Introduction
I was trying to ship faster.
I had a codebase, a backlog of things to build, and not enough hours in the day. So I started running AI coding agents in parallel — give each one a task, let them write code, review the PRs, merge, repeat. I started with two or three. Then five. Then ten.
The agents were fast. The problem was me. I couldn't keep up with them. I was the one checking if CI passed, reading review comments, copy-pasting errors back. I'd gone from writing code to babysitting the things that write code. That doesn't scale.
So I wrote some bash scripts to automate the coordination — about 2,500 lines that managed tmux sessions, git worktrees, and tab switching. Each agent got its own isolated tmux session and worktree. The orchestrator could spawn them, peek at what they were doing, and let me jump between sessions. It worked, barely.
Then I pointed the agents at the bash scripts themselves. They rewrote it all in TypeScript — same Claude Code sessions, gradually migrated from the old setup to the new one. The new orchestrator auto-injects CI failures and review comments back into agent sessions. It's been improving itself since.
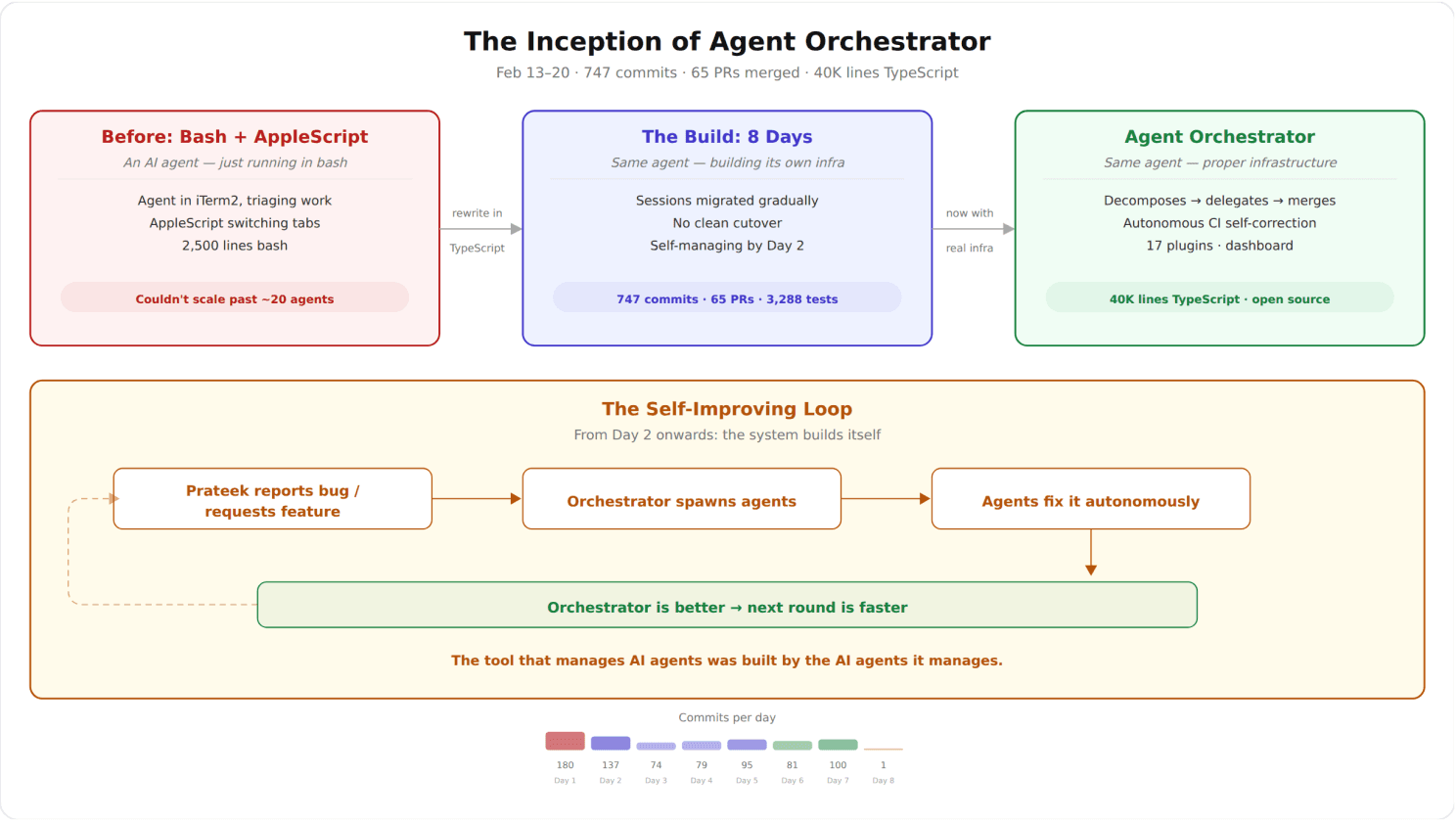
From bash scripts to self improving system
The result: 40,000 lines of TypeScript, 17 plugins, 3,288 tests — built in 8 days, mostly by the agents the system orchestrates. Every commit has a git trailer identifying which AI model wrote it. There's no ambiguity about what humans did vs what agents did.
