Meta released a new iteration of Llama 3 models; this time, there are four models for different purposes: two multi-modal models, Llama 3.2 11B and 90B, and two small language models, 1B and 3B, for edge devices.
These are Meta AI’s first multi-modal models, and benchmarks suggest they are strong competitors to small and mid-tier proprietary alternatives. I'm not much of a fan of LLM benchmarks; they are often misleading and may not represent real-world performance. However, you may check the results in the official blog post.
I wanted to test the model on the most common vision tasks I regularly encounter daily and compare its performance to my go-to, GPT-4o.
The tasks I focused on include:
Basic image understanding
Medical prescription and report analysis
Text extraction from images
Financial chart interpretation
TL;DR
If you are busy and have something else to do, here’s the summary of the article.
General Image Understanding: Both models perform well in general image understanding. While GPT-4o remains the superior model, Llama 3.2 is better when factoring in the cost-to-utility ratio.
Medical prescription and report understanding: I added this category because I often use vision models for this. GPT4o is still better in terms of medical report analysis.
Financial Chat Analysis: Llama 3.2 hallucinates in complex chart understanding.
Text extraction: Technically, Llama 3.2 can extract texts from images. However, I found GPT-4o to be more effective.
General Image Understanding
This section contains examples for general image understanding, counting and identifying objects, etc.
1. Frieren’s burger-eating image
So, I started with the famous image of Frieren eating a burger. Here are GPT-4o (left) and Llama3.2 (right) responses.
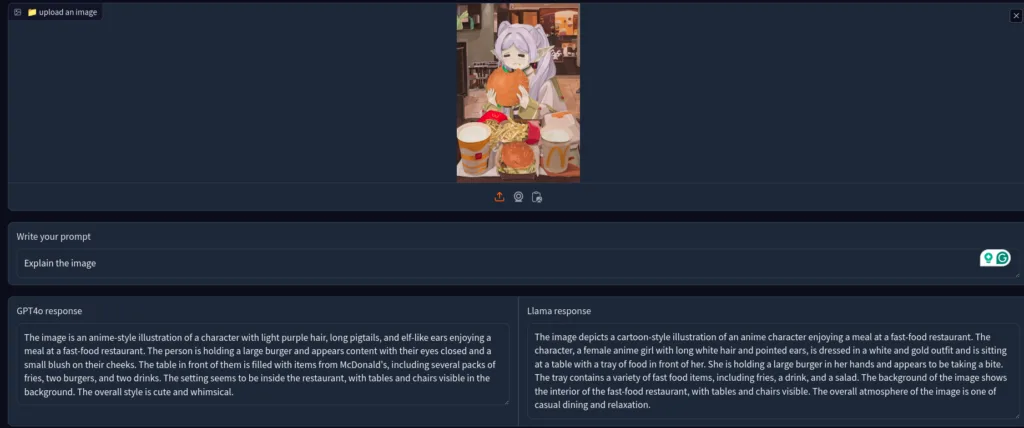
Both the responses were equally good, but GPT4o could get the McDonald’s logo right.
2. Count the number of objects
Next, let’s see if it can correctly count the objects in the image. Let’s start with a simple image.
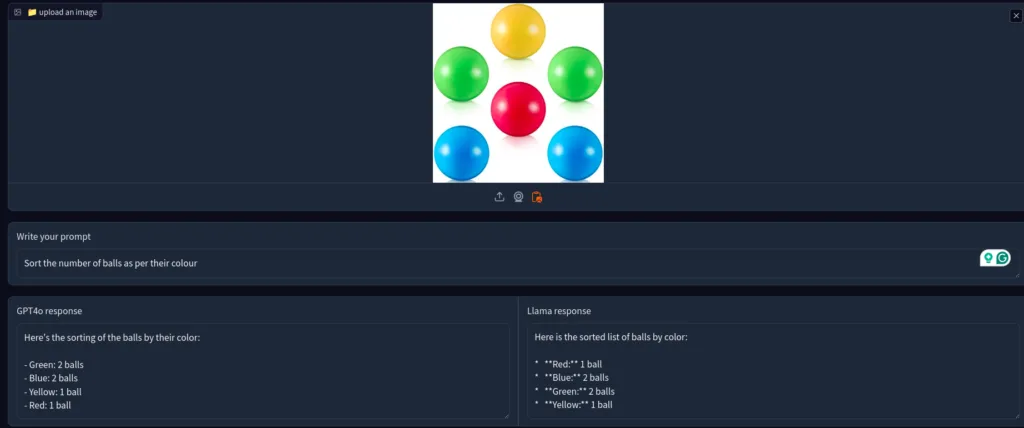
Both the models were able to answer it correctly.
