Improving GPT 4 Function Calling Accuracy
Join our Discord Community and check out what we’re building!
We just published Part 2 of the blog comparing gpt-4-turbo vs opus vs haiku vs sonnet .
TL;DR: Show me the results
Introduction to GPT Function Calling
Large language models have recently been given the ability to perform function calling. Given the details(function-schema) of a number of functions, the LLM will be able to select and run the function with appropriate chat GPT4 parameters, if the prompt demands for it. OpenAI’s GPT-4 is one of the best function-calling LLMs available for use. In addition to the GPT4 function calling, there are also open-source function calling LLMs like OpenGorilla, Functionary, NexusRaven and FireFunction that we will try and compare performance with. Example Function Calling Code can be found at OpenAI function calling documentation.
Integration-Focused Agentic Function Calling GPT
We are transitioning towards Agentic applications for more effective use of LLMs in our daily workflow. In this setup, each AI agent is designated a specific role, equipped with distinct functionalities, often collaborating with other agents to perform complex tasks.
To enhance user experience and streamline workflows, these agents must interact with the tools used by users and automate some functionalities. Currently, AI development allows agents to interact with various software tools to a certain extent through proper integration using software APIs or SDKs. While we can integrate these points into AI agents and hope for flawless operation, the question arises:
Are the common design of API endpoints optimized for Agentic Process Automation (APA)? Maybe we can redesign APIs to improve the GPT4 function calling?
Selecting Endpoints using GPT 4 Function Call
We referenced the docs of ClickUp (Popular Task management App) and curated a selection of endpoints using gpt4 function calling. The decision was made due to the impracticality of expecting the LLM to choose from hundreds of endpoints, considering the limitation of context length.
get_spaces(team_id:string, archived:boolean)
create_space(team_id:string, name:string, multiple_assignees:boolean, features:(due_dates:(enabled:boolean, start_date:boolean, remap_due_dates:boolean, remap_closed_due_date:boolean), time_tracking:(enabled:boolean)))
get_space(space_id:string)
update_space(space_id:string, name:string, color:string, private:boolean, admin_can_manage:boolean, multiple_assignees:boolean, features:(due_dates:(enabled:boolean, start_date:boolean, remap_due_dates:boolean, remap_closed_due_date:boolean), time_tracking:(enabled:boolean)))
delete_space(space_id:string)
get_space_tags(space_id:string)
create_space_tag(space_id:string, tag:(name:string, tag_fg:string, tag_bg:string))
delete_space_tag(space_id:string, tag_name:string, tag:(name:string, tag_fg:string, tag_bg:string))We converted them to the corresponding OpenAI function calling schema, which is available here. These were specifically selected as they combine endpoints with both flattened and nested parameters.
Creating Benchmark Dataset
To evaluate our approaches effectively, we require a benchmark dataset that is small and focuses specifically on the software-integration aspect of function-calling Language Models (LLMs).
Despite reviewing various existing function calling datasets, none were found to be ideal for this study.
Consequently, we developed our own dataset called the ClickUp-Space dataset, which replicates real-world scenarios to some extent in gpt-4 function calling.
The prompts require one of eight selected functions to solve, ranging from simple to complex. Our evaluation will be based on how accurately the gpt functions are called with the correct parameters. We also prepared code for assessing performance.
Next, we developed a problem set consisting of 50 pairs of prompts along with their respective function calling solutions.
[
{
"prompt": "As the new fiscal year begins, the management team at a marketing agency decides it's time to archive older projects to make way for new initiatives. They remember that one of their teams is called \"Innovative Solutions\" and operates under the team ID \"team123\". They want to check which spaces under this team are still active before deciding which ones to archive.",
"solution": "get_spaces(team_id=\"team123\", archived=False)"
},
{
"prompt": "Ella, the project coordinator, is setting up a new project space in ClickUp for the \"Creative Minds\" team with team ID \"cm789\". This space, named \"Innovative Campaigns 2023\", should allow multiple assignees for tasks, but keep due dates and time tracking disabled, as the initial planning phase doesn't require strict deadlines or time monitoring.",
"solution": "create_space(team_id=\"cm789\", name=\"Innovative Campaigns 2023\", multiple_assignees=True, features=(due_dates=(enabled=False, start_date=False, remap_due_dates=False, remap_closed_due_date=False), time_tracking=(enabled=False)))"
},
...
