Llama 4 Maverick and Llama 4 Scout are the latest additions to Meta’s Llama herd. The Maverick is a 400B sparse model with 17b active parameters and 128 experts, and the Scout is a 109b model with 17b active parameters and 16 experts.
The Maverick is in the same category as Deepseek v3, which has 685b total and 37b active parameters. It is worth knowing which one is a better open-source model.
I have compared both models regarding coding, reasoning tasks, creative writing, and long-context retrieval.
Check this out for Deepseek v3 0324 vs. Claude 3.7 Sonnet
So, let’s go.
TL;DR
If you want to jump straight to the result, here’s a quick summary of how these two compare in coding, reasoning, writing, and large context retrieval:
Coding: DeepSeek v3 0324 is far better than Llama 4 Maverick for coding.
Reasoning: DeepSeek v3 0324 is better at common sense reasoning than Llaama 4 Maverick.
Creative Writing: Both models are great at writing. You won’t go wrong choosing either of them. However, Llama 4 Maverick writes more detailedly, while DeepSeek v3 0324 writes more casually.
Large Context Retrieval: Llama 4 Maverick finds information from a large data set. It’s not perfect, but it's better than DeepSeek v3 0324.
Brief on Llama 4 Maverick
You can find a detailed breakdown here: Llama 4: Notes on Llama 4: The Hits, the Misses, and the Disasters.
Meta’s AI models were recently released, including two released models, Llama 4 Scout and Llama 4 Maverick, and the third one, Llama 4 Behemoth, which is still in training.

Llama 4 Scout is interesting. It features a 10M token context window, which is by far the highest of all the AI models so far. But since we are mostly interested in the Maverick variant, is Scout maybe something worth covering in future articles? Let me know.
Llama 4 Maverick has 17B active parameters and a 1M context window. It is a general-purpose model built to excel in image and text understanding tasks, making it a solid choice for chat applications or assistants in general.
Now, it's clear that this model is more of a general-purpose model. Here's a benchmark that Meta has published, an LMArena ELO Score comparing it with recent AI models, which shows it's beating all the AI models, not just in performance but also in pricing, which is super cheap ($0.19-$0.49 per 1M input and output token).

Here’s the Aider polyglot benchmark to compare how good this model is at coding:
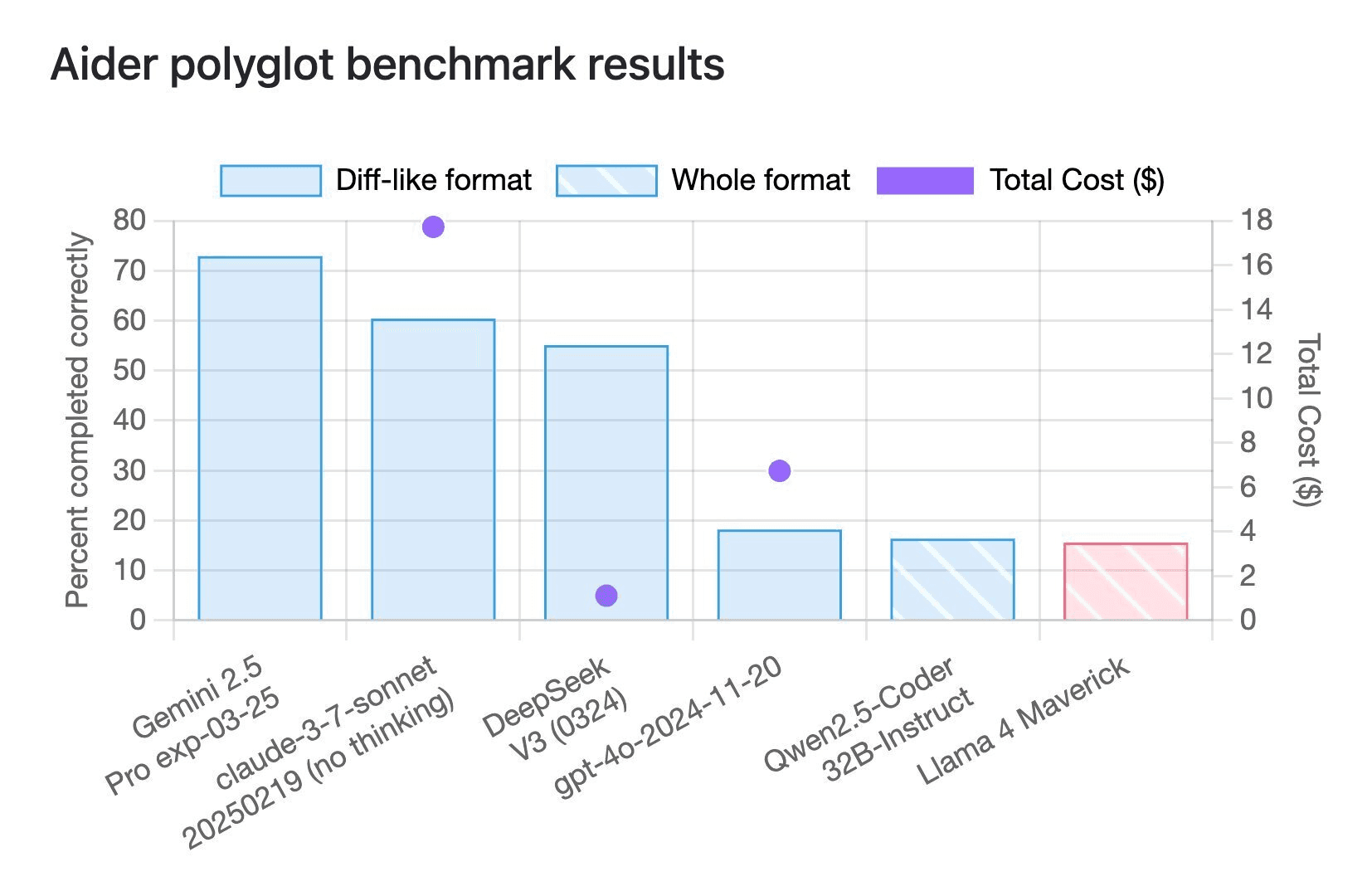
And fair enough, this model does not seem to be very good at coding, as we can see in this benchmark, it stands at the very least compared to any other recent AI models.
But we cannot overlook that this is just a 17B active parameter model that performs better than Gemma 3 27B, GPT-4o Mini, and almost the same as the Qwen 2.5 with 32B parameters, which is a coding model!