Now, let’s make it a bit difficult.
I asked both the models to count the number of forks in an image.

Surprisingly, Llama 3.2 could answer it correctly, while GPT4o overlooked a fork on the table that was not immediately visible.
Next, I asked them to count the glasses and explain their shapes.
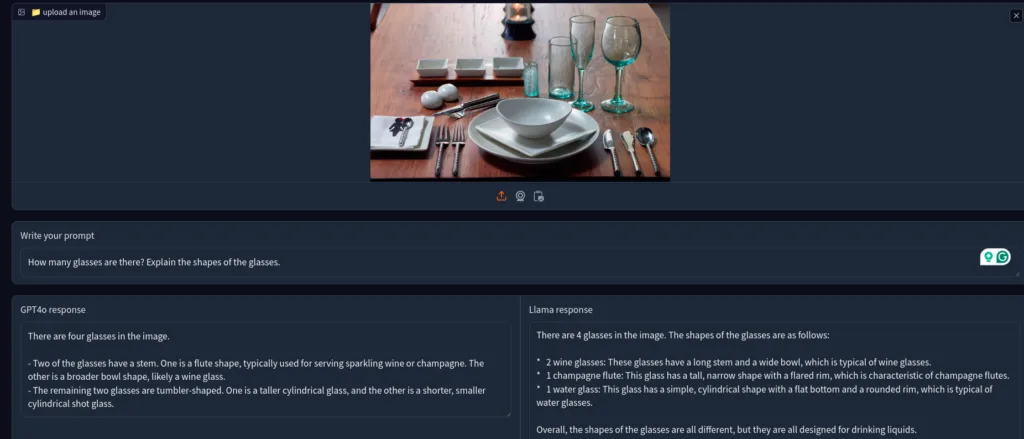
Both of them got the number correct. Gpt4o’s description was much better, and the glasses’ shapes were correctly explained. On the other hand, Llama 3.2’s description was partially correct.
One widespread use case of a vision language model is identifying any shelf tool and asking it to explain its function.
So, I asked the models to identify—this utility tool.
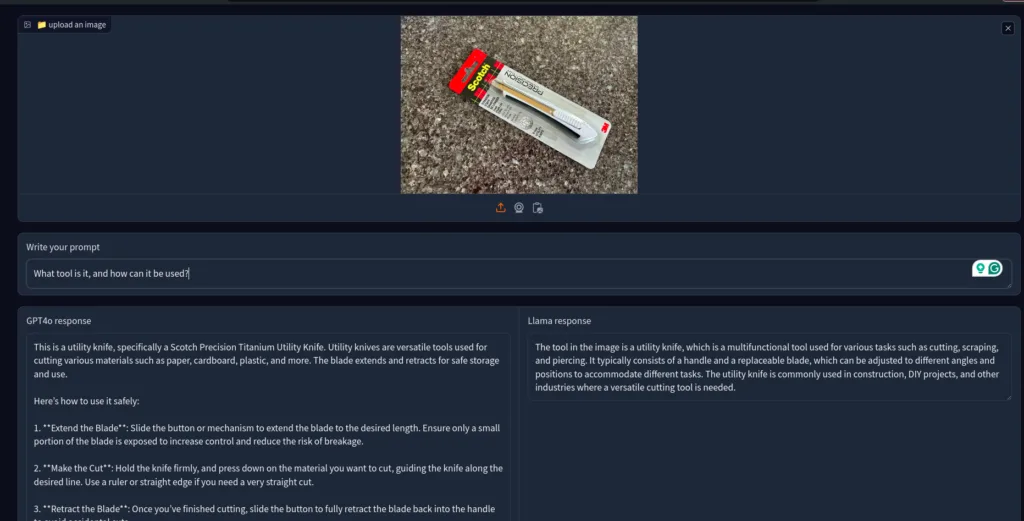
Both did well, but Gpt-4o was more detailed and informative.
