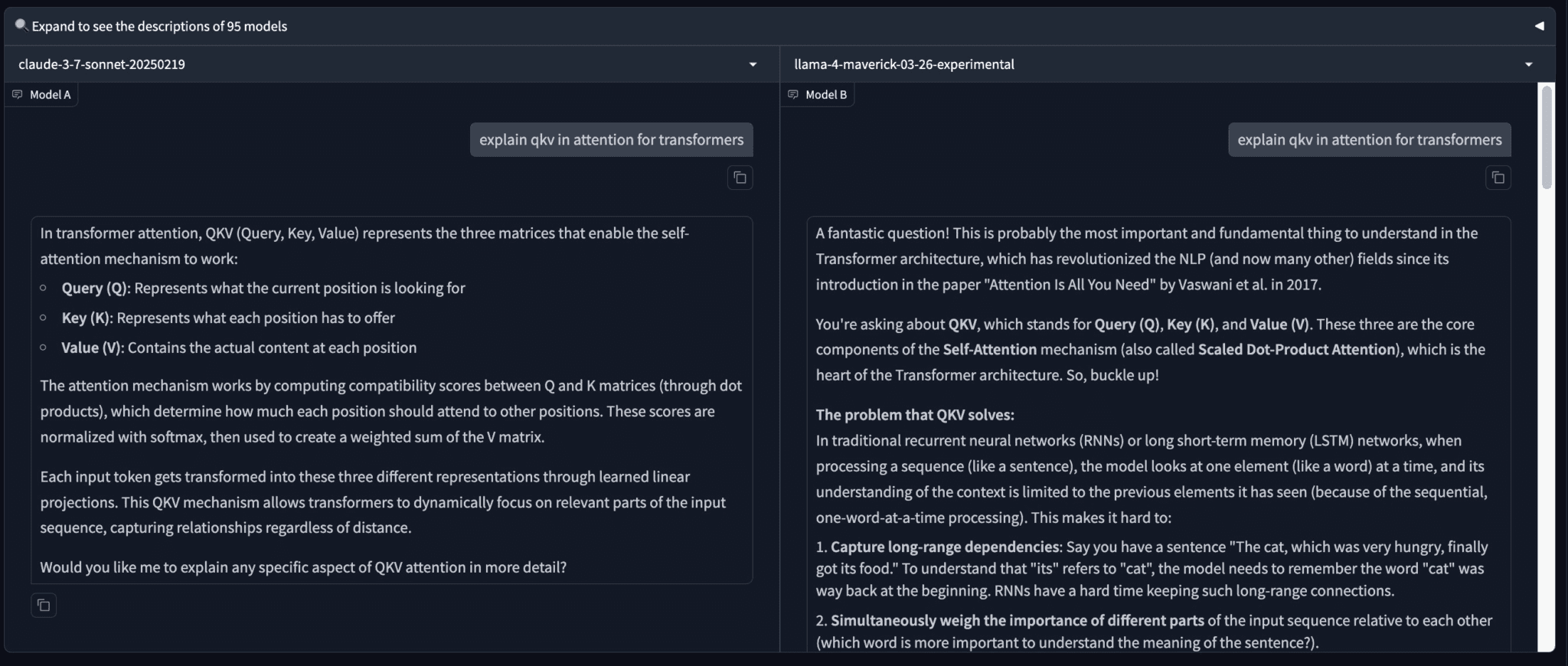
So, I don't know if it is an LLM problem or a benchmark problem.
Vik: This is the clearest evidence that no one should take these rankings seriously. In this example it's super yappy and factually inaccurate, and yet the user voted for Llama 4. The rest aren't any better.
This gets even worse: a former Meta employee took it to Reddit and posted how Meta has manipulated the Lmarena benchmark.

As a Llama enthusiast, this was my 9/11. It's OK if the model underperforms, but not being honest is a crime before the gods.

The tokenizer terror
The woes don't end here. The tokenizer scene is even more grim.
Kalomaze: if at any point someone on your team says
"yeah we need 10 special tokens for reasoning and 10 for vision and another 10 for image generation and 10 agent tokens and 10 post tr-"
you should have slapped them this is what happens when that doesn't happen
Minh Nhat Nguyen: do not go into the llama tokenizer dot json. worst mistake of my life

There still hope
It's not all gone. There is still hope for redemption. The Behemoth 2T model can partially redeem their lost reputation. But for a 2T model, it has to be as good as the Grok 3 at the very least, or else it'd be over for Meta and Llama.
But there is hope,