]Measuring GPT-4 Function Calling Baseline Performance
Initially, we wanted to assess GPT-4’s function calling performance independently, without any system prompts.
fcalling_llm = lambda fprompt : client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{
"role": "system",
"content": """"""
},
{
"role": "user",
"content": prompt
},
],
temperature=0,
max_tokens=4096,
top_p=1,
tools=tools,
tool_choice="auto"
)
response = fcalling_llm(bench_data[1]["prompt"])We set the temperature to 0 to make the results more predictable. The experiment was repeated three times, resulting in an average accuracy of 30%, which is below the target.
Benchmark without System Prompt – [Code Here]

Flattening the gpt Parameters
Some functions require output parameters in a nested structure. An example below-
{
"name": "create_space",
"description": "Add a new Space to a Workspace.",
"parameters": {
"type": "object",
"properties": {
"team_id": {
"type": "string",
"description": "The ID of the team"
},
"name": {
"type": "string",
"description": "The name of the new space"
},
"multiple_assignees": {
"type": "boolean",
"description": "Enable or disable multiple assignees for tasks within the space"
},
"features": {
"type": "object",
"description": "Enabled features within the space",
"properties": {
"due_dates": {
"type": "object",
"description": "Due dates feature settings",
"properties": {
"enabled": { "type": "boolean" },
"start_date": { "type": "boolean" },
"remap_due_dates": { "type": "boolean" },
"remap_closed_due_date": { "type": "boolean" }
}
},
"time_tracking": {
"type": "object",
"description": "Time tracking feature settings",
"properties": {
"enabled": { "type": "boolean" }
}
}
}
}
},
"required": ["team_id", "name", "multiple_assignees", "features"]
}
}Based on our experience with LLMs, we believe that while the model (GPT-4) has been optimised for structured output, a complex output structure may actually reduce performance and gpt function calling accuracy of the LLM output.
Therefore, we programmatically flatten the parameters.
Above function flattened will look as follows:
{
"description": "Add a new Space to a Workspace.",
"name": "create_space",
"parameters": {
"properties": {
"features__due_dates__enabled": {
"description": "enabled__Due dates feature settings__Enabled features within the space__",
"type": "boolean"
},
"features__due_dates__remap_closed_due_date": {
"description": "remap_closed_due_date__Due dates feature settings__Enabled features within the space__",
"type": "boolean"
},
"features__due_dates__remap_due_dates": {
"description": "remap_due_dates__Due dates feature settings__Enabled features within the space__",
"type": "boolean"
},
"features__due_dates__start_date": {
"description": "start_date__Due dates feature settings__Enabled features within the space__",
"type": "boolean"
},
"features__time_tracking__enabled": {
"description": "enabled__Time tracking feature settings__Enabled features within the space__",
"type": "boolean"
},
"multiple_assignees": {
"description": "Enable or disable multiple assignees for tasks within the space__",
"type": "boolean"
},
"name": {
"description": "The name of the new space__",
"type": "string"
},
"team_id": {
"description": "The ID of the team__",
"type": "string"
}
},
"required": [
"team_id",
"name",
"multiple_assignees",
"features__due_dates__enabled",
"features__due_dates__start_date",
"features__due_dates__remap_due_dates",
"features__due_dates__remap_closed_due_date",
"features__time_tracking__enabled"
],
"type": "object"
}
}We attached the parameter name to its parent parameters (ex:features__due_dates__enabled ) by __ , and joined the parameter descriptions to its predecessor ( Ex:enabled__due_dates feature settings__enabled features within the space__ ).
Benchmark after Flattening Schema [Code Here]

Adding System Prompt with GPT4 Functional Calling Accuracy
We didn’t have a system prompt before, so the LLM wasn’t instructed on its role or interacting with ClickUp APIs.
Let’s add a simple system prompt now.
| System
from openai import OpenAI
client = OpenAI()
fcalling_llm = lambda fprompt : client.chat.completions.create(
model="gpt-4-turbo-preview",
messages=[
{
"role": "system",
"content": """
You are an agent who is responsible for managing various employee management platform,
one of which is ClickUp.
When you are presented with a technical situation, that a person of a team is facing,
you must give the soulution utilizing your functionalities.
