I was a huge Cursor Agent fan; unfortunately, my usage has declined to 0. All my coding has been delegated to two top-tier contenders, Claude Code and Codex. They started as terminal-based interfaces but have since become available in the cloud, on your phone, and as a desktop app.
I've spent hundreds of hours shipping production code and making tons of OSS contributions.
I've chatted with a lot of devs who are still deciding whether to go with Codex or Claude Code for daily use. After all, a $200 monthly commitment is a bit too much, and you don't want to regret the purchase.
Given that I have used both extensively for the past few months, I decided to write this blog post comparing the two coding harnesses. So, you get a good idea of where these two differ and which one to proceed with.
I did the comparison on the basis of
harness engineering,
model performance,
relevant features,
instruction-following, skills,
ecosystem
and pricing.
Everything below is as of June 2026; model capabilities are always subject to change.
So, let's go.
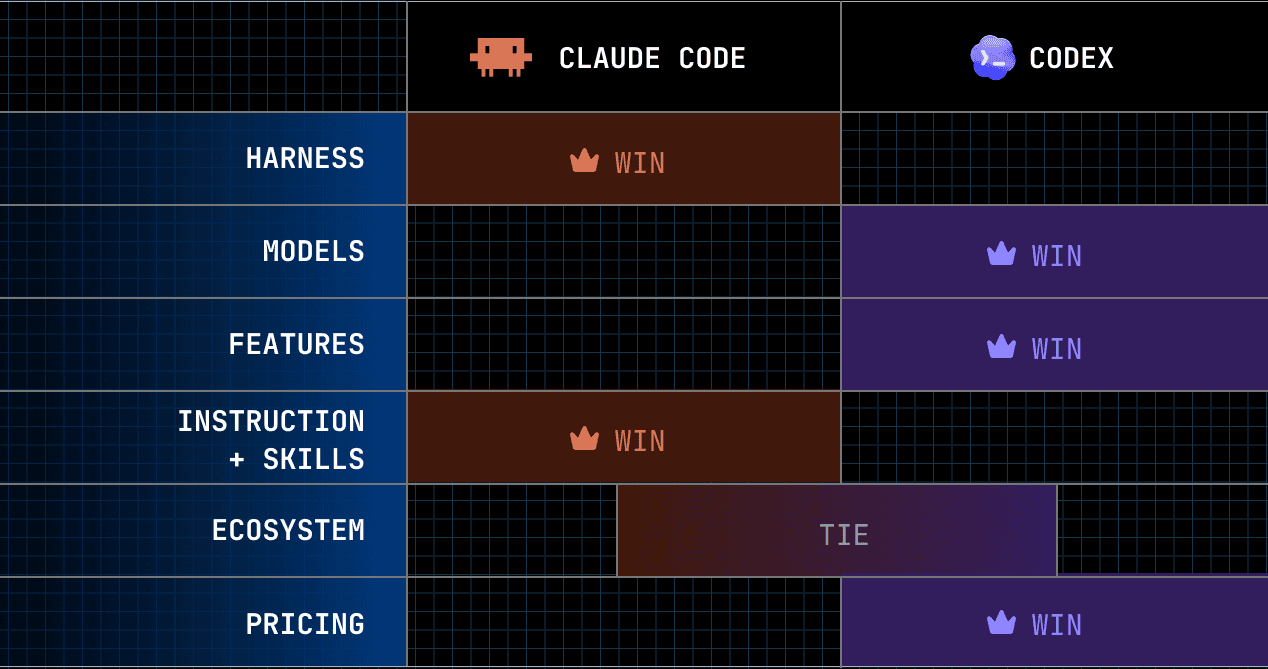
TL;DR
Section | Winner | Why |
|---|---|---|
Harness | Claude Code | Holds context better in long, tool-heavy sessions. When a tool gives a big output, it saves the full output to a file instead of truncating it |
Models | Codex | Opus 4.8 is smarter but tends to drain through usage limits quicker. GPT 5.5 is pretty cost-efficient and almost the same performance |
Features | Codex | Codex lets me fire off jobs to the cloud and /review gives a quick code review on demand |
Instruction following + skills | Claude Code | Codex sticks to instructions a little more reliably, but Claude has more skills specialized to its model |
Pricing | Codex | Doesn’t hit limits as fast with just a $20 plan. OpenAI has also trended toward loosening Codex limits while Anthropic's agent policy kept changing in recent months |
User Experience | Subjective | Claude Code CLI wins for me in simplicity and extensibility. But the Codex MacOS app is much cleaner and more polished than Claude AI |
In Summary
Codex wins what I deal with every day: steadiness, delegation, and more use for the same amount of tokens. Claude Code wins when you put in the work to set it up, use the harness during long sessions, and build a great skills ecosystem. Codex ultimately wins at a score of three to two, but it’s worth keeping both installed.