Here’s a quick video by Matthew Berman that you can watch to get more ideas on the Llama 4 models.
Let’s test Maverick with a slightly bigger model, DeepSeek v3 0324 (37B active parameters), in reasoning, coding, writing, and large context retrieval tasks to see if it is any good and if the benchmark justifies the response we get from Maverick.
Coding Problems
1. Sandbox Simulation
Prompt: Develop a Python sandbox simulation where users can add balls of different sizes, launch them with adjustable velocity, and interact by dragging to reposition them. Include basic physics to simulate gravity and collisions between balls and boundaries.
Response from Llama 4 Maverick
You can find the code it generated here: Link
Almost everything works, no doubt, but the physics of the ball collision is definitely not correct. Also, the ball should not be able to attach to the side walls, right? That completely breaks the logic, and the project's overall finish is also not great. I’d say it did the job correctly, but not perfectly.
Response from DeepSeek v3 0324
You can find the code it generated here: Link
Here’s the output of the program:
The output from DeepSeek v3 is promising. Everything works, and the fact that we can launch the ball from anywhere by dragging it on the screen makes it even better.
Everything about the project, from the ball physics to the UI, is perfect. I didn’t expect this level of perfection, but it's great.
Summary:
Llama 4 and DeepSeek v3 0324 both did what was asked. But if I were to compare the results between the two, I’d say the DeepSeek response is much better, with the physics of the ball and everything working perfectly.
2. Ball in a Spinning Hexagon
I know, I know, this is a pretty standard question, and they will quickly solve it, right? This time, I’ve asked it with a twist. I found that almost all the models seem able to solve it when asked to do it using p5.js, but nearly all of them fail when asked to do the same in Python. Let’s see if these two models pass this one.
Prompt: Create a Python animation of a ball bouncing inside a rotating hexagon. The ball should be affected by gravity and friction, and it must collide and bounce off the spinning hexagon's walls with realistic physics.
Response from Llama 4 Maverick
You can find the code it generated here: Link
As I guessed, this is a complete fail. The ball is not supposed ever to go outside of the hexagon and should keep spinning inside.
The twist is when I asked for this same task to be done in p5.js, it performed perfectly, but with Python, it has some issues with floating-point number precision or building the complete logic, but this is not the case.