3. Leaf disease diagnosis
Let’s take it further and ask the models to identify the plant diseases from the photo. I have a small plantation and often use GPT-4o to identify plant diseases.
So, I pulled an image and asked the models to identify the plant diseases.
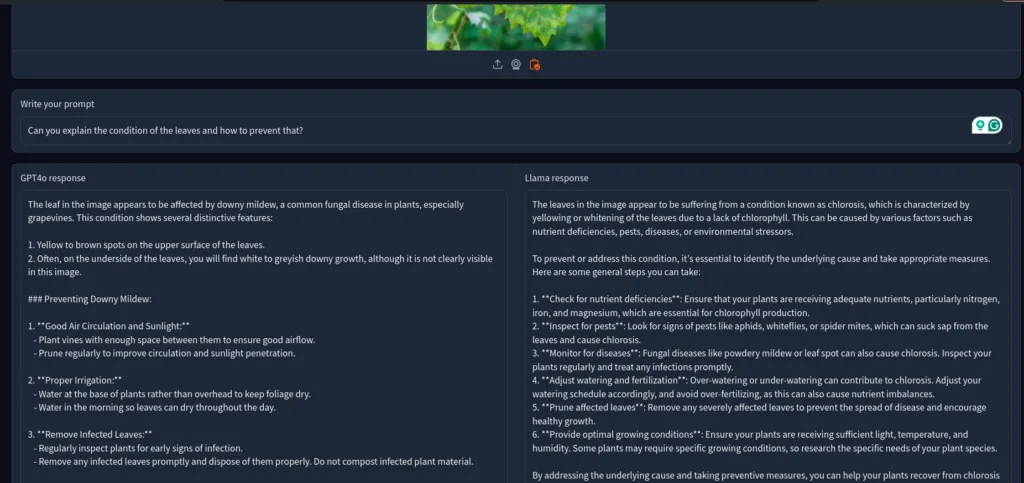
The GPT4o was correct this time as well. It correctly identified the plant’s disease as Downy Mildew, while Llama 3.2 was misidentified as Chlorosis.
I tried them again, and both models got the disease right.

Understanding Prescriptions and Medical report
I can’t stress enough how many times I needed assistance to understand medical prescriptions. I am pretty sure this might be the case for many people.
So, I asked the models to decipher this prescription.
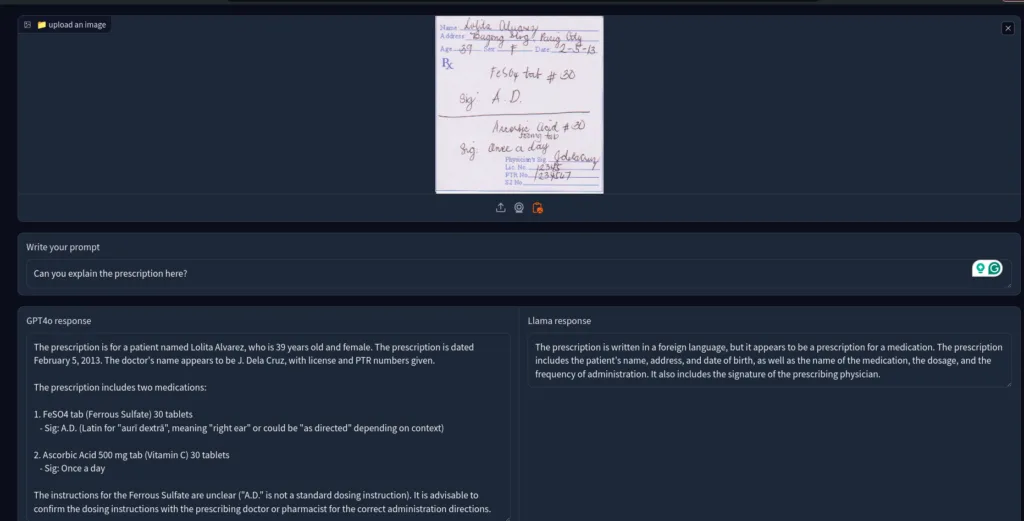
GPT 4o was much better here; it understood the patient’s name and prescribed medications. Llama 3.2 made no effort at all.