Related: OpenCode vs Claude Code
1 . Harness Engineering: Claude Code vs. Codex
The harness is what turns a model into a coding agent. The core loop is nearly identical on both:
while needs_follow_up:
1. Gather conversation history
2. Send to LLM with tools
3. Process response:
- If tool calls → execute them, add results, continue
- If just text → done with this turn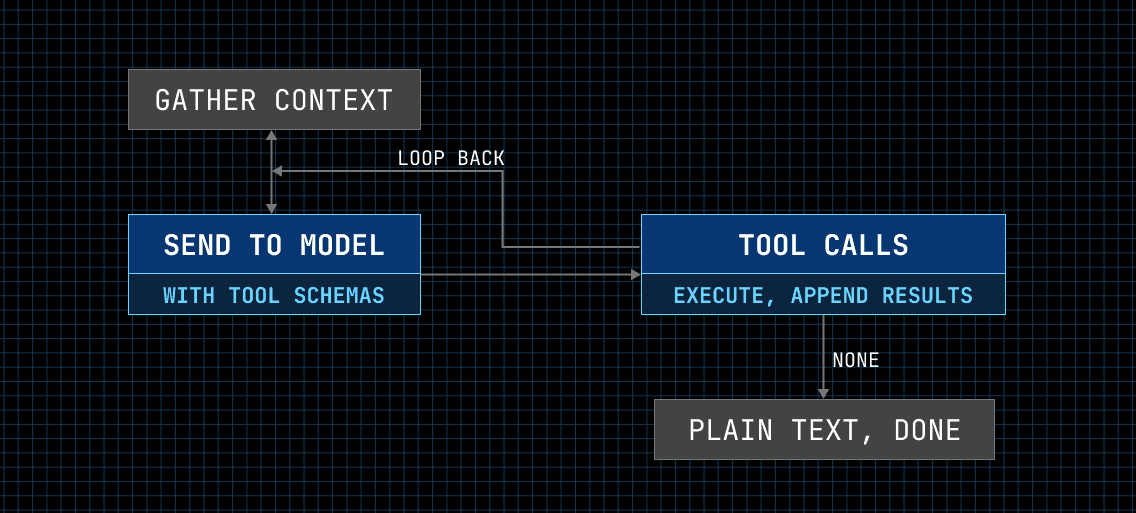
So the loop isn't where they differ. What makes a harness good or bad is the unglamorous stuff: context management, truncation, sandboxing, and error handling.
Claude Code | Codex | |
|---|---|---|
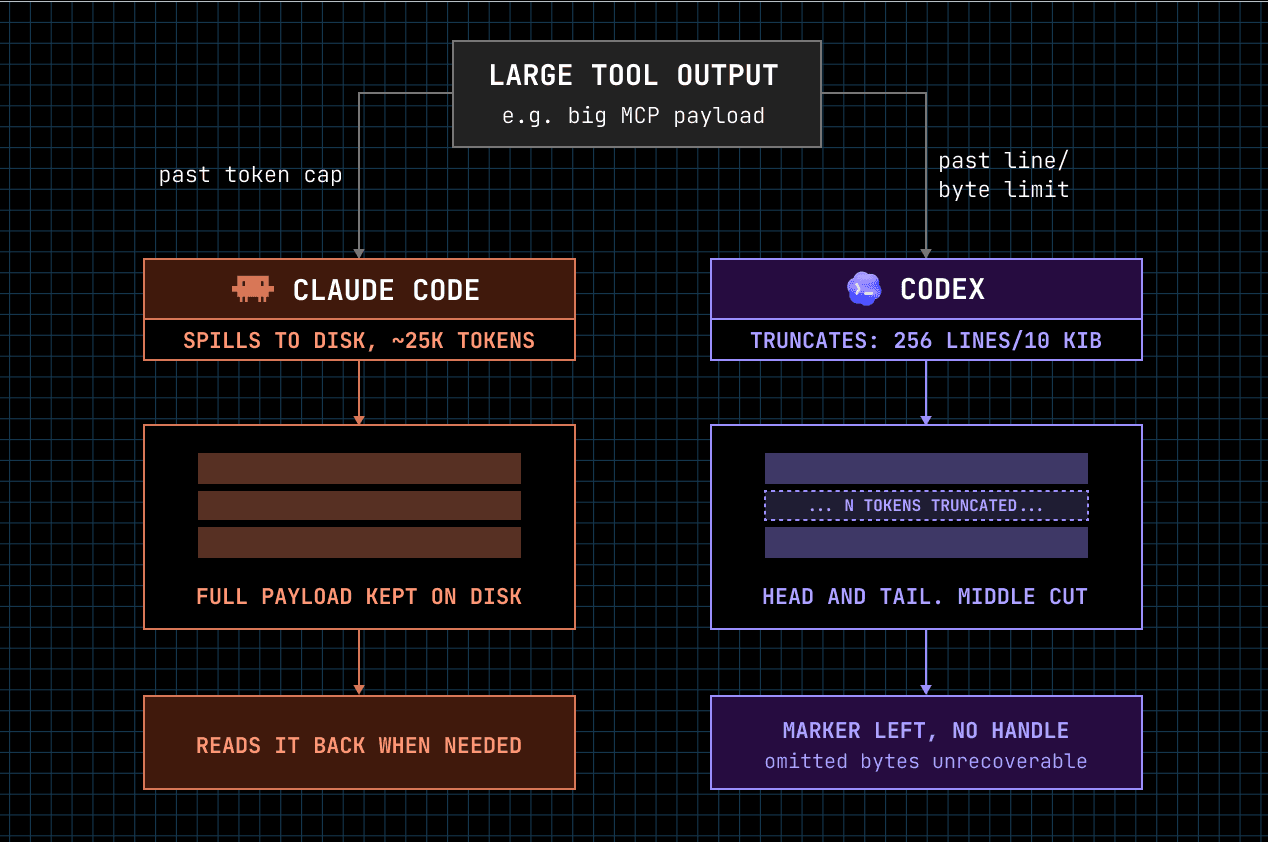
Large tool output | Saves big outputs to a file instead of cutting them short (25K tokens, up to 500K chars) past a certain point | Head/tail truncated, middle completely dropped |
Context between turns | Reloads CLAUDE.md after compaction | Sends only what changed |
Sandbox | Permission-gated & OS-level | Permission-gated & OS-level |
I notice a difference between the two models the most when an MCP tool returns a huge response. Codex truncates the middle and I lose what was in there; Claude keeps the whole response and pulls from it. But the moment that sold me on Claude's context handling was a compaction.
Real-life example: I had a 26-hour session in a macOS app with two floating panels buried inside a larger build.
Early on, Opus hit a known macOS bug: borderless panels do not accept keystrokes unless you override a specific property. It fixed the first panel correctly with a custom subclass, but missed the same fix on the second.
By then, the session was around 570K tokens. I ran /compact, compressed it to about 10K, and went to bed.
Eight hours later, I came back, tried typing into the second panel, and nothing happened. I sent: “wtf have you built?”
Five seconds later, without re-reading either file, Opus explained the exact issue: the panel was borderless and non-activating, the property defaulted to false, and the flag it had set depended on overriding it, “which I never did.”
That phrase is the whole point.
It was a counterfactual about its own work from a day earlier, across an overnight gap and a 57-to-1 context compression. It did not rederive the bug from scratch. It remembered having solved the same issue on the first panel but missed it on the second.
Ninety seconds later, the fix-it that shipped was essentially the same subclass as 24 hours earlier, renamed for the new panel.
That is the difference. The engineering memory survived compression.
Codex does not hold that for me. The middle disappears, and the architectural memory goes with it.
Winner: Claude Code
Claude handles context, large outputs, and long-session memory better. Codex has the nicer sandbox, but for the long, tool-heavy sessions I actually build in, Claude wins.
2 . Models: Opus 4.8 vs GPT 5.5 High
I started this on Opus 4.7 and GPT-5.5. Then Anthropic shipped Opus 4.8 on May 28, mid-testing, so a chunk of what follows is 4.8 impressions layered on months with 4.7.