Response from DeepSeek v3 0324
You can find the code it generated here: Link
Here’s the output of the program:
Summary:
It works just fine and even adds some extra features for interacting with the ball. The ball physics is correct, but the issue is that the hexagon speed itself is super slow, and even though a keymap has been added to rotate the hexagon, it simply does not work. Other than that, everything is fine and works perfectly.
3. LeetCode Problem
To me, it simply does not feel correct not to have a LeetCode question for a coding test. Why not end this test with a quick LC question?
For this one, I’ve picked a hard one with an acceptance rate of just 15.2%: Find the Largest Palindrome Divisible by K.
You are given two positive integers n and k.
An integer x is called k-palindromic if:
x is a palindrome.
x is divisible by k.
Return the largest integer having n digits (as a string) that is k-palindromic.
Note that the integer must not have leading zeros.
Example 1:
Input: n = 3, k = 5
Output: "595"
Explanation:
595 is the largest k-palindromic integer with 3 digits.
Example 2:
Input: n = 1, k = 4
Output: "8"
Explanation:
4 and 8 are the only k-palindromic integers with 1 digit.
Example 3:
Input: n = 5, k = 6
Output: "89898"
Constraints:
1 <= n <= 105
1 <= k <= 9
Response from Llama 4 Maverick
Sometimes, even Claude 3.7 Sonnet (a great coding model) has trouble correcting the logic for difficult LC questions and finishing within the expected time. I have no hopes, considering that we didn’t get a better response from Maverick in our previous questions.
You can find the code it generated here: Link
As expected, this was a complete failure. It couldn't even pass the first few test cases. I spent 15-20 minutes explaining how to solve this question correctly.