Today we're open-sourcing it: Agent Orchestrator (github.com/ComposioHQ/agent-orchestrator).
The key thing to understand: the orchestrator itself is an AI agent. Not a dashboard. Not a cron job. Not a script that polls GitHub. It's an agent — it reads your codebase, understands your backlog, decides how to decompose a feature into parallelizable tasks, assigns each task to a coding agent, monitors their progress, reads their PRs, and makes decisions about what to do next. When CI fails, it injects the failure back into the agent session — the agent reads the logs and fixes it. When a review comment comes in, it routes it to the right agent session with context. No human plumbing.
That's what makes this different from every "run agents in parallel" setup. The thing managing the agents is itself intelligent.
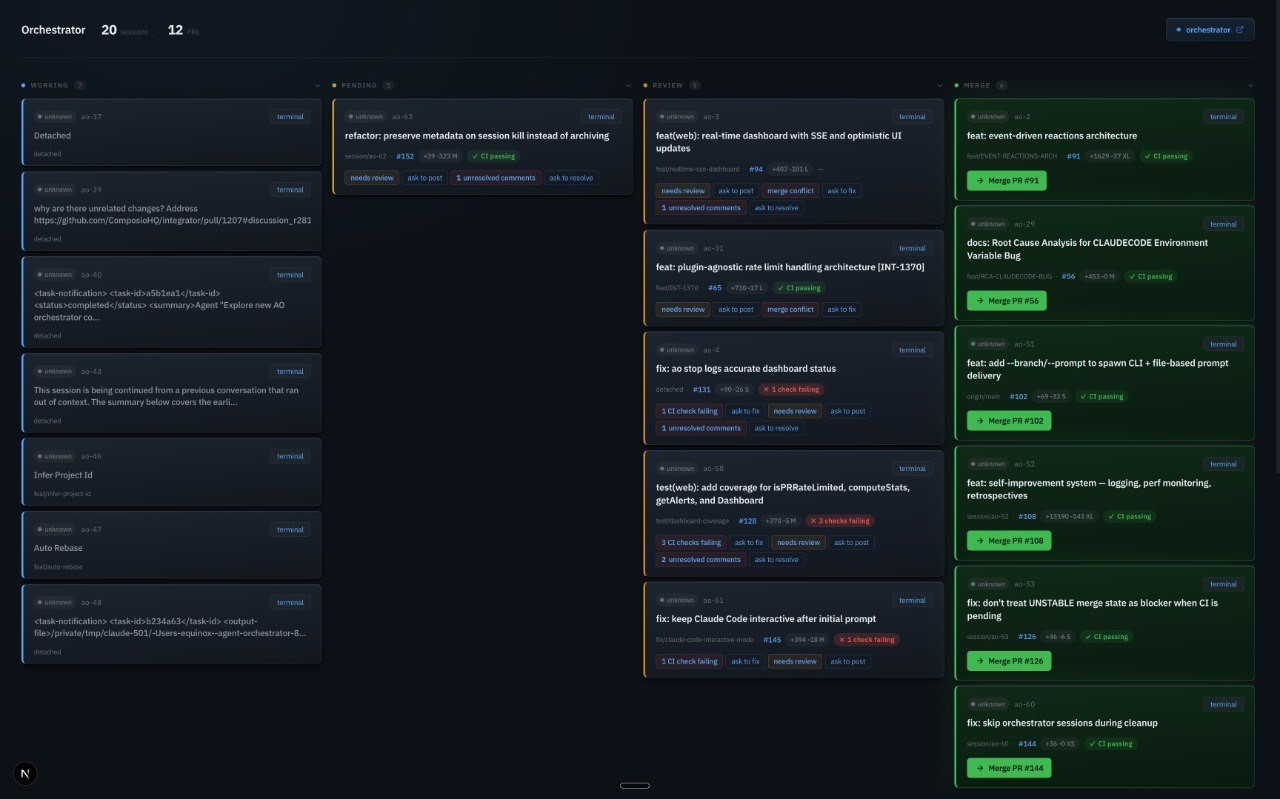
Agent orchestrator dashboard -- 35 sessions across Working, Pending, Review and Merge lanes
The real bottleneck in AI-assisted coding
Most people get the AI coding agent problem wrong. The agents can code. That's not the bottleneck. You are.