"""
},
{
"role": "user",
"content": fprompt
},
],
temperature=0,
max_tokens=4096,
top_p=1,
tools=tools,
tool_choice="auto"
)
response = fcalling_llm(bench_data[1]["prompt"])Benchmark with System Prompt – [Code Here]

GPT 4 function calling accuracy by Improving System Prompt
Now that we’ve observed an improvement in performance by adding a system prompt, we will enhance its detail to assess if the performance increase is sustained.
You are an agent who is responsible for managing various employee management platform,
one of which is ClickUp.
You are given a number of tools as functions, you must use one of those tools and fillup
all the parameters of those tools ,whose answers you will get from the given situation.
When you are presented with a technical situation, that a person of a team is facing,
you must give the soulution utilizing your functionalities.
First analyze the given situation to fully anderstand what is the intention of the user,
what they need and exactly which tool will fill up that necessity.
Then look into the parameters and extract all the relevant informations to fillup the
parameter with right values.Benchmark after Flattened Schema + Improved System Prompt

Seems to work great! [Code Here]
Adding Schema Summary in Schema Prompt
Let’s enhance the system prompts further by focusing on the functions and their purpose, building upon the clear instructions provided for the LLM’s role.
Here is a concise summary of the system functions which we add to prompt.
get_spaces - View the Spaces available in a Workspace.
create_space - Add a new Space to a Workspace.
get_space - View the details of a specific Space in a Workspace.
update_space - Rename, set the Space color, and enable ClickApps for a Space.
delete_space - Delete a Space from your Workspace.
get_space_tags - View the task Tags available in a Space.
create_space_tag - Add a new task Tag to a Space.
delete_space_tag - Delete a task Tag from a Space.Benchmark after Flattened Schema + Improved System Prompt containing Schema Summary. [Code Here]

Optimising Function Names
Now, let’s improve the schemas starting with more descriptive function names.
schema_func_name_dict = {
"get_spaces": "get_all_clickup_spaces_available",
"create_space": "create_a_new_clickup_space",
"get_space": "get_a_specific_clickup_space_details",
"update_space": "modify_an_existing_clickup_space",
"delete_space": "delete_an_existing_clickup_space",
"get_space_tags": "get_all_tags_of_a_clickup_space",
"create_space_tag": "assign_a_tag_to_a_clickup_space",
"delete_space_tag": "remove_a_tag_from_a_clickup_space",
}optimized_schema = []
for sc in flattened_schema:
temp_dict = sc.copy()
temp_dict["name"] = schema_func_name_dict[temp_dict["name"]]
optimized_schema.append(temp_dict)Benchmark after Flattened Schema + Improved System Prompt containing Schema Summary + Function Names Optimised [Code Here]

Optimising Function Description
Here, we focus on the function descriptions and make those more clear and focused.
schema_func_decription_dict = {
"get_spaces": "Retrives information of all the spaces available in user's Clickup Workspace.",
"create_space": "Creates a new ClickUp space",
"get_space": "Retrives information of a specific Clickup space",
"update_space": "Modifies name, settings the Space color, and assignee management Space.",
"delete_space": "Delete an existing space from user's ClickUp Workspace",
"get_space_tags": "Retrives all the Tags assigned on all the tasks in a Space.",
"create_space_tag": "Assigns a customized Tag in a ClickUp Space.",
"delete_space_tag": "Deletes a specific tag previously assigned in a space.",
}And change schema with:
optimized_schema = []
for sc in flattened_schema:
temp_dict = sc.copy()
temp_dict["description"] = schema_func_decription_dict[temp_dict["name"]]
optimized_schema.append(temp_dict)Benchmark after Flattened Schema + Improved System Prompt containing Schema Summary + Function Names Optimised + Function Descriptions Optimised [Code Here]

Optimising gpt Function Parameter Descriptions
Earlier, we flattened the schema by stacking nested parameters’ descriptions with their parents’ descriptions until they were in a flattened state.