Even after all that iteration, it could only correct 10 out of 632 test cases. This model is a disaster for coding.
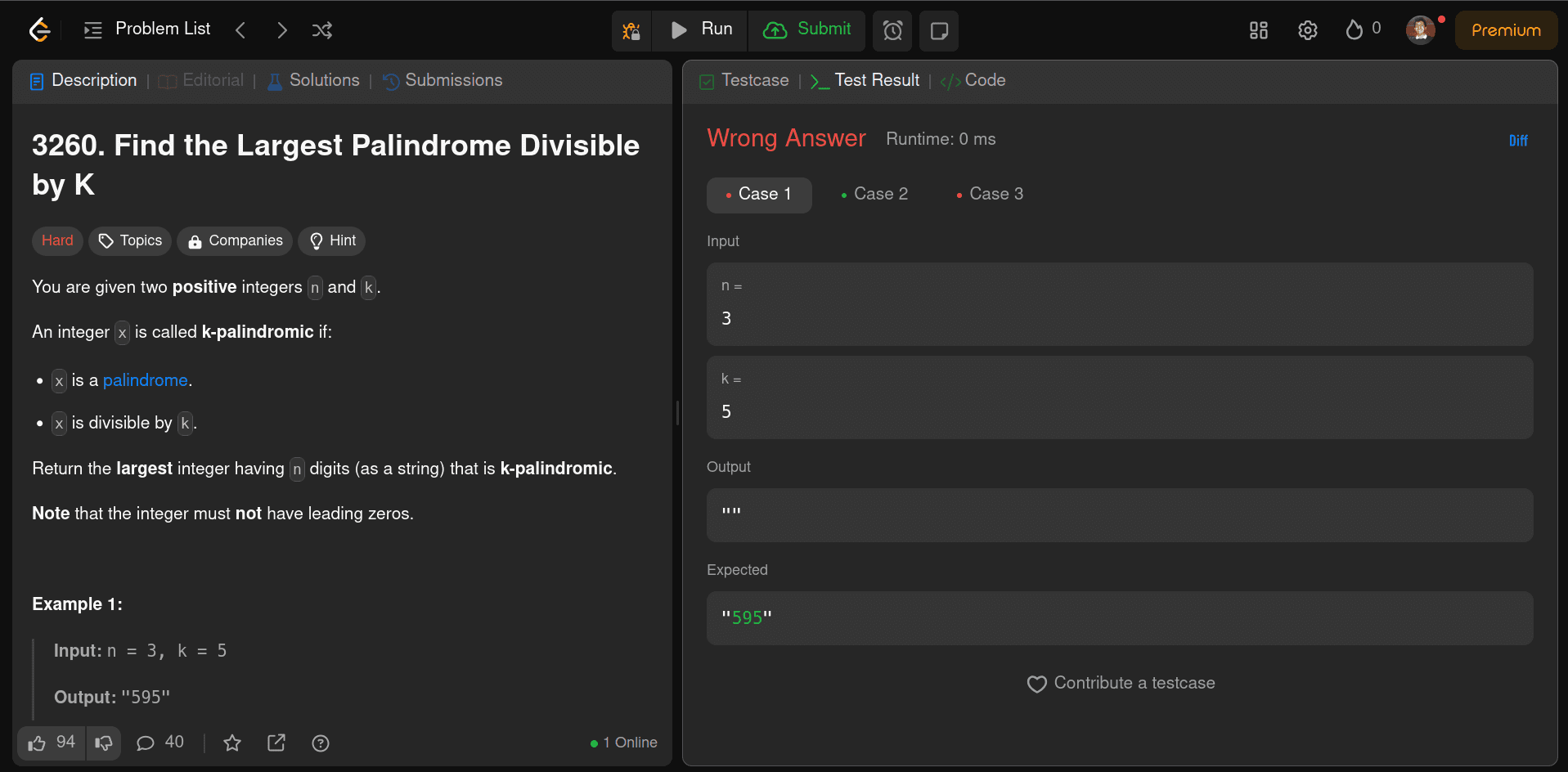
Response from DeepSeek v3 0324
You can find the code it generated here: Link
It was able to correct the logic but always ended up with a Time Limit Exceeded (TLE) error. It did pass 132/632 test cases, but here, we at least got the logic correct, considering nothing from the Llama 4 Maverick model.
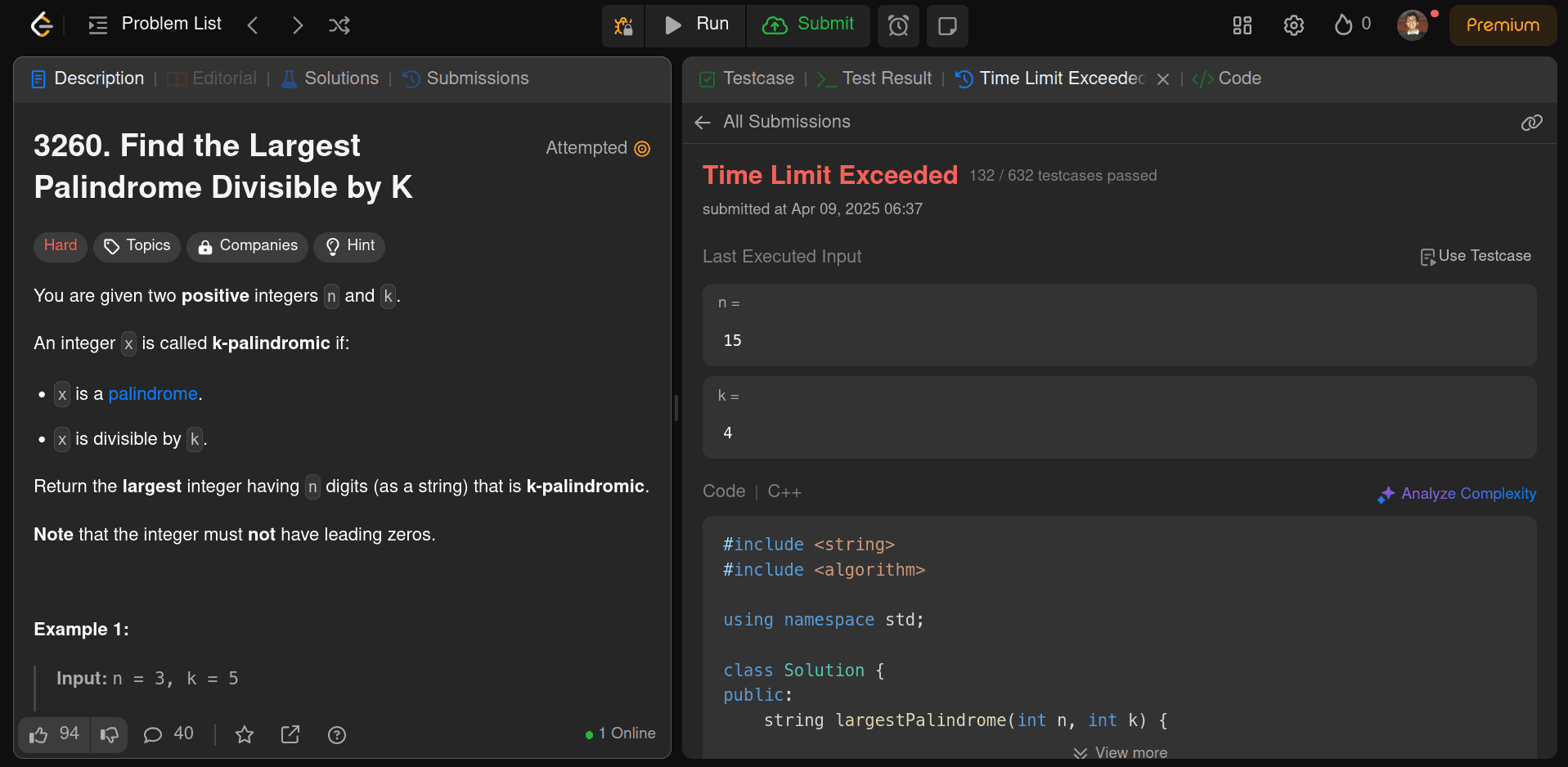
Summary:
At least we got something from DeepSeek v3 0324, even though it was not optimal, whereas Llama 4 Maverick gave us nothing and simply gave up. And even if I have to compare the code, DeepSeek was way better than Maverick.
Reasoning Problems
1. Equality Check
Prompt: Can (a==1 && a==2 && a==3) ever evaluate to true in a programming language?
This is a tricky question, and I basically want to see if these two AI models can figure out that we can use operator overloading supported in some languages to reason through this question.
Response from Llama 4 Maverick
You can find its reasoning here: Link

This time, it got it correct, reasoned it perfectly, and gave a working example of operator overloading in Java. Finally, I can see some good side to this model.
Response from DeepSeek v3 0324
You can find its response here: Link.

The same is true here. It got it correct and again provided a working example for Python and JavaScript. I learned something here. I didn’t know there was a dynamic object property access, and you can use it to achieve a similar result. I'm impressed!
Summary:
Both models got this question perfectly correct, and I even learned a JavaScript trick while testing the two models. What else could you expect, right?
2. Crossing Town in a Car