You spawn five tasks, go grab coffee, come back 20 minutes later and now you're just refreshing GitHub tabs — waiting for PRs, checking CI, reading review comments. Congratulations, you've automated engineering and replaced it with project management. Bad project management.
The orchestrator agent replaces you in that loop. Not with a script — with an actual AI agent that has context on every active session, every open PR, every CI run. It tracks everything, watches for failures, forwards review comments back to coding agents, and only pings you when something actually needs a human decision. Once that bottleneck — your attention — goes away, things start compounding fast.
You open the dashboard to see status. But the orchestrator agent is already working — it's looked at all your workstreams and it tells you: "This PR is blocking three other tasks, this CI failure is a flaky test, and this review comment is the one that actually matters." It's not showing you data. It's giving you decisions.
The numbers
TypeScript lines of code: ~40,000
Test cases (unit + integration): 3,288
Plugin packages: 17
PRs merged: 65 of 102 created
Commits (all branches): 747
PRs created by AI sessions: 86 (84%)
Peak concurrent agents: 30
AI co-authored commits: 100%

Build metrics at a glance
The timeline
People see "40K lines in 8 days" and assume I went into a cave. I have a day job. This was maybe ~3 days of actual focused work spread across 8 days, with agents filling the gaps.
Feb 13 (Fri): 157 branch commits → +30,070 lines → 1 PR merged
Feb 14 (Sat): 112 branch commits → +5,599 lines → 27 PRs merged
Feb 15 (Sun): 63 branch commits → +4,779 lines → 5 PRs merged
Feb 16 (Mon): 68 branch commits → +3,575 lines → 8 PRs merged
Feb 17 (Tue): 94 branch commits → +9,512 lines → 4 PRs merged
Feb 18 (Wed): 71 branch commits → +2,921 lines → 11 PRs merged
Feb 19 (Thu): 91 branch commits → +3,990 lines → 4 PRs merged
Feb 20 (Fri): 0 branch commits → 1 PR merged
Total: 656 branch commits → +76,454 lines → 65 PRs merged
The pattern was simple: set up sessions before bed, agents work overnight, review and merge in the morning before work, set up new sessions, repeat.
The standout day: Saturday Feb 14. 27 PRs merged in a single day. The entire platform shipped — core services, CLI, web dashboard, all 17 plugins, npm publishing. I was reviewing and merging PRs faster than I could read them, but every PR had passed CI and automated code review first.