On paper, Opus 4.8 is the better model. It just took the top of the aggregate intelligence index, and it wins the benchmark that maps to real work:
We have done a comparison of Opus 4.8 and GPT 5.5 that you’d absolutely love.
Benchmark | Opus 4.8 | GPT-5.5 |
|---|---|---|
SWE-bench Pro (multi-file, real repos) | 69.2% | 58.6% |
SWE-bench Verified | 88.6% | 87.6% |
Terminal-Bench 2.1 (CLI-heavy) | 74.6% | 78.2% |
Aggregate intelligence index | 56 | 55 |
So Claude leads the real-repo benchmark, and Codex keeps the terminal one, which, on paper, points at Claude, but the benchmarks and my lived experience pull in opposite directions here.
In my tests, Opus 4.8 turned out to be the better model. It has better tool-calling ability, and it sticks to instructions better than GPT. However, it uses up usage way too fast.
If you're using APIs, it will drain your credit card before you even realise.
GPT 5.5, on the other hand, is just the better bang-for-the-buck model. You get a simillar model at much lesser cost. It also excels in terminal coding.
On controls, both let you dial reasoning effort. Codex runs low, medium, high, xhigh; Claude Code runs low, medium, high, xhigh, max. Medium does most of what I need on Codex, and I keep Claude on high. Claude's fast mode, I rarely feel; mostly, it just burns through my plan more quickly.
Winner: Codex
Opus 4.8 is the better model, but GPT 5.5 is more cost-efficient. So, you'll be less likely to hit the Codex limit for the same tasks as opposed to using Opus 4.8 in Claude Code.
3 . Feature comparison: Claude Code vs Codex
I went looking for the stuff people actually use day-to-day, not the launch-tweet features.
The two daily sets line up almost one-to-one:
Claude Code | Codex | |
|---|---|---|
Project rules file | CLAUDE.md, read at the top of every session | AGENTS.md, with layered overrides (global, repo-root, per-dir) |
Slash commands | Merged into skills, a /command and a skill are the same thing | Steer the live session: /model, /plan, /compact |
In-loop code review | via subagent | /review, read-only reviewer that drops findings as their own turn |
Conditional context | Skills load only when a task matches | Skills + /goal to hold an objective across the session |
Context isolation | Subagents in their own window, Explore agent for codebase Q&A | Profiles for model/sandbox/approval bundles per project |
Determinism | Hooks: secret scan before writes, Prettier on save, type check after edits | Approval/sandbox model, read-only up to workspace-write |
Delegation | Agent View, claude --bg, Claude Code in Slack | codex cloud / codex cloud exec, the slickest of the bunch |
Most people who say Claude ignores instructions just have a thin CLAUDE.md. And this is moving pretty quickly. The Slack handoff is already mid-transition, and I'm genuinely excited to see where Claude Code takes the Slack integration from here.
The lesser-known stuff worth stealing
On Codex:
Best-of-N runs. Add --attempts (1–4) to the codex cloud exec, and it generates more than one solution to the same task. Great for a gnarly bug, let it take three swings and pick the best.
@codex in a PR comment to delegate a change to a cloud task, like
@codex add this to AGENTS.md.Browser self-review. Codex spins up its own browser, looks at what it built, iterates, and attaches a screenshot to the PR. Closest I've seen an agent get to how a human checks its own frontend work.
On Claude Code:
/team-onboarding, which I'd never seen anyone use. It reads your CLAUDE.md, skills, subagents, hooks, and workflows and writes a ramp-up doc for new devs, built in with nothing to install.
Headless mode. Claude -p runs a single non-interactive turn off stdin/stdout, which is what wires Claude into GitHub Actions, scheduled jobs, and pre-commit hooks. Most people never flip that switch.
Winner: Codex. Both have a deep set, but Codex's edges are the ones I reach for. Cloud delegation lets me hand work off and keep moving, and /review is the cleanest in-loop code review either tool ships. The lesser-known stuff is ahead, too. Claude's extensibility runs deeper if you invest in it, but most days I don't build custom workflows, I delegate and review, and that's Codex's lane.
4 . Instruction following and skills
Both are ways to tell the agent how to behave: the always-on rules and the on-demand ones.