Let’s now replace them with:
schema_func_params_dict = {
'create_space': {
'features__due_dates__enabled': 'If due date feature is enabled within the space. Default: True',
'features__due_dates__remap_closed_due_date': 'If remapping closed date feature in due dates is available within the space. Default: False',
'features__due_dates__remap_due_dates': 'If remapping due date feature in due dates is available within the space. Default: False',
'features__due_dates__start_date': 'If start date feature in due dates is available within the space. Default: False',
'features__time_tracking__enabled': 'If time tracking feature is available within the space. Default: True',
'multiple_assignees': 'Enable or disable multiple assignees for tasks within the space. Default: True',
'name': 'The name of the new space to create',
'team_id': 'The ID of the team'
},
'create_space_tag': {
'space_id': 'The ID of the space',
'tag__name': 'The name of the tag to assign',
'tag__tag_bg': 'The background color of the tag to assign',
'tag__tag_fg': 'The foreground(text) color of the tag to assign'
},
'delete_space': {
'space_id': 'The ID of the space to delete'
},
'delete_space_tag': {
'space_id': 'The ID of the space',
'tag__name': 'The name of the tag to delete',
'tag__tag_bg': 'The background color of the tag to delete',
'tag__tag_fg': 'The foreground color of the tag to delete',
'tag_name': 'The name of the tag to delete'
},
'get_space': {
'space_id': 'The ID of the space to retrieve details'
},
'get_space_tags': {
'space_id': 'The ID of the space to retrieve all the tags from'
},
'get_spaces': {
'archived': 'A flag to decide whether to include archived spaces or not. Default: True',
'team_id': 'The ID of the team'
},
'update_space': {
'admin_can_manage': 'A flag to determine if the administrator can manage the space or not. Default: True',
'color': 'The color used for the space',
'features__due_dates__enabled': 'If due date feature is enabled within the space. Default: True',
'features__due_dates__remap_closed_due_date': 'If remapping closed date feature in due dates is available within the space. Default: False',
'features__due_dates__remap_due_dates': 'If remapping due date feature in due dates is available within the space. Default: False',
'features__due_dates__start_date': 'If start date feature in due dates is available within the space. Default: False',
'features__time_tracking__enabled': 'If time tracking feature is available within the space. Default: True',
'multiple_assignees': 'Enable or disable multiple assignees for tasks within the space. Default: True',
'name': 'The new name of the space',
'private': 'A flag to determine if the space is private or not. Default: False',
'space_id': 'The ID of the space'
}
}And modifying the previous schema:
optimized_schema = []
for sc in flattened_schema:
temp_dict = sc.copy()
temp_dict["description"] = schema_func_decription_dict[temp_dict["name"]]
for func_param_name, func_param_description in schema_func_params_dict[temp_dict["name"]].items():
sc["parameters"]["properties"][func_param_name]["description"] = func_param_description
optimized_schema.append(temp_dict)Benchmark after Flattened Schema + Improved System Prompt containing Schema Summary + (Function Names + Function Descriptions + Parameter Descriptions) Optimised [Code Here]

Wow! For all runs we got score equal to or over 75%.Adding Examples of GPT Function Calls
LLMs perform better when response examples are provided. Let’s aim to give examples and analyse the outcomes.
To start, we can provide examples of each function call along with the corresponding function description in the schema to illustrate this concept.
schema_func_decription_dict = {
"get_spaces": """\
Retrives information of all the spaces available in user's Clickup Workspace. Example Call:
```python
get_spaces({'team_id': 'a1b2c3d4', 'archived': False})
```
""",
"create_space": """\
Creates a new ClickUp space. Example Call:
```python
create_space ({
'team_id': 'abc123',
'name': 'NewWorkspace',
'multiple_assignees': True,
'features__due_dates__enabled': True,
'features__due_dates__start_date': False,
'features__due_dates__remap_due_dates': False,
'features__due_dates__remap_closed_due_date': False,
'features__time_tracking__enabled': True
})
```
""",
"get_space": """\
Retrives information of a specific Clickup space. Example Call:
```python
get_space({'space_id': 's12345'})
```
""",
"update_space": """\
Modifies name, settings the Space color, and assignee management Space. Example Call:
```python
update_space({
'space_id': 's12345',
'name': 'UpdatedWorkspace',
'color': '#f0f0f0',
'private': True,
'admin_can_manage': False,
'multiple_assignees': True,
'features__due_dates__enabled': True,
'features__due_dates__start_date': False,
'features__due_dates__remap_due_dates': False,
'features__due_dates__remap_closed_due_date': False,
'features__time_tracking__enabled': True
})
```
""",
"delete_space": """\
Delete an existing space from user's ClickUp Workspace. Example Call:
```python
delete_space({'space_id': 's12345'})
```
""",
"get_space_tags": """\
Retrives all the Tags assigned on all the tasks in a Space. Example Call:
```python
get_space_tags({'space_id': 's12345'})
```
""",
"create_space_tag": """\
Assigns a customized Tag in a ClickUp Space. Example Call:
```python
create_space_tag({
'space_id': 's12345',
'tag__name': 'Important',
'tag__tag_bg': '#ff0000',
'tag__tag_fg': '#ffffff'
})
```
""",
"delete_space_tag": """\
Deletes a specific tag previously assigned in a space. Example Call:
```python
delete_space_tag({
'space_id': 's12345',
'tag_name': 'Important',
'tag__name': 'Important',
'tag__tag_bg': '#ff0000',
'tag__tag_fg': '#ffffff'
})
```
""",
}And when we run the benchmark,
Benchmark after Flattened Schema + Improved System Prompt containing Schema Summary + (Function Names + Function Descriptions + Parameter Descriptions) Optimised + Function Call Examples Added [Code Here]

Sadly, the score seems to degrade!