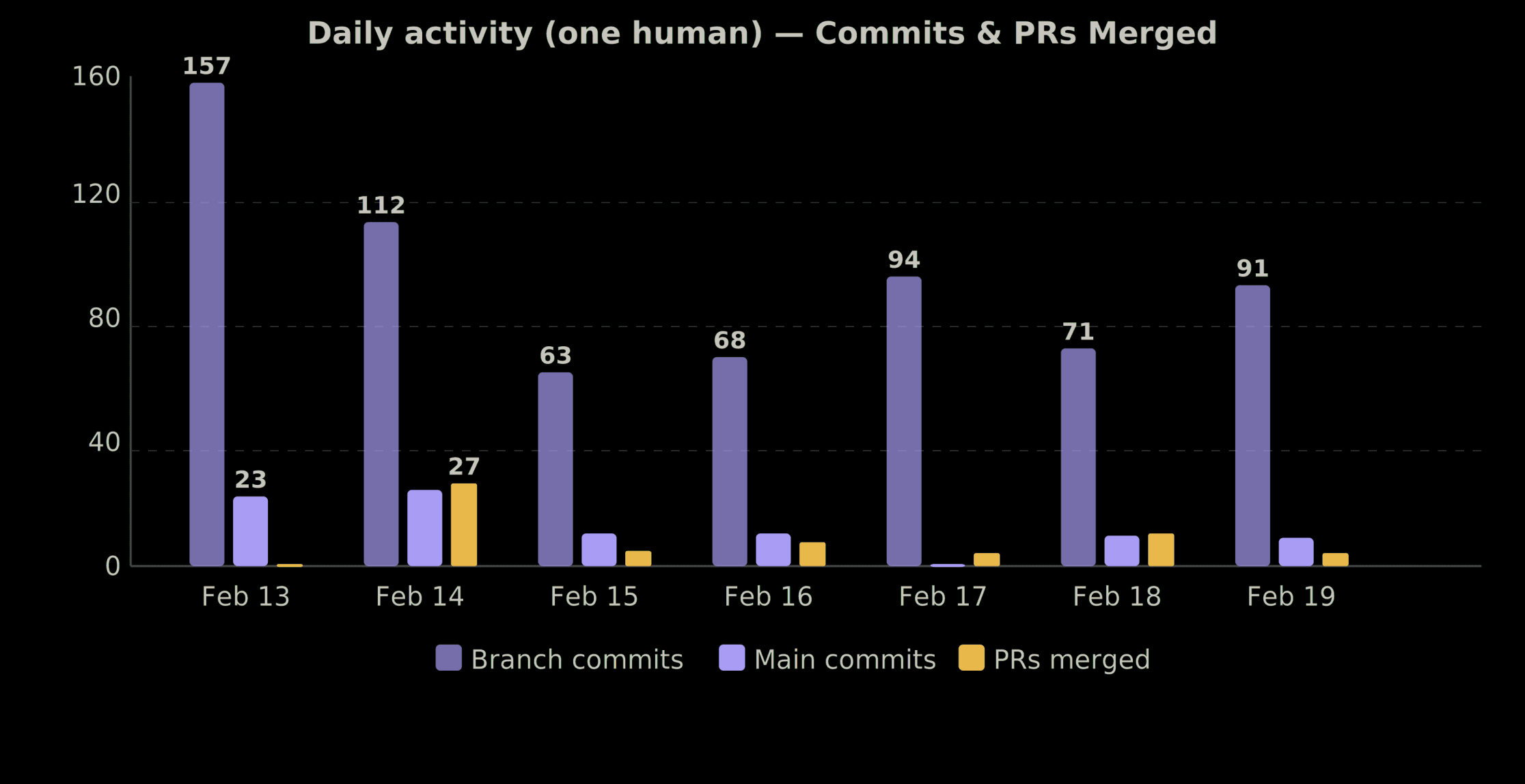
commits and PRs merged over 8 days
Which models did what
Every commit tracks the model via git trailers:
Claude Opus 4.6: 512 co-authored commits
Claude Sonnet 4.5: 373 co-authored commits
Claude Sonnet 4.6: 124 co-authored commits
Claude Opus 4.5: 4 co-authored commits
Total trailers: 1,013
Totals exceed 747 commits because some commits were written by one model and reviewed/fixed by another. Opus 4.6 handled the hard stuff — complex architecture, cross-package integrations. Sonnet handled volume — plugin implementations, tests, docs.
Fully autonomous code review
700 comments, 1% human
Agents don't just write code and throw it over the wall. There's a full automated review cycle:
Agent creates a PR and pushes code
Cursor Bugbot automatically reviews and posts inline comments
Agent reads comments, fixes the code, pushes again
Bugbot re-reviews
Cursor Bugbot (automated): 377 reviews, 700 inline comments (69%)
AI agents: 316 reviews, 303 inline comments (30%)
Humans: 13 reviews, 13 inline comments (1%)
700 automated code review comments. Bugbot caught real stuff — shell injection via exec(), path traversal, unclosed intervals, missing null checks. The agents fixed ~68% immediately, explained away ~7% as intentional, and deferred ~4% to future PRs.
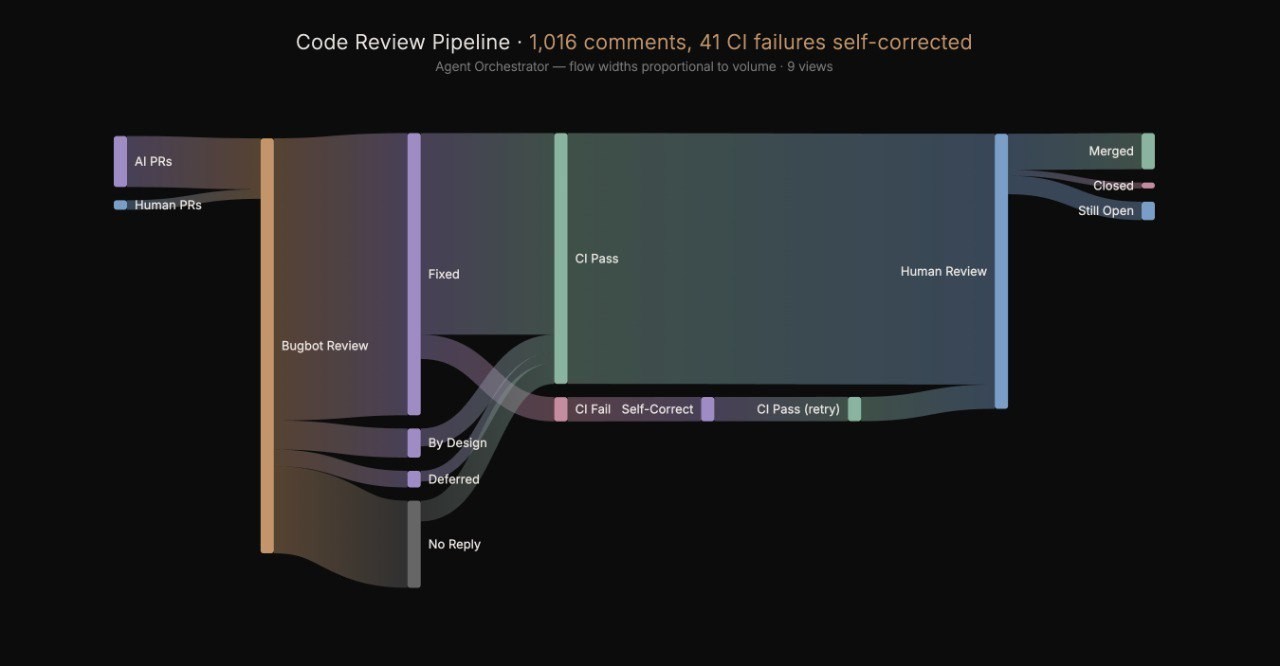
Code review pipelien-- from agent PR to ship
The ao-58 story
The most dramatic example: PR #125, a dashboard redesign. It went through 12 CI failure→fix cycles. Each time, the agent got the failure output, diagnosed the issue (type errors, lint failures, test regressions), and pushed a fix. No human touched it.
12 rounds. Zero human intervention. Shipped clean.
session/ao-58: 12 CI failures, 28 successes → Dashboard redesign
session/ao-52: 7 CI failures, 76 successes → Self-improvement system
feat/EVENT-REACTIONS-ARCH: 3 CI failures, 17 successes → Reactions architecture
fix/spawn-status-transition: 2 CI failures, 50 successes → Status transitions
All 41 CI failures across 9 branches were eventually self-corrected by agents. Overall CI success rate: 84.6%.

CI self-correction -- failures vs success per branch
Architecture
The orchestrator uses a plugin system with 8 swappable slots:
Runtime (tmux, process) → Where agents execute