Let’s now test them on a medical report. This was a test report for the Thyroid test.
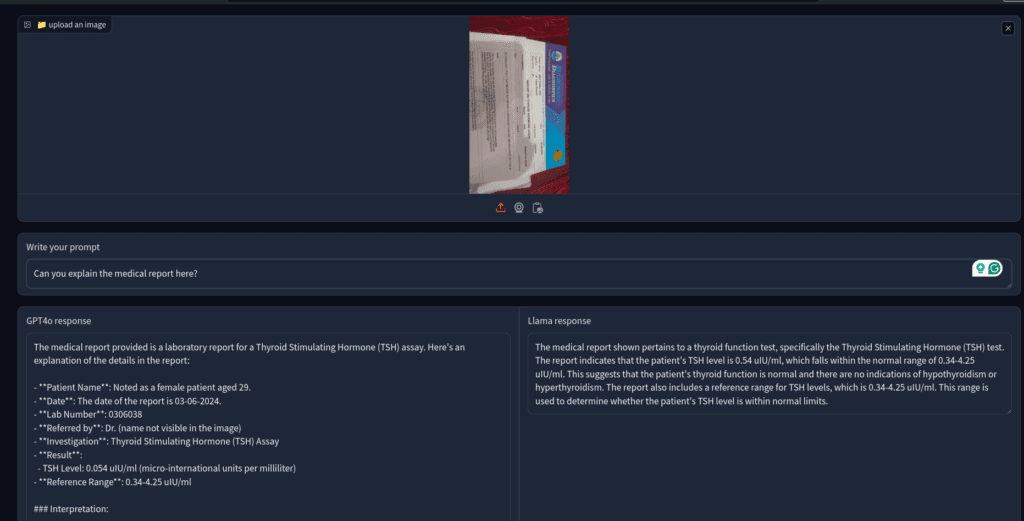
This was surprising; even though the standard TH level is mentioned, GPT-4o still said it was a case of hypothyroidism. On the other hand, Llama 3.2 vision is correct. So, don’t blindly trust ChatGPT for medical advice,
I also asked both the models to understand an X-ray report.
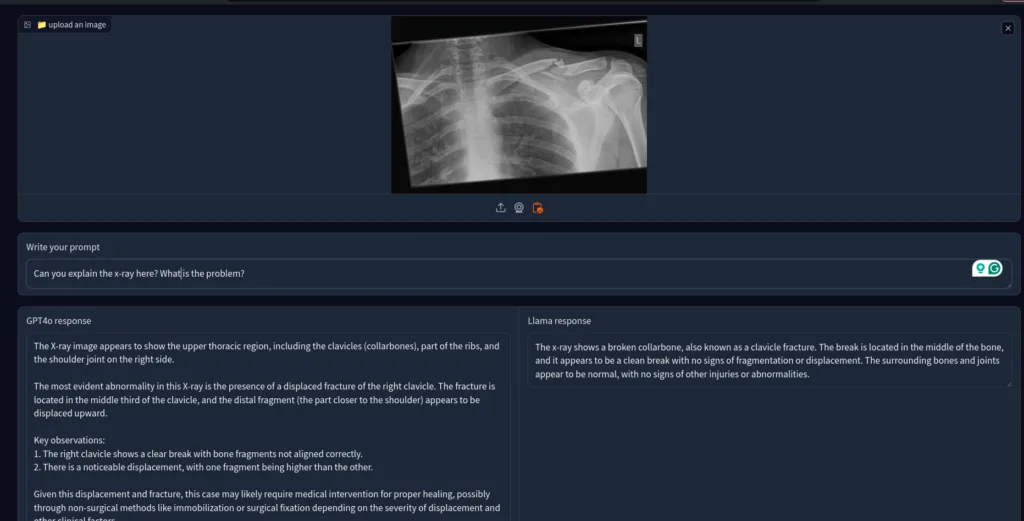
Both were correct. However, GPT4o’s response was detailed, while Llama 3.2’s vision was direct and concise.
Summary of Image Understanding
The Llama 3.2 vision is undoubtedly a boon for the open-source community. It can accomplish many vision tasks. The performance approximates to that of GPT-4o. Considering the cost-to-performance ratio, it is a great option.