Adding gpt function calling Example Parameter Values
Since the function call example for addition did not work, let’s now try adding sample values to the function parameters to provide a clearer idea of the values to input. We will adjust the descriptions of our function parameters accordingly.
schema_func_params_dict = {
'create_space': {
'features__due_dates__enabled': 'If due date feature is enabled within the space. \nExample: True, False \nDefault: True',
'features__due_dates__remap_closed_due_date': 'If remapping closed date feature in due dates is available within the space. \nExample: True, False \nDefault: False',
'features__due_dates__remap_due_dates': 'If remapping due date feature in due dates is available within the space. \nExample: True, False \nDefault: False',
'features__due_dates__start_date': 'If start date feature in due dates is available within the space. \nExample: True, False \nDefault: False',
'features__time_tracking__enabled': 'If time tracking feature is available within the space. \nExample: True, False \nDefault: True',
'multiple_assignees': 'Enable or disable multiple assignees for tasks within the space \nExample: True, False. Default: True',
'name': 'The name of the new space to create \nExample: \'NewWorkspace\', \'TempWorkspace\'',
'team_id': 'The ID of the team \nExample: \'abc123\', \'def456\' '
},
'create_space_tag': {
'space_id': 'The ID of the space \nExample: \'abc123\', \'def456\'',
'tag__name': 'The name of the tag to assign \nExample: \'NewTag\', \'TempTag\'',
'tag__tag_bg': 'The background color of the tag to assign \nExample: \'#FF0000\', \'#00FF00\'',
'tag__tag_fg': 'The foreground(text) color of the tag to assign \nExample: \'#FF0000\', \'#00FF00\''
},
'delete_space': {
'space_id': 'The ID of the space to delete \nExample: \'abc123\', \'def456\''
},
'delete_space_tag': {
'space_id': 'The ID of the space to delete \nExample: \'abc123\', \'def456\'',
'tag__name': 'The name of the tag to delete \nExample: \'NewTag\', \'TempTag\'',
'tag__tag_bg': 'The background color of the tag to delete \nExample: \'#FF0000\', \'#00FF00\', \'#0000FF\'',
'tag__tag_fg': 'The foreground color of the tag to delete \nExample: \'#FF0000\', \'#00FF00\', \'#0000FF\'',
'tag_name': 'The name of the tag to delete \nExample: \'NewTag\', \'TempTag\''
},
'get_space': {
'space_id': 'The ID of the space to retrieve details \nExample: \'abc123\', \'def456\''
},
'get_space_tags': {
'space_id': 'The ID of the space to retrieve all the tags from \nExample: \'abc123\', \'def456\''
},
'get_spaces': {
'archived': 'A flag to decide whether to include archived spaces or not \nExample: True, False. Default: True',
'team_id': 'The ID of the team \nExample: \'abc123\', \'def456\''
},
'update_space': {
'admin_can_manage': 'A flag to determine if the administrator can manage the space or not \nExample: True, False. Default: True',
'color': 'The color used for the space \nExample: \'#FF0000\', \'#00FF00\'',
'features__due_dates__enabled': 'If due date feature is enabled within the space. \nExample: True, False \nDefault: True',
'features__due_dates__remap_closed_due_date': 'If remapping closed date feature in due dates is available within the space. Default: False',
'features__due_dates__remap_due_dates': 'If remapping due date feature in due dates is available within the space. Default: False',
'features__due_dates__start_date': 'If start date feature in due dates is available within the space. Default: False',
'features__time_tracking__enabled': 'If time tracking feature is available within the space. \nExample: True, False \nDefault: True',
'multiple_assignees': 'Enable or disable multiple assignees for tasks within the space \nExample: True, False. Default: True',
'name': 'The new name of the space \nExample: \'NewWorkspace\', \'TempWorkspace\'',
'private': 'A flag to determine if the space is private or not \nExample: True, False. Default: False',
'space_id': 'The ID of the space to update \nExample: \'abc123\', \'def456\''
}
}And using these in the function schema, we get:
Flattened Schema + Improved System Prompt containing Schema Summary + (Function Names + Function Descriptions + Parameter Descriptions) Optimised + Function Call Examples Added + Adding Example Parameter Values [Code Here]

Wow! The intuition of adding example pays off.