Agent (claude-code, aider, codex, opencode) → Which AI coding agent
Workspace (worktree, clone) → How code is isolated
Tracker (github, linear) → Where issues come from
SCM (github) → PR creation and enrichment
Notifier (desktop, slack, composio, webhook) → How humans get notified
Terminal (iterm2, web) → How you observe agents
Lifecycle (core) → Reactions and status transitions
Session lifecycle:
Tracker pulls an issue (GitHub or Linear)
Workspace creates an isolated worktree or clone
Runtime starts a tmux session or process
Agent (Claude Code, Aider, etc.) works autonomously
Terminal lets you observe live via iTerm2 or web dashboard
SCM creates PRs and enriches them with context
Reactions auto re-spawn agents on CI failures or review comments
Notifier pings you only when human judgment is needed

Session lifecycle -- from issue to merged PR
Don't use tmux? Use the process runtime. Don't use GitHub? Use Linear. Don't use Claude Code? Plug in Aider or Codex. Swap any piece.
Self-healing CI
Agents that fix their own failures
The most useful feature. Automated responses to GitHub events:
When CI fails, the orchestrator injects the failure into the agent's session. The agent reads the logs and fixes it. When a reviewer requests changes, the orchestrator routes the comments to the agent with context. When a PR is approved, you get a notification. No human plumbing.
This is how those 41 CI failures got self-corrected — the reactions system just forwarded failures back to agents automatically.
The inception
AI agents building their own orchestrator
I had 30 concurrent agents working on Agent Orchestrator. They were building the TypeScript replacement while I was using the bash-script version to manage them. The thing being built was the thing managing its own construction.
What I actually did:
Architecture decisions (plugin slots, config schema, session lifecycle)
Spawning sessions and assigning issues
Reviewing PRs (mostly architecture, not line-by-line)
Resolving cross-agent conflicts (two agents editing the same file)
Judgment calls (reject this approach, try that one)
What agents did:
All implementation (40K lines of TypeScript)
All tests (3,288 test cases)
All PR creation (86 of 102 PRs)
All review comment fixes
All CI failure resolution
I never committed directly to a feature branch. Every line of code went through a PR.