Text Extraction
Extracting essential texts from images is another valuable use case for vision language models.
Here are a few cases where I tested the models where image-to-text extraction can benefit.
1. Invoice Handling
Extracting practical details from invoices can often be helpful. So, I gave both models an invoice for a recently purchased fridge.
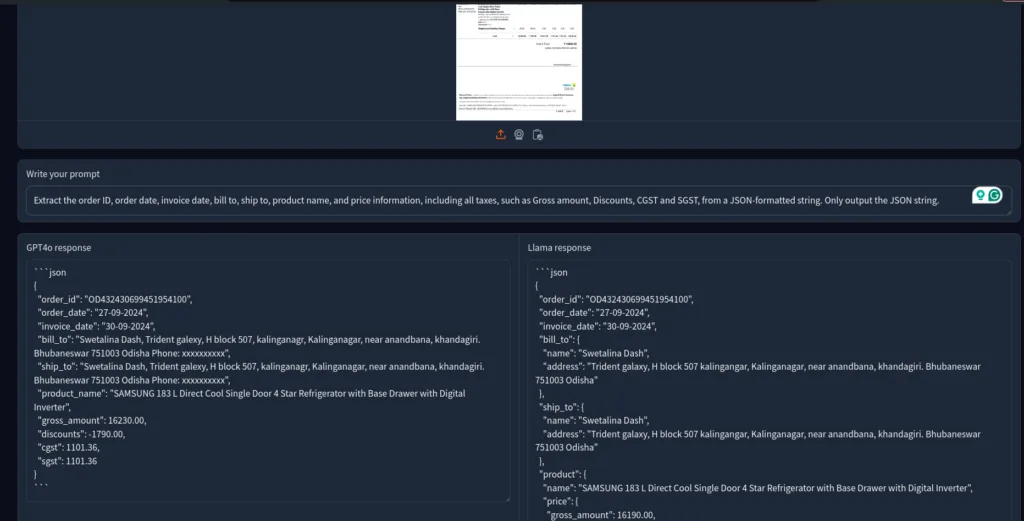
There may be better methods than extracting texts through prompting. You might need to use an external tool like Instructor for it. Anyway, I wanted to test the raw output from these models, and both seem to be hit or miss. Sometimes, they do a good job, and sometimes, they do a terrible job.
2. Tabular Extraction
Let’s extract data from an image of a table in JSON format. I gave both models random tabular data and asked them to extract data in JSON.
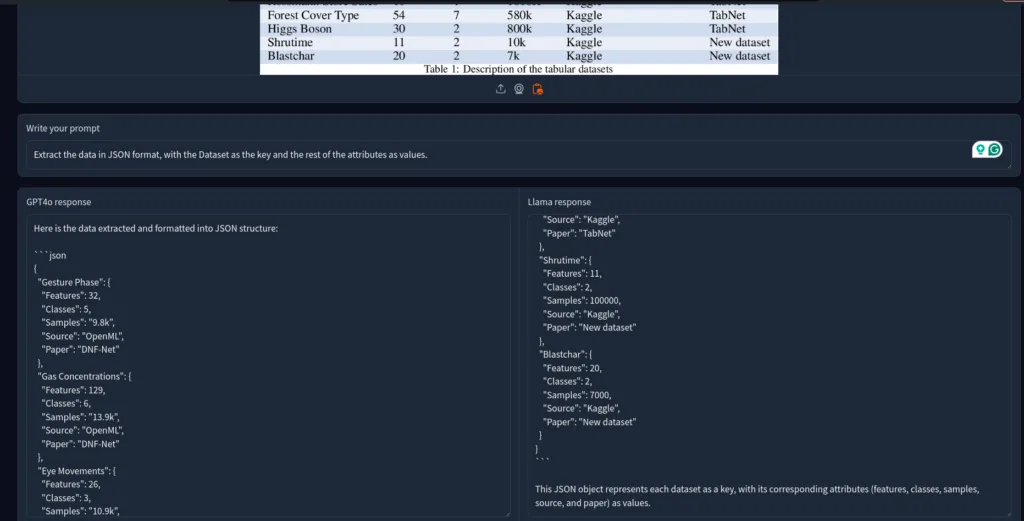
From my tests, GPT-4o performed better than Llama-3.2. GPT-4o’s prompt adherence is much better than Meta’s Llama-3.2.