Prompt: Four people must pass a town in 17 minutes using a single car with two people. One takes 1 minute to pass, another takes 2 minutes, the third takes 5 minutes, and the fourth takes 10 minutes. How do they all pass in time?
Response from Llama 4 Maverick
You can find its reasoning here: Link

Again, this model did a great job of reasoning and arriving at the answer. There’s not much to say here; it quickly got this one correct, and that’s a plus.
I noticed that this model is super fast at generating responses, which is not something I’ve seen many models able to do.
Response from DeepSeek v3 0324
You can find the response here: Link
It also got this one correct with excellent reasoning and explanation. DeepSeek v3 0324 has been crushing almost everything we’ve tested so far. It seems to be a great model for both reasoning and coding.
Summary:
All in all, both models got the answer correct. However, I love how DeepSeek v3 0324 came up with the answer, providing a great thought process explanation compared to how Llama 4 Maverick reached the answer without much of a walkthrough.
Again, this is not a significant factor, but comparing how we received the response from both models is worth comparing.
Creative Writing
1. The Last Memory
Prompt: You wake up to find that someone you knew very well, a roommate, a best friend, maybe even a partner, has been 'deleted'. No one remembers them, but you do. You find one file left on your neural implant. Write a short and suspenseful ending to this story.
Response from Llama 4 Maverick
You can find its response here: Link
It wrote a great story with some story-building at the beginning, and overall, this was precisely what I was expecting. It was great, but I can’t say I’m impressed with the ending of the story it wrote. The main focus was supposed to be on the ending, but overall, it wrote a great story.