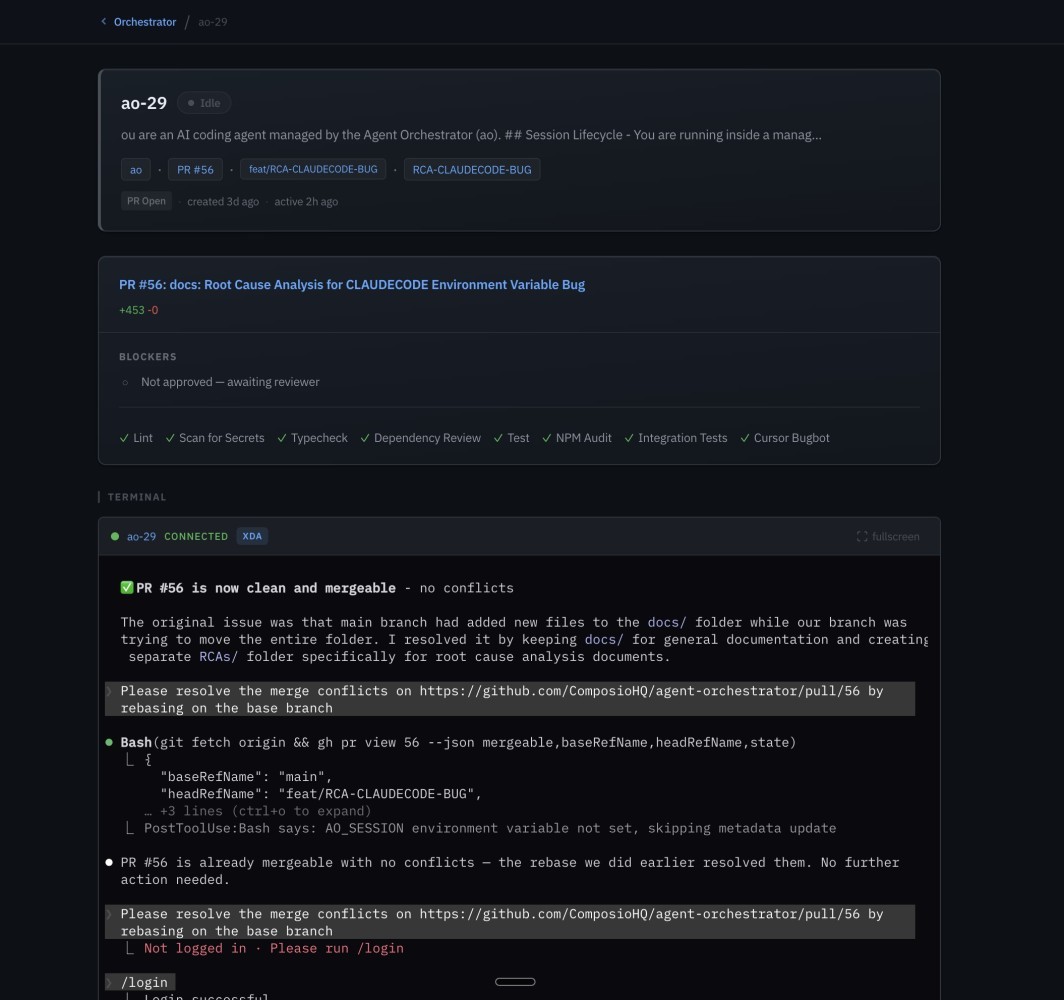
Session detail -- PR status, CI checks, and live terminal showing an agent resolving merge conflicts
Activity detection
One of the trickier problems: figuring out what an agent is actually doing without asking it.
Claude Code writes structured JSONL event files during every session. Instead of relying on agents to self-report (they lie, or at least get confused), the orchestrator reads these files directly:
Is the agent actively generating tokens?
Is it waiting for tool execution?
Is it idle?
Has it finished?
Web dashboard
Next.js 15, Server-Sent Events for real-time updates. No polling.