Which one actually listens?
The always-on instruction file is CLAUDE.md for Claude Code and AGENTS.md for Codex. Both are read cold at the start of a session because neither has persistent memory by default.
For most of the Opus 4.7 era, Codex was simply better at obedience. It would follow an instruction from pages ago and stay inside the boundaries you set. Claude Code was more volatile. It sometimes treated a question like a disagreement, then went off and edited code you never asked it to touch. There is a reason people append “THIS IS JUST A QUESTION, DO NOT EDIT CODE” to prompts just to make it sit still.
The worst version of this I hit was with OpenClaw, which breaks often enough that I keep Claude Code around just to patch it. One time, the config broke, so I pointed Claude Code at the file and asked it to repair it. It deleted the entire OpenClaw install, then apologised. I asked it to fix one file. It removed the whole thing.
With Opus 4.8, Claude stopped drifting as much over long sessions and could be corrected mid-session, not just at at the beginning. It also added mid-conversation system messages, which means you can inject updated instructions deep into a session without restating the entire project context.
The mechanics are different, too. Claude walks up the directory tree to find the parent context. Codex walks down from the repo root and concatenates instructions, so deeper files override shallower ones. In practice, Codex makes it easier to know which rule won.
Two things help either way. Write imperatives, not observations. “Never use inline mocks, use src/test/factories' works better than 'we generally avoid inline mocks.” And keep the file under roughly 200 lines. A bloated instruction file usually reduces adherence instead of improving it.
How do skills compare?
Skills are the conditional version of the same idea. SKILL.md files that stay dormant and load only when a task matches, so they override the model's generic defaults without sitting in context.
Skills are a shared standard, so a file you write runs in both tools. The differences are at the edges:
Claude Code | Codex | |
|---|---|---|
Discovery path | .claude/skills/ | .agents/skills/ |
Settings format | JSON | TOML |
Extensions | Context forking, shell preprocessing, tool gating | openai.yaml for UI metadata |
Cross-compat | Reads Codex skills fine | Ignores Claude-only fields safely |
Winner: Claude Code with Opus 4.8, on the whole.
Codex follows instructions a bit better over a long session, and if obedience were the only axis, I'd hand it this one. But skills are the bigger story for most people, and that's Claude's home turf.
Anthropic created the Agent Skills standard and released it openly, the same play they ran with MCP, and Codex adopted it rather than helped design it.
Codex reads the same files fine, but when you go shopping for a skill, you're shopping in a store Claude built. Add 4.8, closing most of the instruction-following gap, and Claude edges the combined section.
5 . Pricing & usage limits: Claude Code vs Codex
The tiers line up almost suspiciously well:
Plan | Anthropic | OpenAI |
|---|---|---|
Entry | Pro, $20 | Plus, $20 |
Mid | Max 5x, $100 | Pro 5x, $100 |
Top | Max 20x, $200 | Pro, $200 |
The sticker price barely matters. What you're buying is agent time per dollar, and that's where they split:
Entry ($20) | Mid ($100) | |
|---|---|---|
Claude | Pro, ~45 msgs / 5 hrs, caps hit fast | Max 5x, ~225 msgs / 5 hrs |
Codex | Plus, rarely makes you think about limits | Pro 5x, ~150–750 local msgs / 5 hrs |
The Codex number is a range because OpenAI now bills on token usage, not per message, so a heavy session burns it faster, and the lighter Codex-mini model gets several times the headroom. I'm using the full model's steady-state figure since that's the fair comparison to Opus.
At the $20 floor, where most people live, Plus rarely makes me think about limits. Claude Pro goes through usage fast, sometimes inside the first hour, and Opus drains the allocation 5 to 10x faster than Sonnet.
I'm not philosophical about this. I built a dashboard, a Tauri app that watches what I spend across Claude Code, Codex, OpenCode, and Gemini in real time, with a CSS variable literally named money-green. The tell from that dashboard: Codex has never set it off. Months of sessions and Codex CLI have never once shown up as a constraint I had to work around.
The Anthropic cost is something I built an instrument to track; the Codex cost I've never had to think about. At $100, both target the same all-day user, and the message counts still favour Codex.
Two things worth knowing either way: a stray ANTHROPIC_API_KEY In your shell, silently bills Claude Code at API rates while your subscription sits unused.