Response from DeepSeek v3 0324
You can find its response here: Link
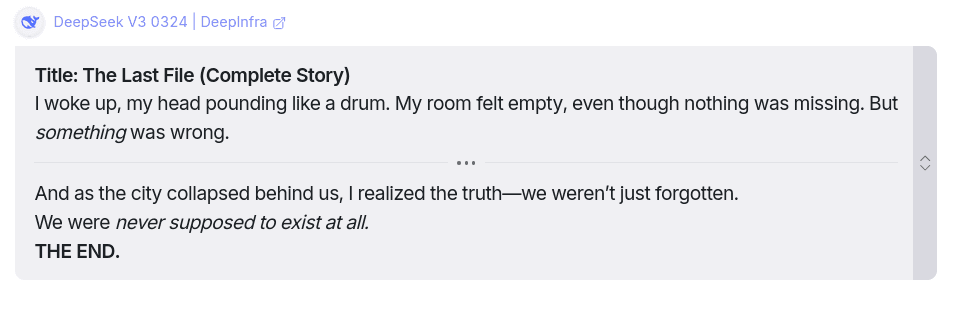
This one’s a banger. It did exactly what was asked. Even though it didn’t include much story-building, the ending sounded great. Make sure you take a read. You’ll be impressed by how well it wrote the ending, with a suspenseful twist in the last line.
Summary:
Both models are great at writing. Llama 4 Maverick wrote a great story with a nice story buildup, and DeepSeek v3 0324 wrote it in a more casual style but with a great ending. Feel free to choose either of these two models for writing, and you won’t go wrong with either.
Large Context Retrieval
This will be interesting. We’ll test the model’s ability to find specific information from an extensive data context. Let’s see how these two models manage this.1. Needle in a HaystackThe idea here is to provide a lorem ipsum input of over 100K tokens, place a word of my choice somewhere in the data and ask the models to fetch the word and its position in the input.
Prompt: Please process the upcoming large Lorem Ipsum text. Within it, a unique word starts with “word” and ends with “fetch.” Your task is to find this word, note its position, and count the total words in the text.
Response from Llama 4 Maverick
You can find the Lorem data here: Link, and the complete response here: Link

To my surprise, after thinking for about 16 seconds, it got the word correct, which is great. However, it couldn’t get the phrase position or the total number of words in the document.
Response from DeepSeek v3 0324
You can find the Lorem data here: Link and response Link
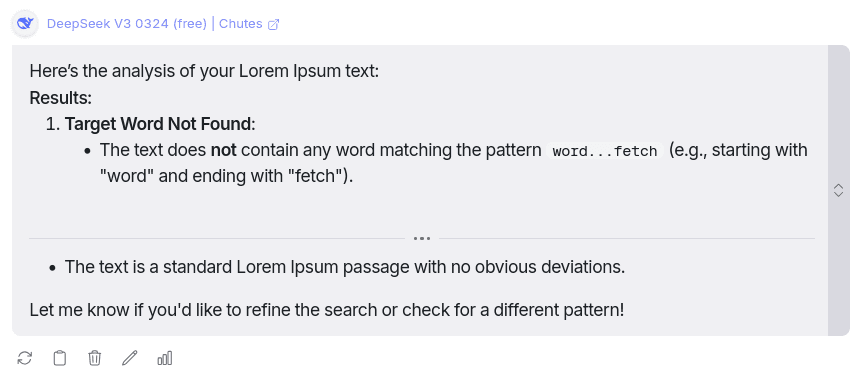
Sadly, even after thinking for ~18 seconds, it still couldn’t find the word or the total document word count. This isn’t very pleasant and not expected from this model.
Summary:
Llama 4 Maverick seems to have outperformed DeepSeek v3 0324 on this question. It may not be the best example, but finding small information from a large data context is the whole point of Large Context Retrieval.
Even though neither could get the word count and its position correct, Maverick at least got the word accurate.
2. Character Recall
I did another test to see if DeepSeek v3 0324 and Llama 4 Maverick could both answer it easily.
Here’s the data I used: Link
Here, the idea is to relate the context of something distant in the data. I’ve included some dummy paragraphs in the middle to make it more challenging to answer.
In this case, I asked:
What is the relationship between Alice and Dr. Grey?
And fortunately, both of them got it correct.
Llama 4 Maverick

DeepSeek v3 0324

Summary:
After the previous one, I was suspicious of the DeepSeek v3 0324 response and whether it would correct this one. However, this was easier, and thankfully, they got this question correct within ~2-3 seconds.
Conclusion
Llama 4 Maverick is in no way a model comparable to Deepseek v3 0324 for tasks like coding and reasoning;
It’s a strong model for writing, although it tends to favour lengthy texts.
1 Million context length is a massive plus for RAG and tool-calling tasks.
Again, strong Long Context Retrieval performance can be excellent for RAG-related tasks.
But for anything else, it isn’t good.
It would be interesting to see how the Behemoth turn out to be.