Attention zones — sessions grouped by what needs your attention (failing CI, awaiting review, running fine)
Live terminal — xterm.js in the browser, showing the agent's actual terminal output in real time
Session detail — current file being edited, recent commits, PR status, CI status
Config discovery — automatically finds your ao.config.yaml and shows available sessions
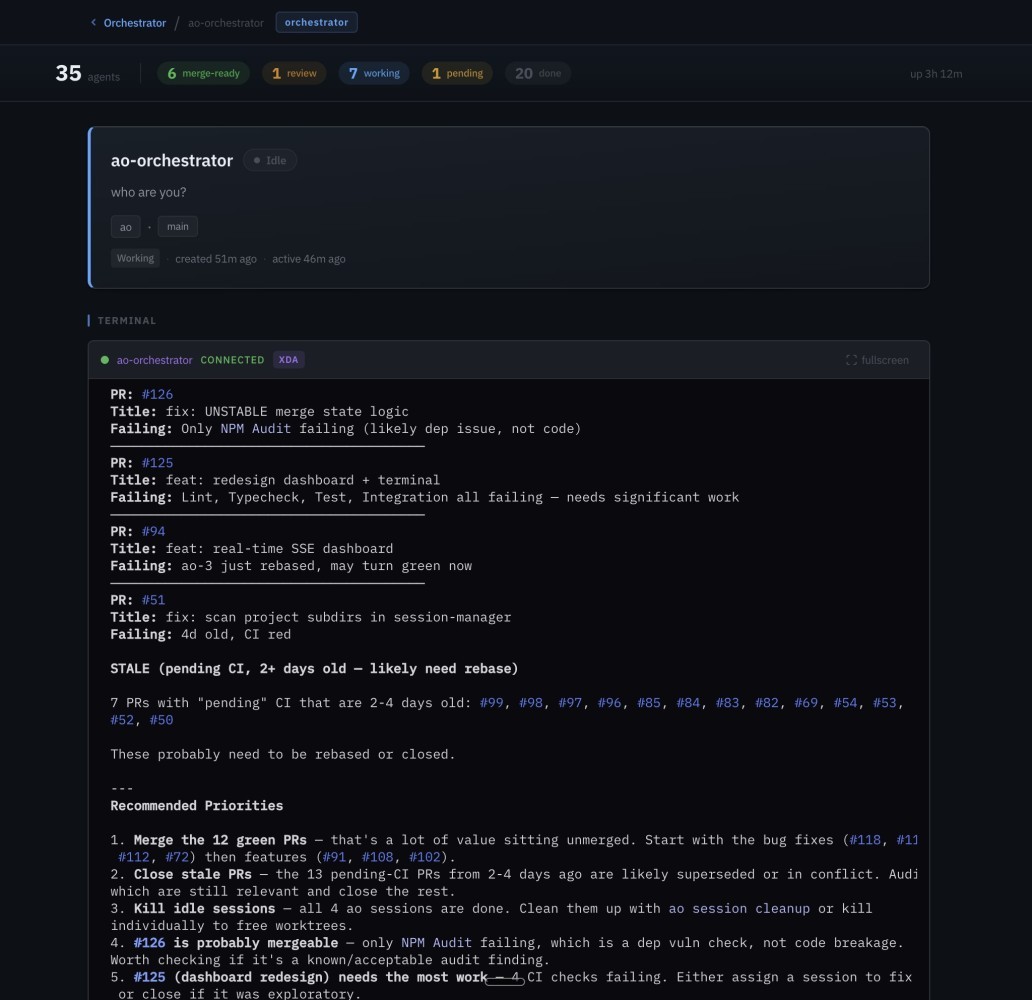
Orchestrator agent page -- live terminal view
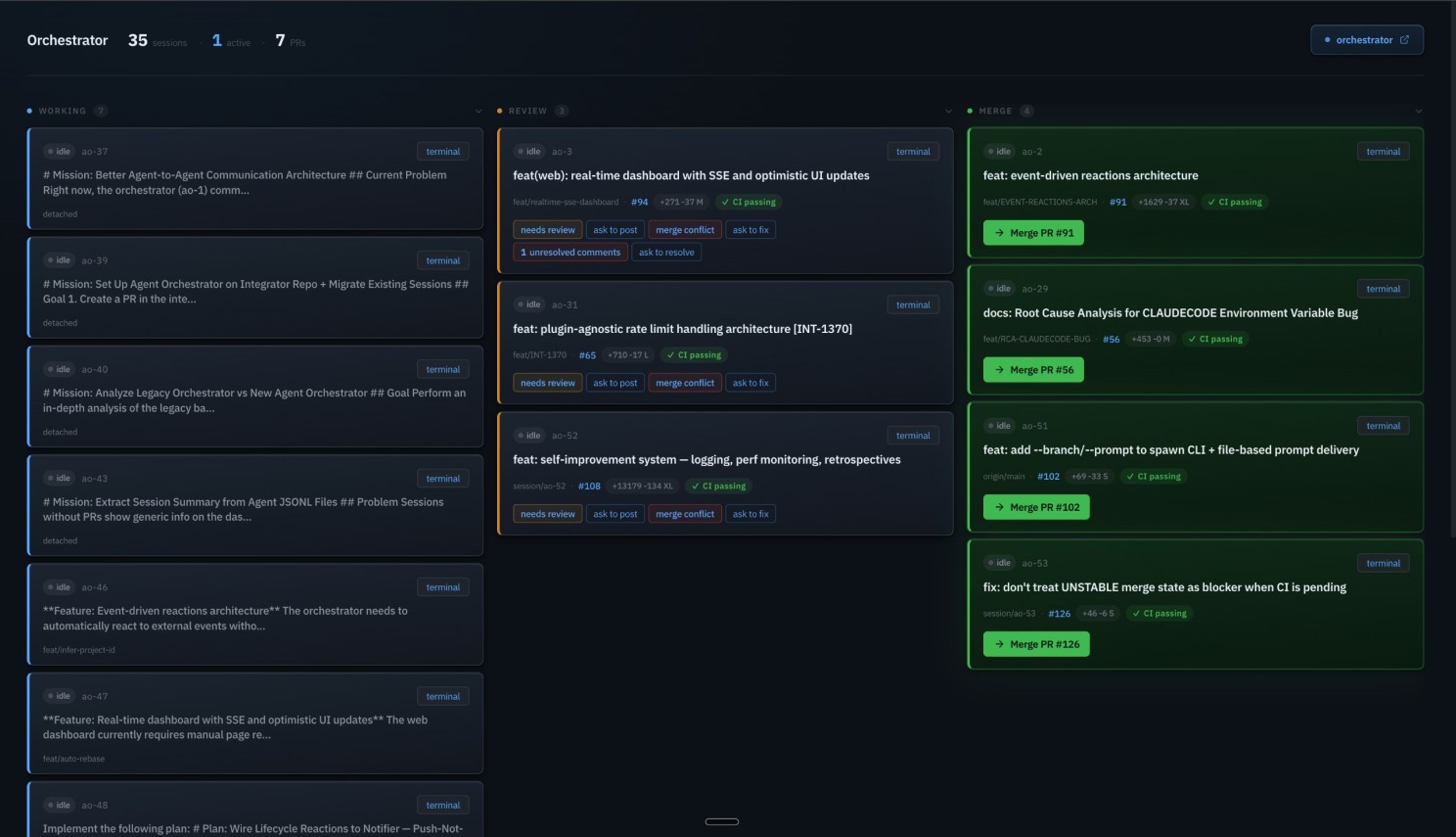
Kanban view of all agent sessions
The self-improving AI loop
Every agent session generates signal. Which prompts led to clean PRs? Which ones spiraled into 12 CI failure cycles? Which patterns caused merge conflicts?
Most agent setups throw this signal away. Session finishes, you move on, next session starts from zero.
Agent Orchestrator has a self-improvement system (ao-52 — itself built by an agent) that logs performance, tracks session outcomes, and runs retrospectives. It learns which tasks succeed on the first try and which need tighter guardrails.
Agents build features → orchestrator observes what worked → adjusts how it manages future sessions → agents build better features. The loop compounds.
And since the agents built the orchestrator, and the orchestrator makes the agents more effective, and those agents keep improving the orchestrator — it's recursive. The tool is improving itself through the agents it manages.
I think this is why orchestration matters more than any individual agent improvement. The ceiling isn't "how good is Claude Code at TypeScript." It's "how good can a system get at deploying, observing, and improving dozens of agents working in parallel." That ceiling is much higher. And it rises every time the loop runs.