Winner: Codex
At $20, Plus gives far more room to experiment before hitting limits.
The models cost about the same at the API level, so this was never about token rates; it's about how each company packages daily use, and right now, Anthropic is fencing usage off while OpenAI keeps loosening it. Claude Max earns its price if you're a heavy Opus user living inside Claude Code, but in terms of raw value per dollar, Codex takes it.
6 . Ecosystem: Plugins, MCP, Skills
Both support Plugins, MCPs, and Skills, and the wiring is nearly symmetric. Claude Code registers the MCP servers in .mcp.json at the project root (or ~/.claude.json for user scope) via claude mcp add; Codex keeps them in [mcp_servers.<name>] tables in ~/.codex/config.toml .
Either way, you point to the same connectors with the same credentials, and both speak remote-streamable HTTP MCP, so a hosted endpoint like Composio drops into one exactly as it drops into the other.
Installing the same connector in each takes one command. Claude Code:
claude mcp add --scope user --transport http composio <https://connect.composio.dev/mcp>Run /mcp In a session to trigger the OAuth flow and confirm it's connected. Codex:
codex mcp add composio --url <https://connect.composio.dev/mcp>
codex mcp login composiologin opens the same OAuth flow. Same endpoint, same credentials, no API key written to either config.
Where they really diverge is MCP.
Claude Code treats tools like part of the working loop, not an afterthought. It runs /mcp, checks what is reachable, and reads the tool schemas before it starts building. That means it writes against the actual response shapes instead of guessing what an API might return.
The connector layer itself does not favour either agent. Skills and MCP are shared standards, and the connectors are agent-agnostic by design. The model and harness will keep changing. The useful part is what you wire into them.
That is where Composio fits. It gives agents real tools like GitHub, Slack, Gmail, Linear, and 1,000+ other integrations over MCP, with auth and token handling already managed. You point the agent at one server, and it can open pull requests, post to channels, file issues, or work across apps without you writing a wrapper for every API.
The agent is increasingly interchangeable. The leverage is in the tools you connect to it.
Winner: tie
This is the one section where I won't hand it to either. Both reach everywhere, both speak MCP, and the connector layer is deliberately shared. Claude Code treats tools more natively, which is a real edge, but it's small enough and environment-dependent enough that the ecosystem itself isn't a reason to pick one over the other; it's the part you don't have to choose on.
So which one
Codex, three sections to two. But the score undersells how close it is, and which sections went where matters more than the count.
Claude wins the stuff that pays off if you put in the work. The harness holds up when sessions get long and messy, and skills are its home turf since Anthropic made the standard everyone copied. Write a good CLAUDE.md, build out a skills folder, and you'll be rewarded.
Codex wins the stuff I deal with every day. It's steady, I come back to a repo after a few days, and it picks up where it left off, and Opus just doesn't do that for me, sharp one week and hardcoding values the next. The features I actually use are delegating something and reviewing it, and both are better on Codex. And I hit the wall way later on pricing, while Anthropic keeps tightening what you get.
Opus is the better model when it's having a good day. I just can't make it have a good day on demand, and that's a big problem.
Pick Claude Code if
You write your own skills and build custom workflows; the extensibility runs deeper and rewards the investment.
You live in long, tool-heavy sessions where context management and big tool outputs matter.
You're a heavy Opus user who lives inside Claude Code and never touches outside tooling; that's where Max earns its price.
You want the skills ecosystem, the anthropics/skills repo, the skill creator, and the marketplace, all anchored here.
You're starting projects from scratch, run it with
-dangerously-skip-permissions, and it's the fastest path from idea to running code.
Pick Codex if
You want it to behave the same this week as last week, without babysitting, steadiness over peak smarts.
Your daily loop is delegate-and-review, Codex Cloud and /review are the cleanest versions of both.
You're price-sensitive at the $20 floor. Plus gives far more headroom before the wall.
You come back to the repo after a few days and need the agent to pick up where it left off.
You mostly maintain and extend an existing codebase, which tracks correlated changes across the system without being told where to look.
So it splits by what kind of developer you are. I came into this expecting Claude to win. I've used it forever, and its reliability is what flipped me.
Keep both installed. This swings every release, and any one of these sections could flip with the next Opus or Codex update. But if someone made me uninstall one today, it's not Codex.