Compiling the Results for GPT4 Function Calling Accuracy
To summarise all our examples, and their results:
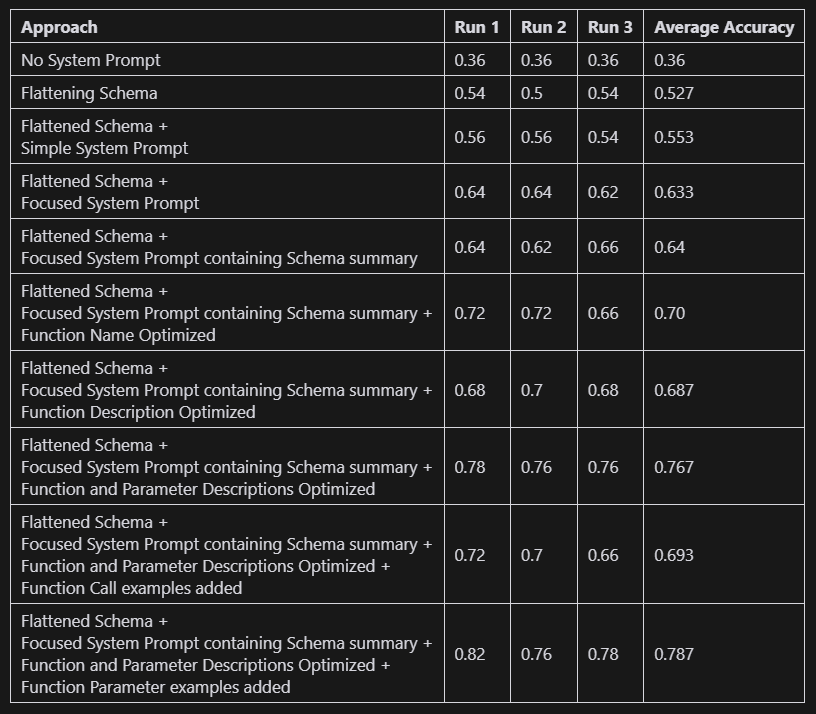
We experimented with strategies to improve the function calling ability of LLMs, specifically for Agentic Software integrations. Starting from a baseline score of 36%, we boosted performance to an average of 78%. The insights shared in this article aim to enhance your applications as well.
Moreover, we discovered a key distinction between general function calling and function calling for software integrations. In general function calls, even with multiple functions, they operate independently and non-linearly when executing an action. However, in software integrations, functions must follow a specific sequence to effectively accomplish an action.
Join our Discord Community and check out what we’re building!
All the codes of this articles are available here. Thank you!
Further Experiments & Challenges
We have been experimenting on this for a while and are planning to write further on
- Parallel Function calling accuracy
- Sequential Function Call Planning Accuracy (RAG + CoT)
- Comparison with Open Source Function Calling Models (OpenGorilla, Functionary, NexusRaven, and FireFunction)
When dealing with integration-centric function calls, the process can be complex. For instance, the agent may need to gather data from various endpoints like get_spaces_members, get_current_active_members, and get_member_whose_contract_is_over before responding with the update_member_list function.
This means there could be additional data not yet discussed in the conversation that requires the agent to fetch from other endpoints silently to formulate a complete response.
Optimisations like this are crucial aspect of our efforts at Composio to enhance the smoothness of Agentic integrations. If you are interested in improving accuracy of your agents connect with us at tech@composio.dev.
Co-Authors:
Subscribe if you are interested in learning more!