What's next
towards fully autonomous software engineering
Talk to your agents from anywhere. Right now you need to be at your desk. You should be able to message the orchestrator from Telegram or Slack — check status, approve a merge, redirect an agent — while you're on a walk.
Tighter mid-session feedback. Agents drift. They start solving the wrong problem, over-engineer a simple fix, go down rabbit holes. The orchestrator needs to check agent work against the original intent and inject course corrections before they've burned 20 minutes going the wrong direction.
Automatic escalation. Agent can't solve something? Escalate to orchestrator. Orchestrator needs judgment? Escalate to you. You only see things that genuinely need a human decision. Everything else resolves itself.
Beyond that: a reconciler for automatic conflict resolution between parallel agents, auto-rebase for long-running branches, Docker/K8s runtimes for cloud deployments, and a plugin marketplace for community contributions.
Try it
Start the orchestrator, open the dashboard, and talk to it. Tell it what to build. It handles the rest — spawning agents, creating PRs, watching CI, forwarding review comments. You just make decisions.
We're looking for contributors: new plugins (agent runtimes, trackers, notifiers), Docker/K8s runtime, a reconciler for automatic conflict detection, and better escalation rules.
Full metrics report: github.com/ComposioHQ/agent-orchestrator/releases/tag/metrics-v1
Interactive visualizations: pkarnal.com/ao-labs/

Code review breakdown -- automated vs human