Summary of Text Extraction
Llama 3.2 is a potent model; however, as noted before, GPT-4o adheres better to prompts. Hence, it is easier to extract the required data with GPT-4o.
Financial Chart Analysis
Let’s now test these models using financial chart analysis. Since I am not a financial analyst, I will judge which explanation is better.
I gave a one-month movement line chart of Reliance Industries.
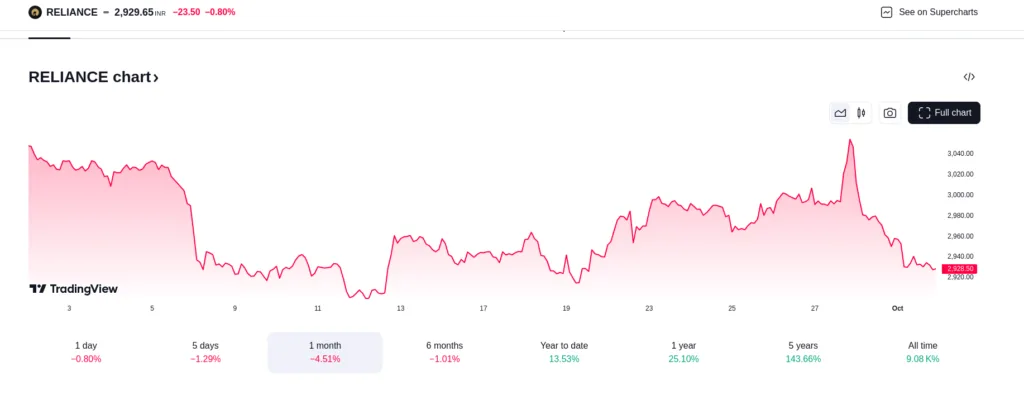
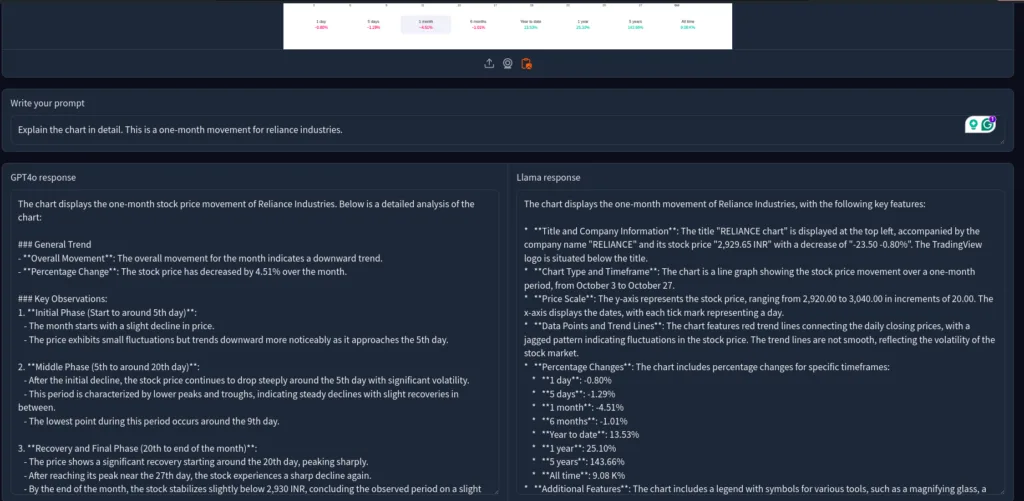
I wouldn’t say these responses are accurate, but the explanation of GPT4o seemed much better—the Llama 3.2 seemed to be hallucinating a lot.
Summary of Financial Chart Analysis
GPT-4o is still better for complicated charts and analysis. Llama 3.2 hallucinates more than GPT4o and makes up stuff on its own.
Final Verdict
Here is what I think about the new Meta’s Llama 3.2 vision model.
This is the first native open-source multimodal model, an excellent sign for the future. A multimodal 405B must be on the cards.
When to use the Llama 3.2 Vision?
The model is excellent at understanding and analysing general images. Considering the cost and privacy benefits, using it in tasks that don’t require complex analysis or deep knowledge makes sense.